Learning Visual Composition through Improved Semantic Guidance
作者: Austin Stone, Hagen Soltau, Robert Geirhos, Xi Yi, Ye Xia, Bingyi Cao, Kaifeng Chen, Abhijit Ogale, Jonathon Shlens
分类: cs.CV, cs.AI, cs.CL, cs.IR
发布日期: 2024-12-19 (更新: 2025-04-04)
💡 一句话要点
通过改进语义指导提升视觉组合学习能力,显著增强CLIP模型性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视觉组合学习 对比学习 图像描述 CLIP模型 弱监督学习
📋 核心要点
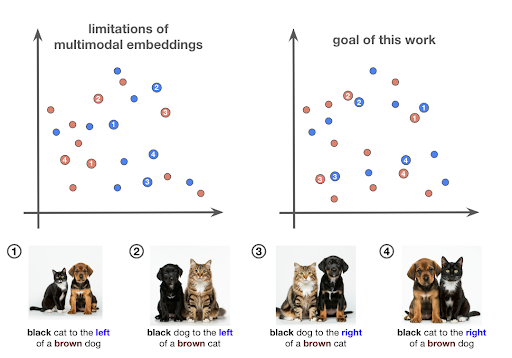
- 现有视觉表征学习方法在理解对象交互和组合方面存在不足,导致模型将图像视为简单的词袋。
- 通过改进弱标签数据(图像描述),提升对比学习方法在视觉组合学习任务中的性能,无需复杂的定制架构。
- 实验结果表明,使用增强数据训练的CLIP模型在组合学习和图像检索任务上均取得了显著提升,超越了现有方法。
📝 摘要(中文)
视觉图像并非孤立对象的集合,而是多种概念的组合。虽然视觉表征学习取得了显著进展,但这些进展主要集中在为少量离散对象构建更好的表征,而忽略了对这些对象之间交互的理解。通过图像描述或对比学习获得的表征通常将图像视为词袋。一些工作试图通过定制学习架构来解决组合学习的不足。本文侧重于简单且可扩展的方法。特别地,我们证明通过大幅改进弱标签数据(即图像描述),可以显著提高标准对比学习方法的性能。之前的CLIP模型在具有挑战性的组合学习任务上表现接近随机水平。然而,我们的简单方法显著提升了CLIP的性能,并超越了所有定制架构。此外,我们在一个源自DOCCI的相对较新的图像描述基准上展示了我们的结果。通过一系列消融实验,我们证明了使用增强数据训练的标准CLIP模型可以在图像检索任务上表现出令人印象深刻的性能。
🔬 方法详解
问题定义:现有视觉表征学习方法,如基于图像描述或对比学习的方法,难以有效捕捉图像中对象之间的交互和组合关系,导致模型在理解复杂场景时表现不佳。现有方法通常将图像视为独立的对象的集合,忽略了对象间的语义联系,限制了模型在组合学习任务上的性能。
核心思路:该论文的核心思路是通过改进弱标签数据(图像描述)的质量,从而提升标准对比学习模型(如CLIP)在视觉组合学习任务中的性能。作者认为,高质量的图像描述能够提供更丰富的语义信息,帮助模型更好地理解图像中对象之间的关系和组合方式。
技术框架:该方法主要基于标准的CLIP模型,并对其训练数据进行改进。具体流程包括:1) 收集图像及其对应的弱标签描述;2) 使用某种策略(具体策略未知)对弱标签描述进行增强,提高其质量和信息量;3) 使用增强后的图像描述数据训练CLIP模型;4) 在组合学习和图像检索等任务上评估模型的性能。
关键创新:该论文的关键创新在于证明了通过简单地改进训练数据(图像描述),就可以显著提升标准对比学习模型在视觉组合学习任务中的性能,而无需设计复杂的定制架构。这表明数据质量在视觉表征学习中起着至关重要的作用。
关键设计:论文中没有详细说明图像描述增强的具体方法,这部分信息未知。但是,可以推测可能涉及以下技术细节:1) 使用自然语言处理技术对图像描述进行改写、扩充或修正,使其更加准确、详细和具有语义信息;2) 设计特定的损失函数,鼓励模型学习图像中对象之间的关系和组合方式;3) 探索不同的数据增强策略,例如随机替换、插入或删除图像描述中的词语,以提高模型的鲁棒性。
🖼️ 关键图片


📊 实验亮点
该研究表明,通过改进弱标签数据,可以显著提升CLIP模型在组合学习任务上的性能,超越了所有定制架构。具体性能数据和对比基线未知,但论文强调了性能的显著提升。该方法在源自DOCCI的图像描述基准上取得了令人印象深刻的结果,证明了其有效性。
🎯 应用场景
该研究成果可应用于图像检索、图像描述生成、视觉问答等领域。通过提升模型对图像中对象组合关系的理解,可以提高这些应用在处理复杂场景时的准确性和可靠性。未来,该方法有望应用于自动驾驶、机器人导航等需要理解复杂视觉环境的领域。
📄 摘要(原文)
Visual imagery does not consist of solitary objects, but instead reflects the composition of a multitude of fluid concepts. While there have been great advances in visual representation learning, such advances have focused on building better representations for a small number of discrete objects bereft of an understanding of how these objects are interacting. One can observe this limitation in representations learned through captions or contrastive learning -- where the learned model treats an image essentially as a bag of words. Several works have attempted to address this limitation through the development of bespoke learned architectures to directly address the shortcomings in compositional learning. In this work, we focus on simple, and scalable approaches. In particular, we demonstrate that by substantially improving weakly labeled data, i.e. captions, we can vastly improve the performance of standard contrastive learning approaches. Previous CLIP models achieved near chance rate on challenging tasks probing compositional learning. However, our simple approach boosts performance of CLIP substantially and surpasses all bespoke architectures. Furthermore, we showcase our results on a relatively new captioning benchmark derived from DOCCI. We demonstrate through a series of ablations that a standard CLIP model trained with enhanced data may demonstrate impressive performance on image retrieval tasks.