Interactive Scene Authoring with Specialized Generative Primitives
作者: Clément Jambon, Changwoon Choi, Dongsu Zhang, Olga Sorkine-Hornung, Young Min Kim
分类: cs.CV, cs.GR
发布日期: 2024-12-20
💡 一句话要点
提出基于生成原语的交互式场景创作框架,简化非专业用户3D场景设计。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D场景创作 生成原语 交互式设计 生成细胞自动机 3D高斯溅射
📋 核心要点
- 现有3D资产生成工具复杂,需要专业知识,非专业用户难以创作高质量3D场景。
- 提出专用生成原语框架,通过单样本学习和可控生成,简化3D场景创作流程。
- 实验表明,该方法能快速从真实场景提取原语,并交互式地创作3D资产和场景。
📝 摘要(中文)
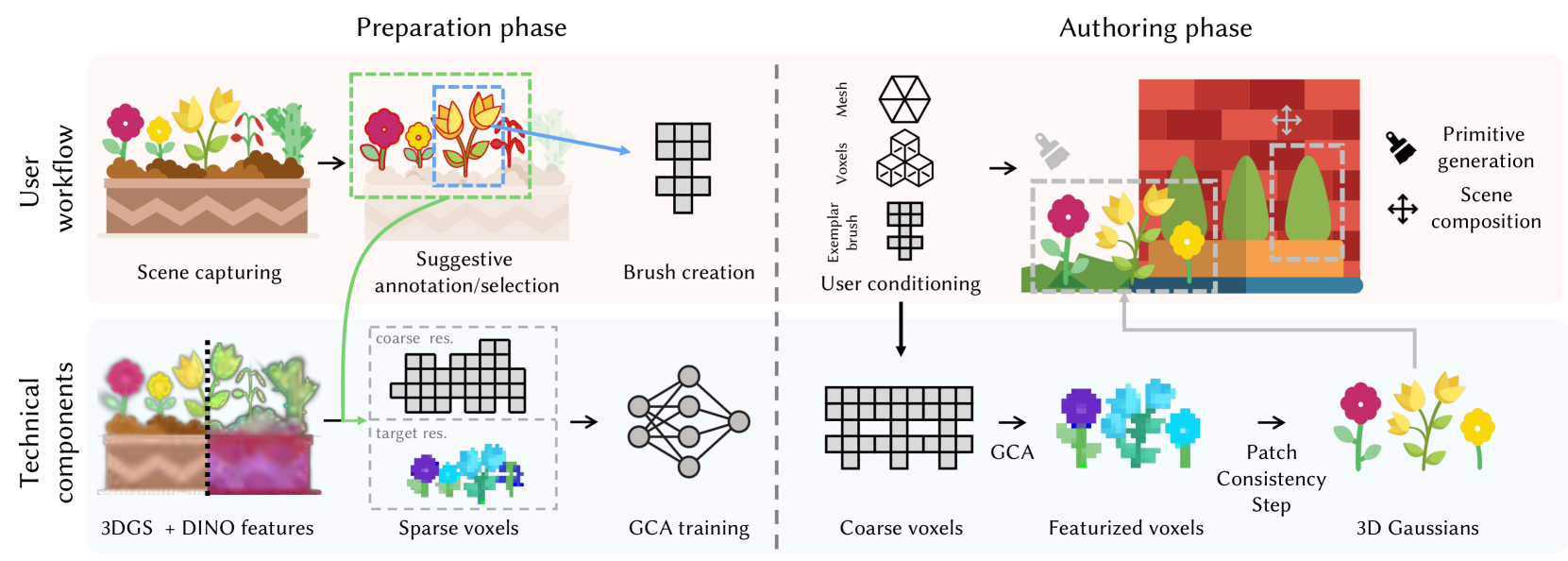
本文提出了一种名为“专用生成原语”的生成框架,旨在让非专业用户能够以无缝、轻量且可控的方式创作高质量的3D场景。每个原语都是一个高效的生成模型,捕捉了真实世界中单个样本的分布。该框架首先将用户拍摄的环境视频通过3D高斯溅射转化为高质量的显式外观模型。然后,用户在语义感知特征的引导下选择感兴趣的区域。为了创建生成原语,本文改进了生成细胞自动机,使其适用于单样本训练和可控生成。通过在稀疏体素上操作,将生成任务与外观模型解耦,并通过后续的稀疏块一致性步骤恢复高质量的输出。每个原语都可以在10分钟内完成训练,并以完全组合的方式交互式地创作新场景。实验展示了从真实场景中提取各种原语并进行控制,在几分钟内创建3D资产和场景的交互式过程。此外,还展示了原语的其他功能:处理各种3D表示以控制生成、传递外观和编辑几何体。
🔬 方法详解
问题定义:现有3D场景创作工具通常需要用户具备专业的3D建模知识和复杂软件的操作技能,这对于非专业用户来说是一个巨大的门槛。现有的生成模型虽然可以生成3D内容,但往往缺乏对生成过程的精细控制,难以满足用户特定的创作需求。因此,如何降低3D场景创作的门槛,让非专业用户也能轻松创建高质量的3D场景是一个重要的研究问题。
核心思路:本文的核心思路是利用“专用生成原语”,将复杂的3D场景分解为一系列可控的、可重用的基本元素。每个原语都代表了真实世界中的一个特定对象或区域,例如一棵树、一扇窗户或一段墙壁。通过学习单个样本的分布,生成原语能够高效地捕捉对象的特征,并允许用户通过简单的交互操作来控制生成过程。这种方法将复杂的3D场景创作过程简化为对少量原语的组合和调整,从而降低了创作难度。
技术框架:该框架主要包含以下几个阶段:1) 场景捕获与重建:用户通过视频捕捉真实环境,利用3D高斯溅射技术重建高质量的3D场景,并生成显式的外观模型。2) 区域选择:用户在语义感知特征的引导下,选择感兴趣的区域作为生成原语的候选对象。3) 原语训练:针对每个选定的区域,利用改进的生成细胞自动机进行单样本训练,生成可控的生成原语。4) 场景创作:用户通过交互式操作,组合和调整生成的原语,创作新的3D场景。
关键创新:本文的关键创新在于将生成细胞自动机应用于单样本训练,并将其与3D高斯溅射技术相结合,实现了一种高效、可控的3D场景创作框架。与传统的生成模型相比,该方法不需要大量的训练数据,只需要单个样本即可生成高质量的3D对象。此外,通过将生成任务与外观模型解耦,该方法能够灵活地处理各种3D表示,并支持外观传递和几何编辑等功能。
关键设计:在生成细胞自动机的训练过程中,作者设计了一种特殊的损失函数,用于约束生成结果与原始样本之间的相似性。此外,为了提高生成结果的质量,作者还引入了一种稀疏块一致性步骤,用于消除生成过程中的伪影和噪声。具体的参数设置和网络结构在论文中有详细描述,但摘要中未明确给出。
🖼️ 关键图片


📊 实验亮点
该方法能够在10分钟内完成单个原语的训练,并支持交互式的场景创作。实验结果表明,该方法能够从真实场景中提取各种原语,并在几分钟内创建出高质量的3D资产和场景。此外,该方法还支持处理各种3D表示,并支持外观传递和几何编辑等功能,具有很强的灵活性和可扩展性。
🎯 应用场景
该研究成果可广泛应用于游戏开发、虚拟现实、建筑设计、室内设计等领域。非专业用户可以利用该框架快速创建高质量的3D场景,降低内容创作的门槛,提高创作效率。未来,该技术有望进一步发展,实现更加智能化的3D场景创作,例如自动生成场景布局、自动调整对象比例等。
📄 摘要(原文)
Generating high-quality 3D digital assets often requires expert knowledge of complex design tools. We introduce Specialized Generative Primitives, a generative framework that allows non-expert users to author high-quality 3D scenes in a seamless, lightweight, and controllable manner. Each primitive is an efficient generative model that captures the distribution of a single exemplar from the real world. With our framework, users capture a video of an environment, which we turn into a high-quality and explicit appearance model thanks to 3D Gaussian Splatting. Users then select regions of interest guided by semantically-aware features. To create a generative primitive, we adapt Generative Cellular Automata to single-exemplar training and controllable generation. We decouple the generative task from the appearance model by operating on sparse voxels and we recover a high-quality output with a subsequent sparse patch consistency step. Each primitive can be trained within 10 minutes and used to author new scenes interactively in a fully compositional manner. We showcase interactive sessions where various primitives are extracted from real-world scenes and controlled to create 3D assets and scenes in a few minutes. We also demonstrate additional capabilities of our primitives: handling various 3D representations to control generation, transferring appearances, and editing geometries.