OnlineVPO: Align Video Diffusion Model with Online Video-Centric Preference Optimization
作者: Jiacheng Zhang, Jie Wu, Weifeng Chen, Yatai Ji, Xuefeng Xiao, Weilin Huang, Kai Han
分类: cs.CV
发布日期: 2024-12-19 (更新: 2025-12-31)
💡 一句话要点
OnlineVPO:通过在线视频偏好优化对齐视频扩散模型,提升生成质量。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视频扩散模型 偏好学习 视频质量评估 在线学习 文本到视频生成 奖励模型 直接偏好优化
📋 核心要点
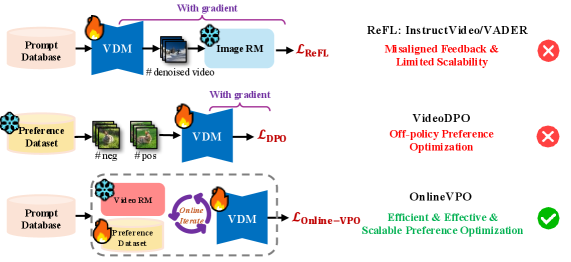
- 现有视频扩散模型存在图像质量下降和闪烁伪影问题,且缺乏针对视频特性的偏好优化。
- OnlineVPO利用视频质量评估(VQA)模型作为人类偏好的代理,并设计在线DPO算法进行优化。
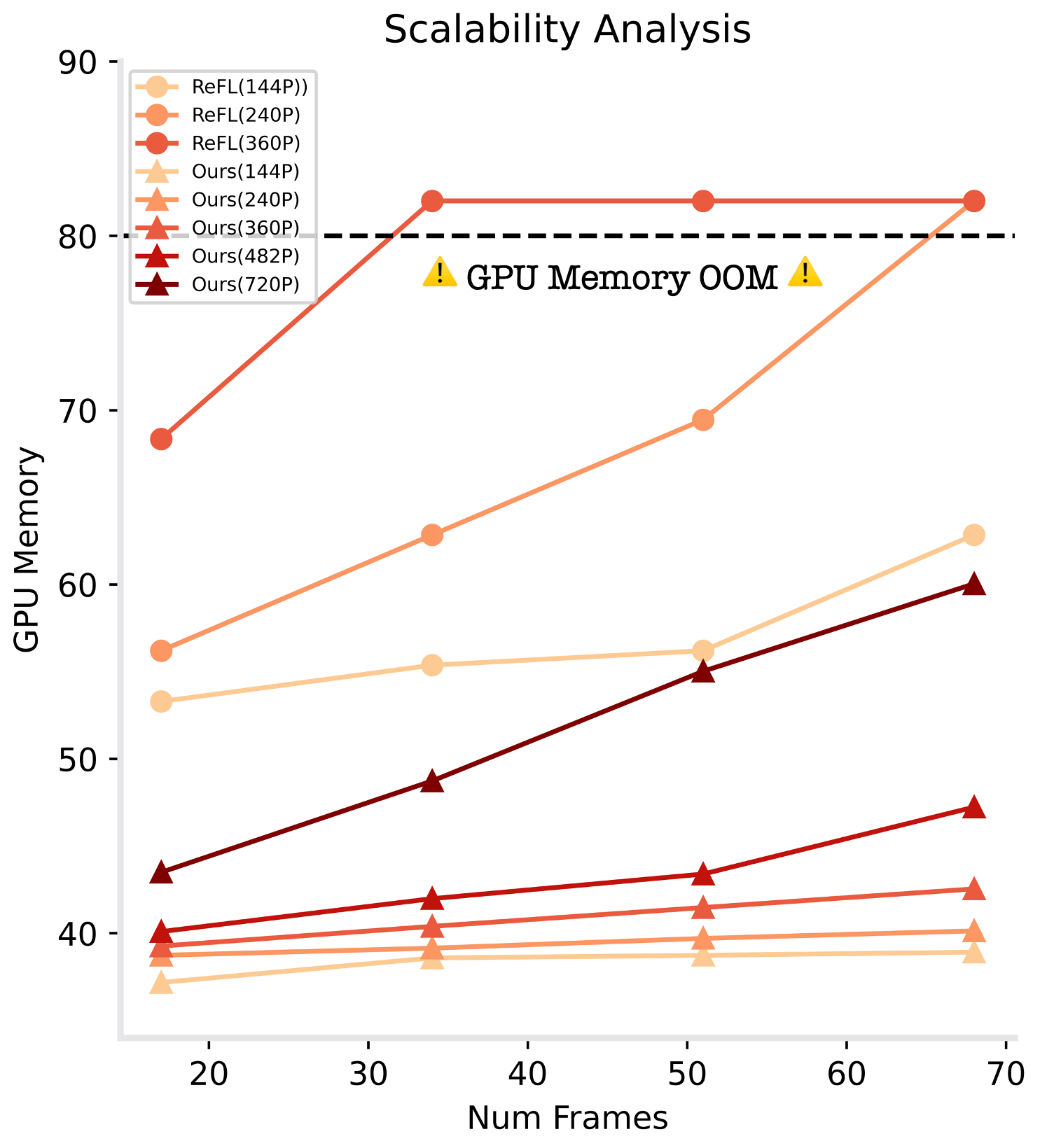
- 实验表明,OnlineVPO能有效提升视频扩散模型的生成质量,并具有良好的可扩展性。
📝 摘要(中文)
视频扩散模型(VDMs)在文本到视频(T2V)生成方面表现出卓越的能力。然而,VDMs仍然存在图像质量下降和闪烁伪影的问题。为了解决这些问题,一些方法引入了偏好学习,利用人类反馈来增强视频生成。但是,这些方法主要采用图像领域的常规方法,而没有深入研究视频特定的偏好优化。本文从反馈源和反馈调整方法两个关键方面重新审视了视频偏好学习的设计,并提出了OnlineVPO,这是一个专为VDMs量身定制的更有效的偏好学习框架。在反馈源方面,我们发现现有方法中常用的图像级奖励模型由于模态差距而无法提供与人类对齐的视频偏好信号。相比之下,视频质量评估(VQA)模型显示出与人类对视频质量的感知具有更好的对齐性。基于这一洞察,我们建议利用VQA模型作为人类的代理,为VDMs提供更符合模态的反馈。关于偏好调整方法,我们引入了一种为VDMs量身定制的在线DPO算法。与现有方法相比,它不仅在优化具有更高分辨率和更长持续时间的视频方面具有卓越的可扩展性,而且还通过在线偏好生成和课程偏好更新设计,缓解了由离线策略学习引起的优化不足问题。在开源视频扩散模型上的大量实验表明,OnlineVPO是一种简单而有效,更重要的是,可扩展的视频扩散模型偏好学习算法。
🔬 方法详解
问题定义:现有基于偏好学习的视频生成方法,直接套用图像领域的奖励模型,忽略了视频模态的特殊性,导致奖励信号与人类感知不一致。此外,离线策略学习导致优化不足,难以处理高分辨率和长时序的视频生成任务。
核心思路:OnlineVPO的核心在于利用视频质量评估(VQA)模型作为人类偏好的代理,提供更符合视频模态的奖励信号。同时,采用在线直接偏好优化(DPO)算法,避免离线学习的不足,并提升算法的可扩展性。
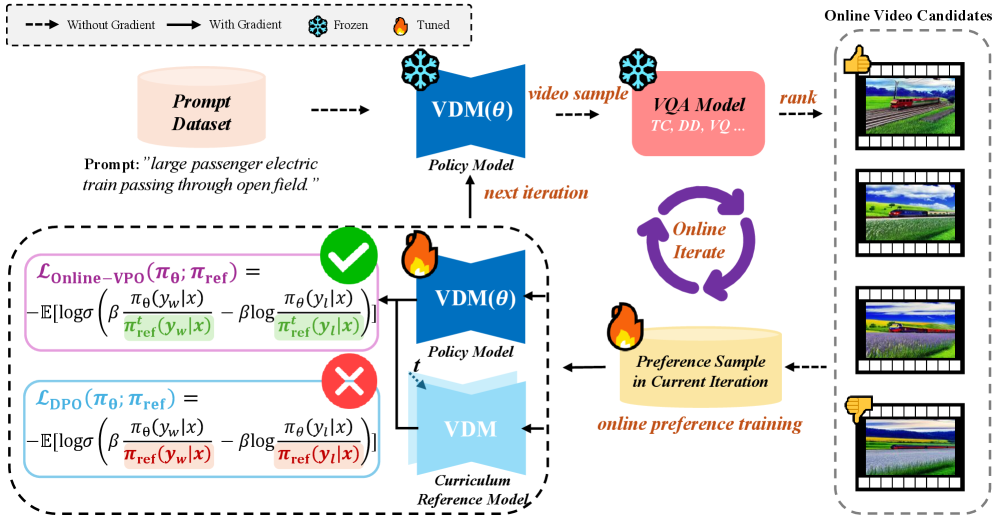
技术框架:OnlineVPO框架主要包含两个关键部分:1) 使用VQA模型作为奖励模型,评估生成视频的质量,提供偏好信号。2) 采用在线DPO算法,根据VQA模型提供的偏好信号,实时更新视频扩散模型的参数。该在线DPO算法包含在线偏好生成和课程偏好更新两个设计。
关键创新:OnlineVPO的关键创新在于:1) 提出使用VQA模型作为视频扩散模型的偏好学习的奖励模型,解决了图像领域奖励模型与视频模态不匹配的问题。2) 提出在线DPO算法,克服了离线学习的局限性,提升了算法的可扩展性,使其能够处理高分辨率和长时序的视频生成任务。
关键设计:OnlineVPO的关键设计包括:1) 选择合适的VQA模型,例如BRISQUE、NIQE等,作为奖励模型。2) 设计在线DPO算法的损失函数,使其能够根据VQA模型提供的偏好信号,有效地更新视频扩散模型的参数。3) 采用课程偏好更新策略,逐步提升生成视频的质量。
🖼️ 关键图片
📊 实验亮点
实验结果表明,OnlineVPO在提升视频生成质量方面优于现有方法。例如,在文本到视频生成任务中,OnlineVPO能够显著降低视频的闪烁伪影,并提升视频的清晰度和真实感。此外,OnlineVPO在处理高分辨率和长时序视频生成任务时,表现出良好的可扩展性。
🎯 应用场景
OnlineVPO可应用于各种视频生成场景,例如文本到视频生成、视频编辑、视频修复等。通过提升视频生成质量和用户满意度,该研究具有广阔的应用前景,并有望推动视频内容创作和消费的发展。
📄 摘要(原文)
Video diffusion models (VDMs) have demonstrated remarkable capabilities in text-to-video (T2V) generation. Despite their success, VDMs still suffer from degraded image quality and flickering artifacts. To address these issues, some approaches have introduced preference learning to exploit human feedback to enhance the video generation. However, these methods primarily adopt the routine in the image domain without an in-depth investigation into video-specific preference optimization. In this paper, we reexamine the design of the video preference learning from two key aspects: feedback source and feedback tuning methodology, and present OnlineVPO, a more efficient preference learning framework tailored specifically for VDMs. On the feedback source, we found that the image-level reward model commonly used in existing methods fails to provide a human-aligned video preference signal due to the modality gap. In contrast, video quality assessment (VQA) models show superior alignment with human perception of video quality. Building on this insight, we propose leveraging VQA models as a proxy of humans to provide more modality-aligned feedback for VDMs. Regarding the preference tuning methodology, we introduce an online DPO algorithm tailored for VDMs. It not only enjoys the benefits of superior scalability in optimizing videos with higher resolution and longer duration compared with the existing method, but also mitigates the insufficient optimization issue caused by off-policy learning via online preference generation and curriculum preference update designs. Extensive experiments on the open-source video-diffusion model demonstrate OnlineVPO as a simple yet effective and, more importantly, scalable preference learning algorithm for video diffusion models.