MotiF: Making Text Count in Image Animation with Motion Focal Loss
作者: Shijie Wang, Samaneh Azadi, Rohit Girdhar, Saketh Rambhatla, Chen Sun, Xi Yin
分类: cs.CV, cs.AI
发布日期: 2024-12-20 (更新: 2025-03-23)
备注: Accepted by CVPR 2025. Project page: https://wang-sj16.github.io/motif/
期刊: The IEEE/CVF Conference on Computer Vision and Pattern Recognition 2025
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
MotiF:通过运动焦点损失改进文本引导的图像动画生成
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱四:生成式动作 (Generative Motion)
关键词: 文本图像到视频生成 图像动画 运动焦点损失 光流估计 文本对齐
📋 核心要点
- 现有文本引导图像动画生成方法难以生成与文本提示对齐的视频,尤其是在运动描述方面。
- MotiF的核心思想是利用光流估计运动热图,并将其作为损失函数的权重,引导模型关注运动区域。
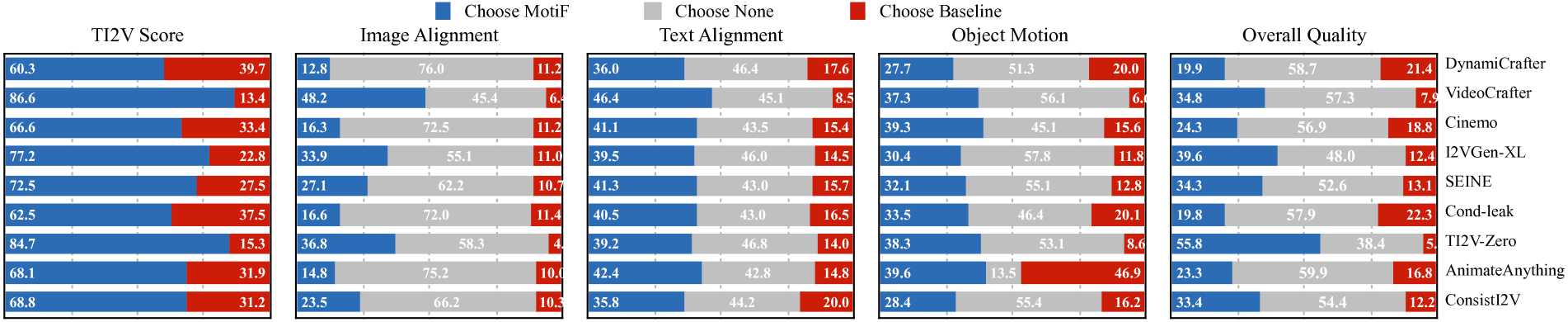
- 实验表明,MotiF在TI2V Bench数据集上显著优于现有方法,平均偏好度达到72%。
📝 摘要(中文)
本文提出了一种名为MotiF的简单而有效的方法,用于解决文本-图像到视频(TI2V)生成中,视频与文本提示对齐不佳的问题,尤其是在指定运动的情况下。MotiF通过引导模型学习更多运动的区域来改进文本对齐和运动生成。该方法利用光流生成运动热图,并根据运动强度对损失进行加权。这种改进的目标函数能够显著提升性能,并能与现有的使用运动先验作为模型输入的方法互补。此外,由于缺乏多样化的TI2V生成评估基准,本文提出了TI2V Bench,一个包含320个图像-文本对的数据集,用于鲁棒评估。通过在TI2V Bench上的综合评估,MotiF优于九个开源模型,平均偏好度达到72%。TI2V Bench和更多结果已在https://wang-sj16.github.io/motif/上发布。
🔬 方法详解
问题定义:本文旨在解决文本-图像到视频(TI2V)生成任务中,生成的视频与给定的文本描述在运动方面对齐不佳的问题。现有方法通常难以准确地将文本描述的运动信息融入到生成的视频中,导致生成的视频缺乏真实感和可控性。
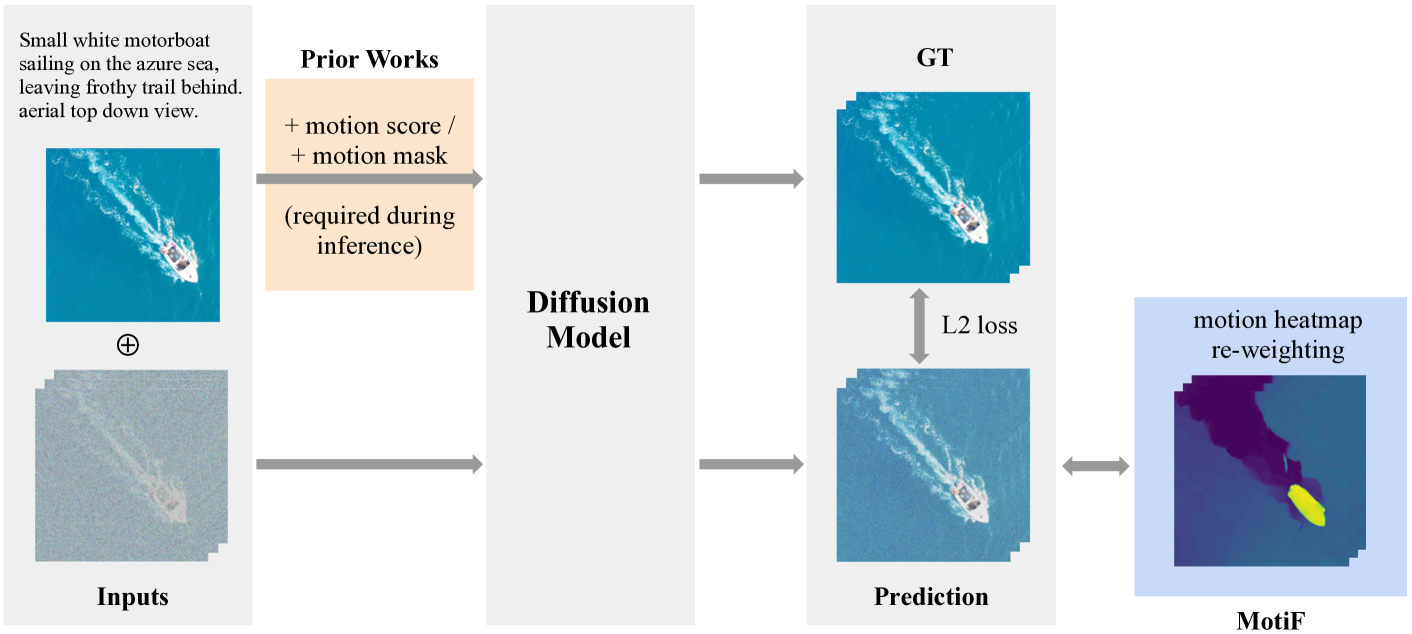
核心思路:MotiF的核心思路是让模型更加关注图像中运动明显的区域,从而更好地理解和生成与文本描述相符的运动。通过引入运动焦点损失,模型在训练过程中会更加重视运动区域的像素,从而提高生成视频的运动质量和文本对齐度。
技术框架:MotiF方法主要包含以下几个步骤:1) 使用预训练的光流估计模型计算输入图像序列的运动热图。2) 将运动热图作为权重,加权到视频生成模型的损失函数中。3) 使用加权后的损失函数训练视频生成模型。整体框架简单有效,易于集成到现有的TI2V生成模型中。
关键创新:MotiF的关键创新在于提出了运动焦点损失,它能够根据图像中的运动强度动态地调整损失权重,从而引导模型更加关注运动区域。与现有方法相比,MotiF不需要修改模型结构或引入额外的运动先验,而是通过修改损失函数来实现运动信息的有效利用。
关键设计:MotiF的关键设计包括:1) 使用预训练的光流估计模型(例如RAFT)生成运动热图。2) 将运动热图进行归一化处理,使其值在0到1之间。3) 将归一化后的运动热图作为权重,乘以视频生成模型的像素级损失函数(例如L1损失或L2损失)。4) 可以与其他损失函数(例如对抗损失)结合使用,以进一步提高生成视频的质量。
🖼️ 关键图片

📊 实验亮点
MotiF在TI2V Bench数据集上进行了全面的评估,并与九个开源模型进行了比较。实验结果表明,MotiF显著优于现有方法,平均偏好度达到72%。这表明MotiF能够生成更符合文本描述的、运动更加自然的视频。此外,MotiF的简单性和有效性使其易于集成到现有的TI2V生成模型中。
🎯 应用场景
MotiF技术可应用于视频内容创作、游戏开发、电影特效等领域。例如,用户可以通过文本描述控制图像中物体的运动,生成个性化的动画视频。该技术还可以用于增强现实和虚拟现实应用,提升用户体验。未来,该技术有望在教育、娱乐和工业等领域发挥更大的作用。
📄 摘要(原文)
Text-Image-to-Video (TI2V) generation aims to generate a video from an image following a text description, which is also referred to as text-guided image animation. Most existing methods struggle to generate videos that align well with the text prompts, particularly when motion is specified. To overcome this limitation, we introduce MotiF, a simple yet effective approach that directs the model's learning to the regions with more motion, thereby improving the text alignment and motion generation. We use optical flow to generate a motion heatmap and weight the loss according to the intensity of the motion. This modified objective leads to noticeable improvements and complements existing methods that utilize motion priors as model inputs. Additionally, due to the lack of a diverse benchmark for evaluating TI2V generation, we propose TI2V Bench, a dataset consists of 320 image-text pairs for robust evaluation. We present a human evaluation protocol that asks the annotators to select an overall preference between two videos followed by their justifications. Through a comprehensive evaluation on TI2V Bench, MotiF outperforms nine open-sourced models, achieving an average preference of 72%. The TI2V Bench and additional results are released in https://wang-sj16.github.io/motif/.