HoVLE: Unleashing the Power of Monolithic Vision-Language Models with Holistic Vision-Language Embedding
作者: Chenxin Tao, Shiqian Su, Xizhou Zhu, Chenyu Zhang, Zhe Chen, Jiawen Liu, Wenhai Wang, Lewei Lu, Gao Huang, Yu Qiao, Jifeng Dai
分类: cs.CV
发布日期: 2024-12-20 (更新: 2025-02-09)
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
HoVLE:通过整体视觉-语言嵌入释放单体视觉-语言模型的潜力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 单体模型 整体嵌入 多阶段训练 特征蒸馏
📋 核心要点
- 现有单体视觉-语言模型依赖微调预训练LLM以获得视觉能力,可能损害其原有的语言能力。
- HoVLE提出一种整体嵌入模块,将视觉和文本输入转换到共享空间,使LLM能统一处理。
- HoVLE采用多阶段训练策略,包括特征蒸馏、多模态对齐和指令调优,提升模型性能。
📝 摘要(中文)
大型语言模型(LLMs)的快速发展推动了视觉-语言模型(VLMs)的进步。单体VLMs避免了模态特定的编码器,为组合式模型提供了一种有前景的替代方案,但面临着性能较差的挑战。现有的大多数单体VLMs需要调整预训练的LLMs以获得视觉能力,这可能会降低其语言能力。为了解决这个难题,本文提出了一种名为HoVLE的新型高性能单体VLM。我们注意到,当图像嵌入与文本嵌入对齐时,LLMs能够解释图像。当前单体VLMs的挑战实际上在于缺乏用于视觉和语言输入的整体嵌入模块。因此,HoVLE引入了一个整体嵌入模块,将视觉和文本输入转换为共享空间,使LLMs能够以与文本相同的方式处理图像。此外,精心设计了一个多阶段训练策略来增强整体嵌入模块。首先,训练它从预训练的视觉编码器中提取视觉特征,并从LLM中提取文本嵌入,从而能够使用不成对的随机图像和文本token进行大规模训练。整个模型进一步在多模态数据上进行下一个token预测,以对齐嵌入。最后,加入指令调优阶段。实验表明,HoVLE在各种基准测试中取得了接近领先的组合式模型的性能,大大优于以前的单体模型。
🔬 方法详解
问题定义:现有单体视觉-语言模型(VLMs)的性能不如组合式模型,并且微调预训练大型语言模型(LLMs)以获得视觉能力可能会降低其原有的语言能力。因此,需要一种能够在不损害LLM语言能力的前提下,有效提升单体VLM性能的方法。
核心思路:论文的核心思路是设计一个整体嵌入模块,将视觉和文本输入映射到共享的嵌入空间。这样,LLM就可以像处理文本一样处理图像,从而避免了对LLM进行大规模微调以适应视觉模态的需求。这种方法旨在利用LLM强大的语言能力,同时赋予其有效的视觉理解能力。
技术框架:HoVLE的整体框架包括三个主要阶段:1) 整体嵌入模块训练:该模块旨在将视觉和文本输入映射到共享的嵌入空间。它通过从预训练的视觉编码器和LLM中蒸馏特征来实现。2) 多模态对齐:在共享嵌入空间中,模型通过下一个token预测任务来对齐视觉和文本嵌入。这使得模型能够理解视觉和文本之间的关系。3) 指令调优:最后,模型在指令数据上进行微调,以提高其遵循指令的能力。
关键创新:HoVLE的关键创新在于其整体嵌入模块的设计和多阶段训练策略。整体嵌入模块能够有效地将视觉和文本信息融合到共享空间,避免了对LLM进行大规模微调的需求。多阶段训练策略则保证了嵌入模块能够有效地学习视觉和文本特征,并实现模态之间的对齐。
关键设计:在整体嵌入模块的训练阶段,使用了不成对的随机图像和文本token进行大规模训练,这有助于模型学习更鲁棒的视觉和文本特征。在多模态对齐阶段,使用了下一个token预测任务,并设计了相应的损失函数来促进视觉和文本嵌入的对齐。指令调优阶段则使用了标准的技术,例如LoRA等。
🖼️ 关键图片
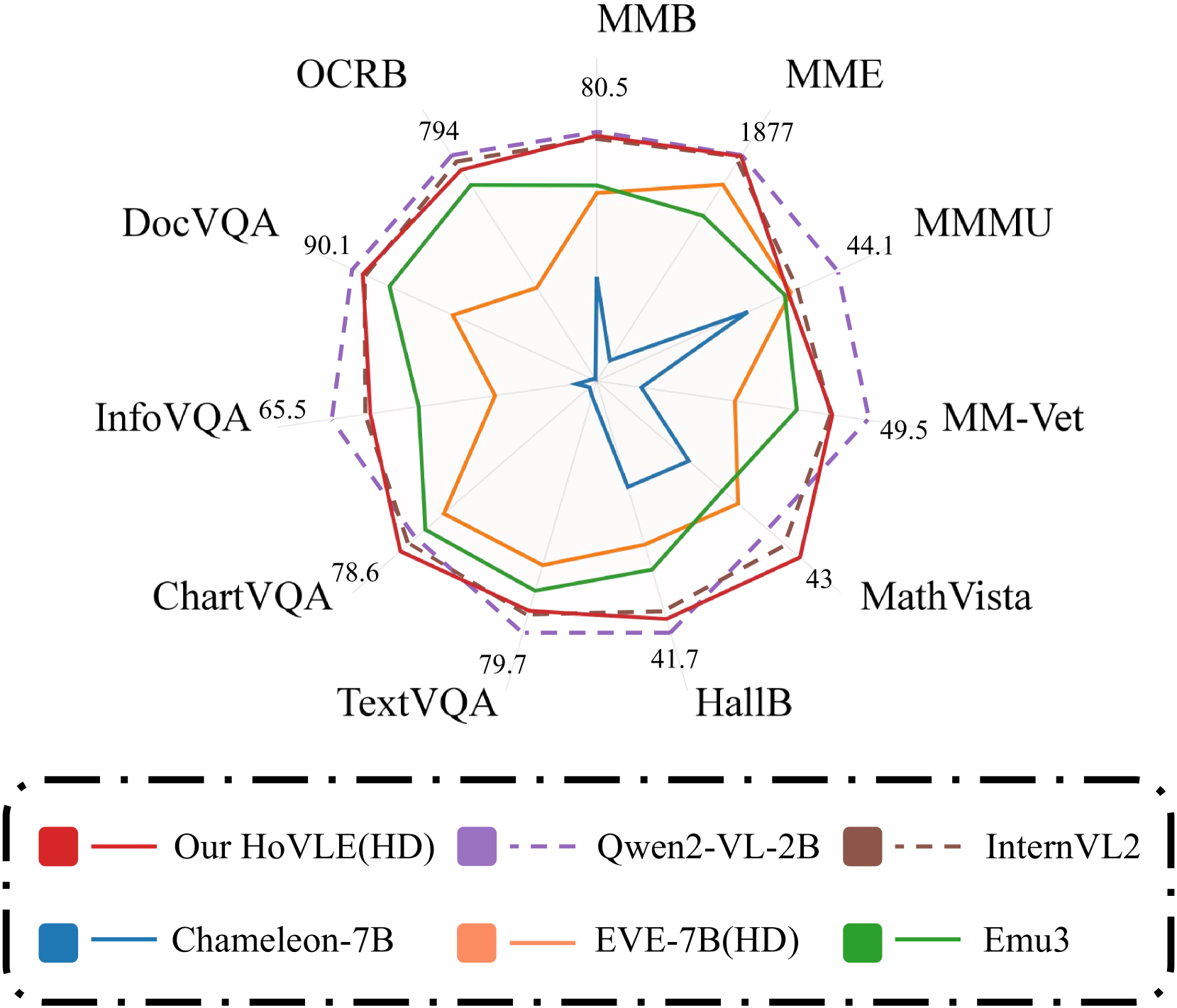
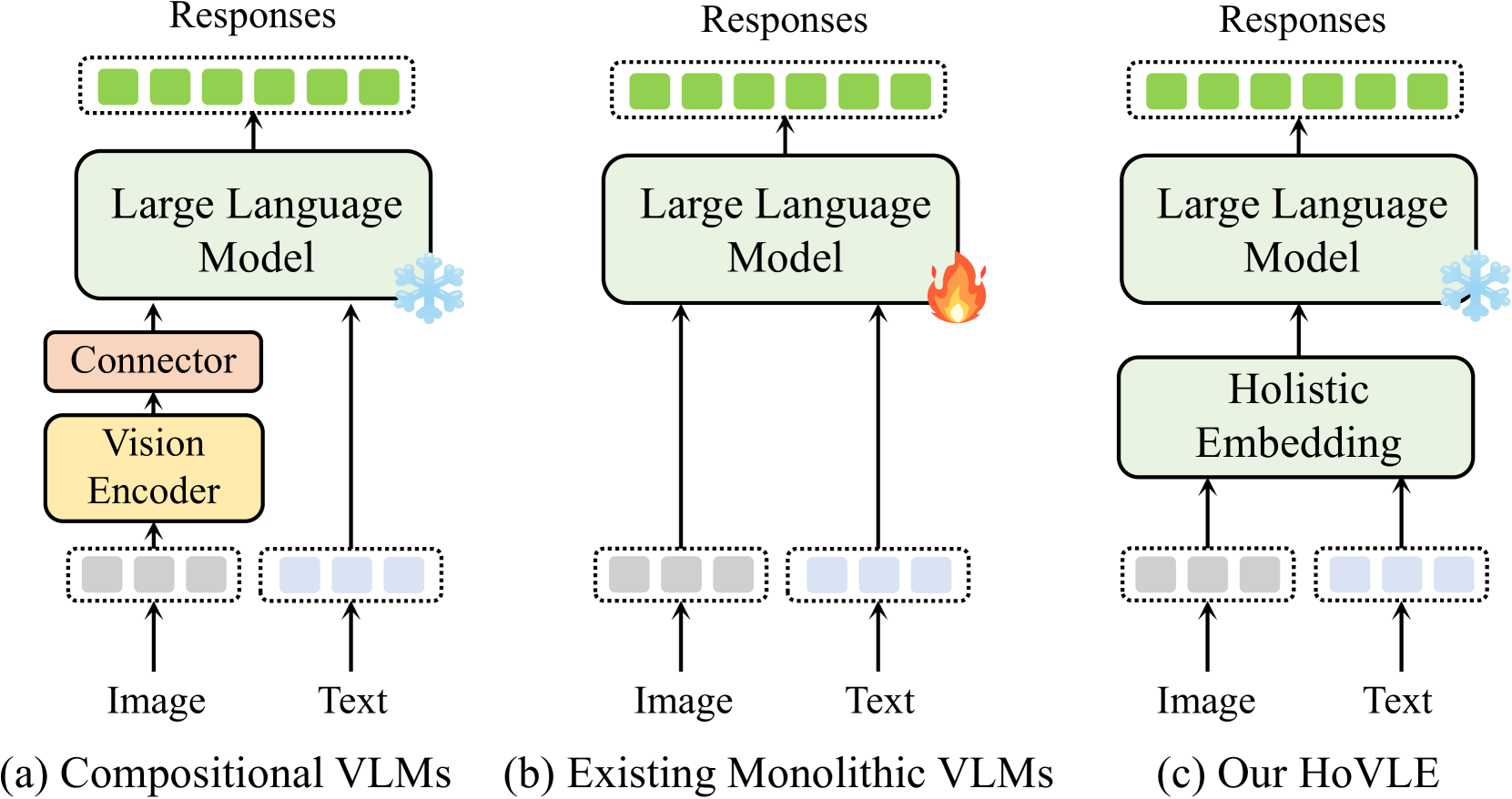
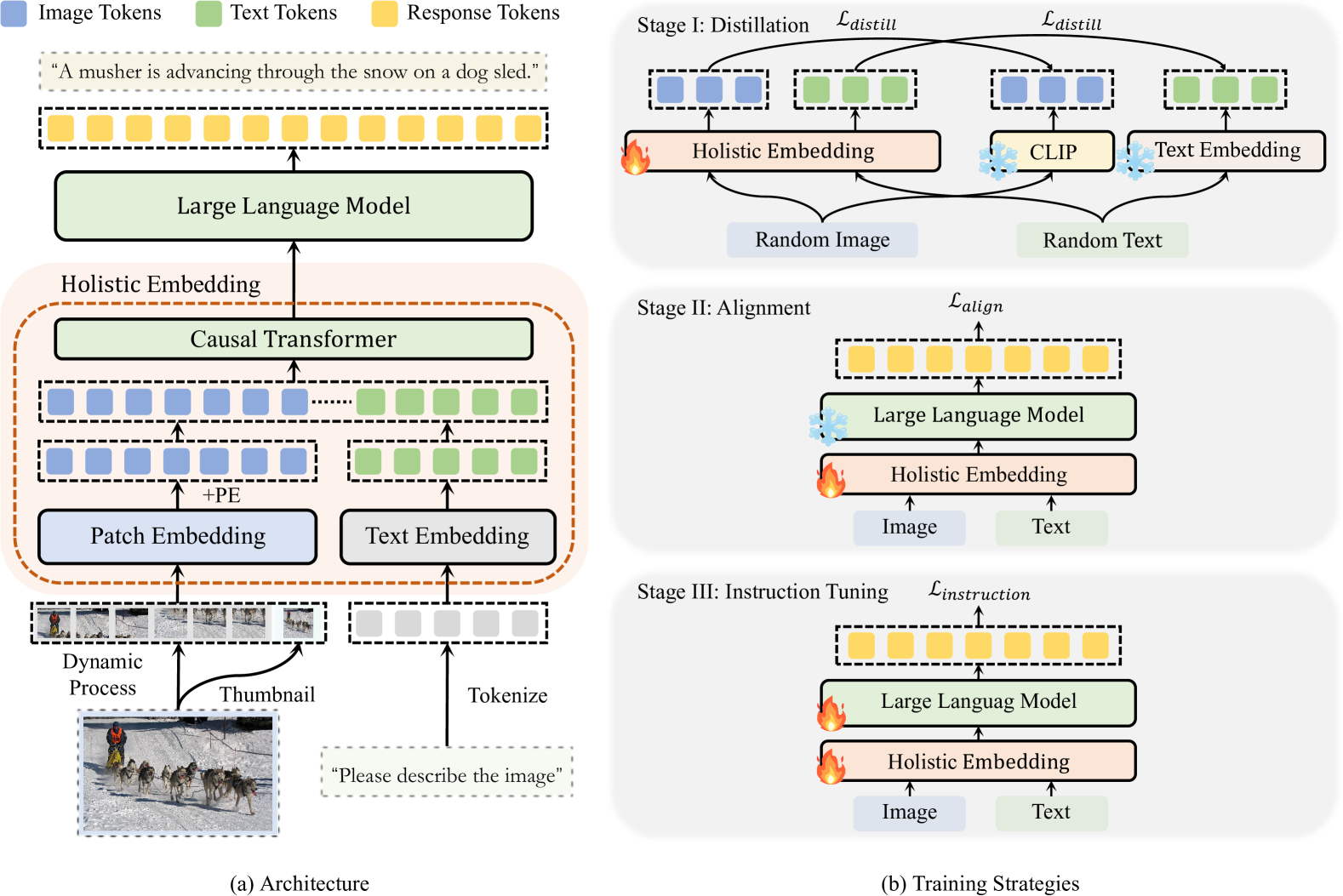
📊 实验亮点
HoVLE在多个视觉-语言基准测试中取得了显著的性能提升,接近领先的组合式模型,并大幅超越了之前的单体模型。具体数据需要在论文中查找。该模型在不损害LLM语言能力的前提下,有效提升了视觉理解能力,证明了整体嵌入方法的有效性。
🎯 应用场景
HoVLE具有广泛的应用前景,包括图像描述生成、视觉问答、多模态对话等。它可以应用于智能客服、教育、医疗等领域,提升人机交互的效率和质量。未来,HoVLE有望成为构建更智能、更通用的多模态人工智能系统的关键组成部分。
📄 摘要(原文)
The rapid advance of Large Language Models (LLMs) has catalyzed the development of Vision-Language Models (VLMs). Monolithic VLMs, which avoid modality-specific encoders, offer a promising alternative to the compositional ones but face the challenge of inferior performance. Most existing monolithic VLMs require tuning pre-trained LLMs to acquire vision abilities, which may degrade their language capabilities. To address this dilemma, this paper presents a novel high-performance monolithic VLM named HoVLE. We note that LLMs have been shown capable of interpreting images, when image embeddings are aligned with text embeddings. The challenge for current monolithic VLMs actually lies in the lack of a holistic embedding module for both vision and language inputs. Therefore, HoVLE introduces a holistic embedding module that converts visual and textual inputs into a shared space, allowing LLMs to process images in the same way as texts. Furthermore, a multi-stage training strategy is carefully designed to empower the holistic embedding module. It is first trained to distill visual features from a pre-trained vision encoder and text embeddings from the LLM, enabling large-scale training with unpaired random images and text tokens. The whole model further undergoes next-token prediction on multi-modal data to align the embeddings. Finally, an instruction-tuning stage is incorporated. Our experiments show that HoVLE achieves performance close to leading compositional models on various benchmarks, outperforming previous monolithic models by a large margin. Model available at https://huggingface.co/OpenGVLab/HoVLE.