Mamba2D: A Natively Multi-Dimensional State-Space Model for Vision Tasks
作者: Enis Baty, Alejandro Hernández Díaz, Chris Bridges, Rebecca Davidson, Steve Eckersley, Simon Hadfield
分类: cs.CV
发布日期: 2024-12-20 (更新: 2025-01-17)
🔗 代码/项目: GITHUB
💡 一句话要点
Mamba2D:提出原生多维状态空间模型,用于视觉任务。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 状态空间模型 二维建模 视觉任务 图像分类 空间依赖性 深度学习 Mamba 图像处理
📋 核心要点
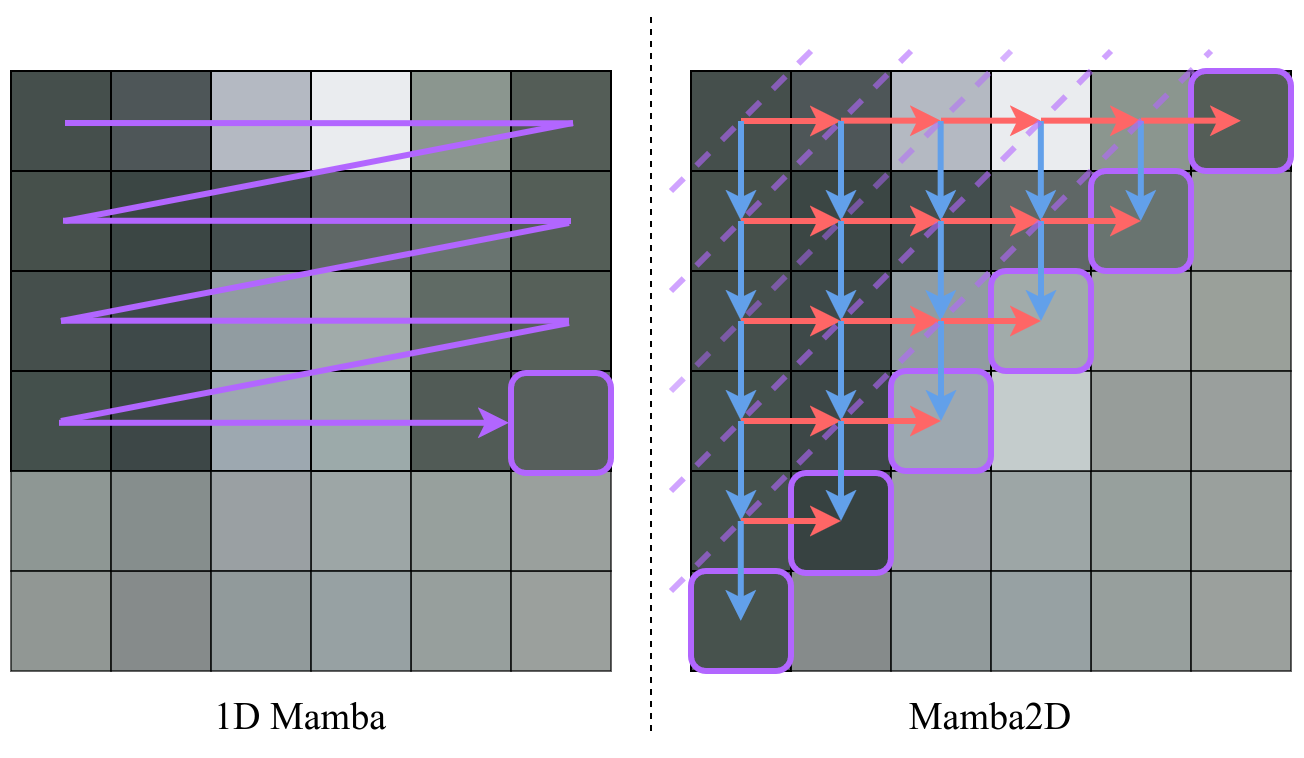
- 现有方法将一维状态空间模型应用于二维图像数据时,依赖于一维扫描方向的组合,无法有效捕捉图像的空间依赖性。
- Mamba2D提出了一种原生的二维状态空间模型,通过单一的二维扫描方向,同时考虑图像的两个维度,从而更好地建模空间依赖性。
- 在ImageNet-1K图像分类任务上,Mamba2D取得了与现有基于状态空间模型的视觉任务方法相当的性能。
📝 摘要(中文)
状态空间模型(SSM)最近作为一种强大而高效的架构,成为了Transformer架构的替代方案。然而,现有的SSM概念化仍然保留着源于自然语言处理的固有偏见,这限制了它们对视觉输入中空间依赖特性的建模能力。本文通过从原生多维公式重新推导现代选择性状态空间技术来解决这些限制。目前,先前的工作试图通过依赖于1D扫描方向的任意组合来捕获空间依赖性,从而将原生1D SSM应用于2D数据(即图像)。相比之下,Mamba2D通过单一的2D扫描方向改进了这一点,该方向原生考虑了输入的两个维度,从而在构建隐藏状态时有效地建模了空间依赖性。在标准的ImageNet-1K数据集的图像分类评估中,Mamba2D显示出与先前SSM在视觉任务上的适配相当的性能。源代码可在https://github.com/cocoalex00/Mamba2D 获得。
🔬 方法详解
问题定义:现有方法在处理视觉任务时,通常将一维的状态空间模型应用于二维图像数据。这些方法依赖于对图像进行一维扫描,然后组合多个一维扫描的结果来近似二维空间关系。这种做法无法原生捕捉图像固有的二维空间依赖性,导致建模能力受限。现有方法的痛点在于无法充分利用图像的空间信息,影响了模型的性能。
核心思路:Mamba2D的核心思路是从原生多维的角度重新设计状态空间模型,使其能够直接处理二维图像数据。通过引入二维扫描机制,模型可以同时考虑图像的两个维度,从而更好地捕捉空间依赖性。这种设计避免了将二维数据降维到一维处理所带来的信息损失,提高了模型的表达能力。
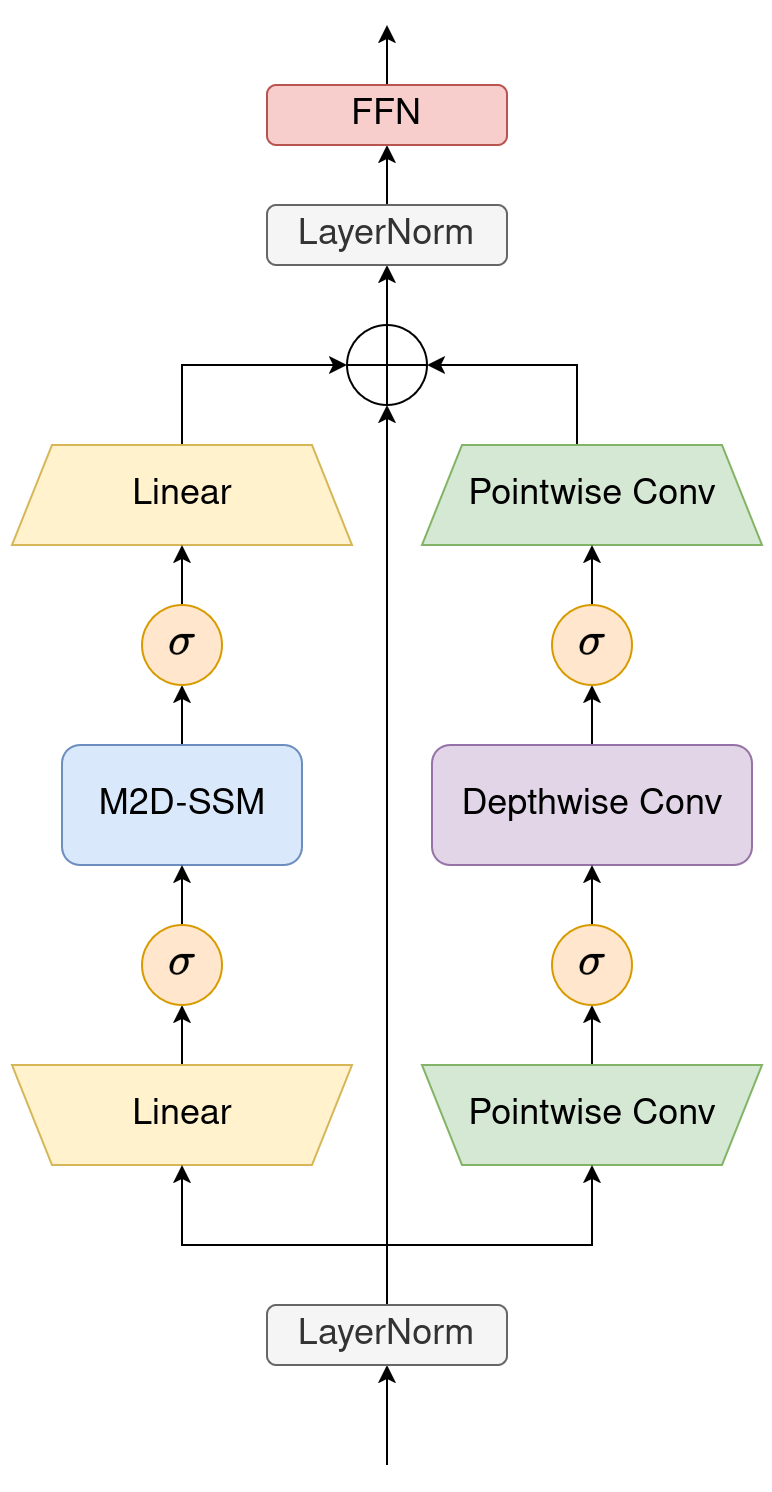
技术框架:Mamba2D的整体架构基于状态空间模型,但关键在于其二维扫描机制。模型首先接收二维图像作为输入,然后通过二维扫描操作构建隐藏状态。在扫描过程中,模型会根据输入数据动态地选择性地更新隐藏状态,从而捕捉空间依赖性。最终,模型利用隐藏状态进行图像分类等任务。
关键创新:Mamba2D最重要的技术创新点在于其原生的二维状态空间建模方法。与现有方法不同,Mamba2D直接在二维空间中进行状态更新和信息传递,避免了降维操作带来的信息损失。这种二维建模方法能够更准确地捕捉图像的空间结构,从而提高模型的性能。
关键设计:Mamba2D的关键设计包括二维扫描方向的选择、选择性状态更新机制以及隐藏状态的维度设置。二维扫描方向决定了模型如何遍历图像,不同的扫描方向可能会影响模型的性能。选择性状态更新机制允许模型根据输入数据动态地调整隐藏状态,从而提高模型的适应性。隐藏状态的维度则决定了模型的表达能力,需要根据具体任务进行调整。
🖼️ 关键图片

📊 实验亮点
Mamba2D在ImageNet-1K图像分类任务上取得了与现有基于状态空间模型的视觉任务方法相当的性能。虽然论文中没有明确给出具体的性能数据和提升幅度,但结果表明Mamba2D在建模空间依赖性方面具有优势,并且能够有效地应用于视觉任务。未来的工作可以进一步优化Mamba2D的性能,并将其应用于更复杂的视觉任务中。
🎯 应用场景
Mamba2D具有广泛的应用前景,可以应用于图像分类、目标检测、图像分割等各种视觉任务。该模型能够更好地捕捉图像的空间依赖性,有望在这些任务中取得更好的性能。此外,Mamba2D还可以应用于医学图像分析、遥感图像处理等领域,为这些领域的研究提供新的思路和方法。未来,Mamba2D有望成为一种通用的视觉模型,为各种视觉应用提供强大的支持。
📄 摘要(原文)
State-Space Models (SSMs) have recently emerged as a powerful and efficient alternative to the long-standing transformer architecture. However, existing SSM conceptualizations retain deeply rooted biases from their roots in natural language processing. This constrains their ability to appropriately model the spatially-dependent characteristics of visual inputs. In this paper, we address these limitations by re-deriving modern selective state-space techniques, starting from a natively multidimensional formulation. Currently, prior works attempt to apply natively 1D SSMs to 2D data (i.e. images) by relying on arbitrary combinations of 1D scan directions to capture spatial dependencies. In contrast, Mamba2D improves upon this with a single 2D scan direction that factors in both dimensions of the input natively, effectively modelling spatial dependencies when constructing hidden states. Mamba2D shows comparable performance to prior adaptations of SSMs for vision tasks, on standard image classification evaluations with the ImageNet-1K dataset. Source code is available at https://github.com/cocoalex00/Mamba2D.