Video Prediction Policy: A Generalist Robot Policy with Predictive Visual Representations
作者: Yucheng Hu, Yanjiang Guo, Pengchao Wang, Xiaoyu Chen, Yen-Jen Wang, Jianke Zhang, Koushil Sreenath, Chaochao Lu, Jianyu Chen
分类: cs.CV, cs.RO
发布日期: 2024-12-19 (更新: 2025-05-04)
备注: ICML 2025 Spotlight Paper. The first two authors contribute equally
💡 一句话要点
提出基于视频预测策略(VPP)的通用机器人策略,利用预测视觉表征提升机器人操作能力。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频预测 机器人策略 视觉表征学习 通用机器人 逆动力学模型
📋 核心要点
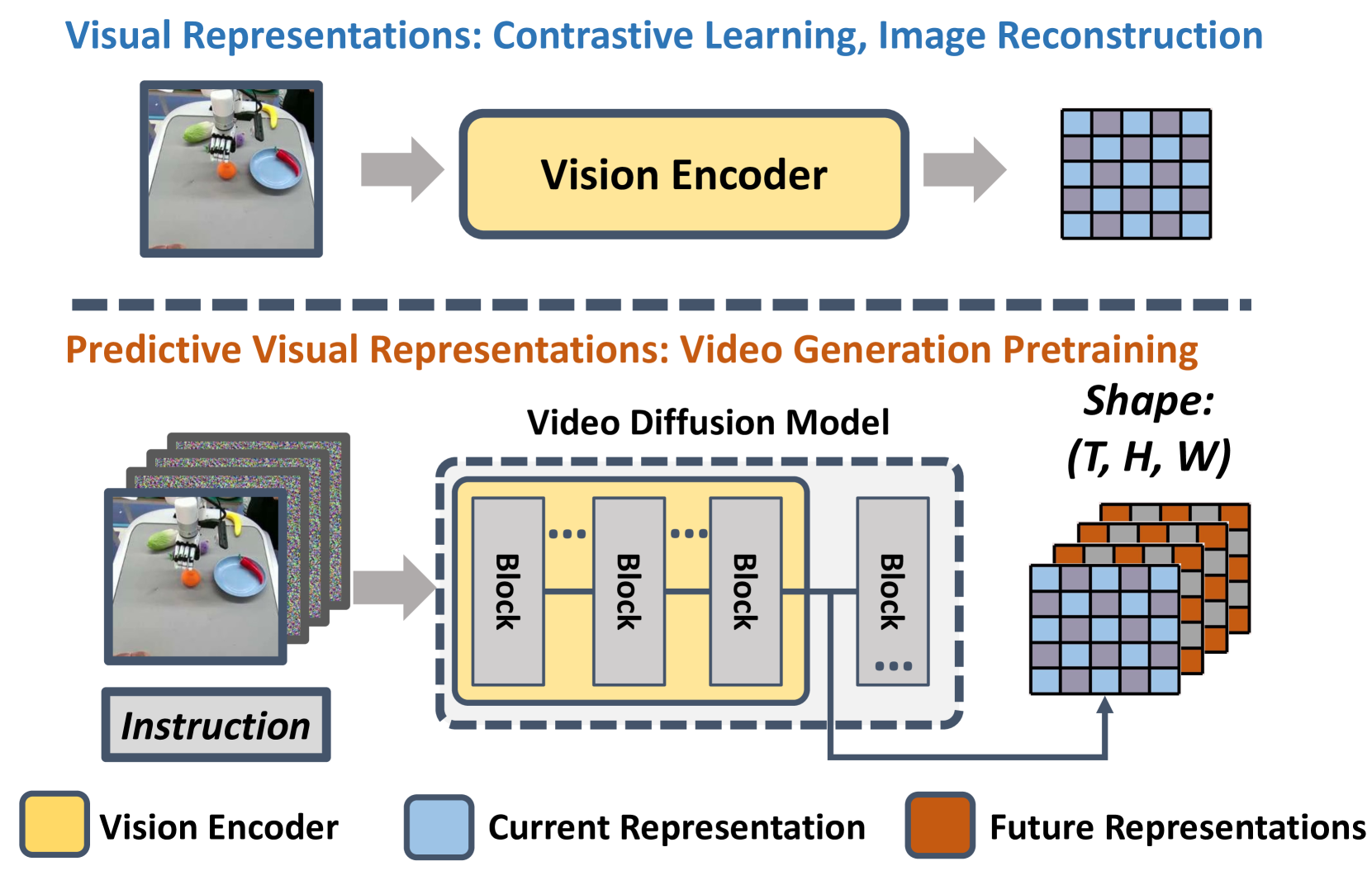
- 现有视觉编码器侧重于静态信息,忽略了具身任务中重要的动态信息,限制了通用机器人策略的发展。
- 论文提出视频预测策略(VPP),利用视频扩散模型(VDM)预测未来帧,从而获得包含动态信息的视觉表征。
- 实验表明,VPP在机器人操作任务中显著优于现有方法,在泛化性和真实世界任务中均有提升。
📝 摘要(中文)
视觉表征在开发通用机器人策略中起着至关重要的作用。以往的视觉编码器通常使用单图像重建或双图像对比学习进行预训练,倾向于捕获静态信息,而忽略了对具身任务至关重要的动态方面。最近,视频扩散模型(VDMs)展示了预测未来帧的能力,并表现出对物理世界的深刻理解。我们假设VDMs固有地产生包含当前静态信息和预测未来动态的视觉表征,从而为机器人动作学习提供有价值的指导。基于此,我们提出了视频预测策略(VPP),它学习以VDM内部预测的未来表征为条件的隐式逆动力学模型。为了预测更精确的未来,我们在机器人数据集以及互联网人类操作数据上微调预训练的视频基础模型。在实验中,与之前的最先进技术相比,VPP在Calvin ABC-D泛化基准上实现了18.6%的相对改进,并在复杂的真实世界灵巧操作任务中成功率提高了31.6%。
🔬 方法详解
问题定义:现有机器人策略依赖的视觉表征往往侧重于静态场景信息,缺乏对动态环境变化的建模能力。这导致机器人难以适应复杂的操作任务,尤其是在泛化性和真实世界应用中表现不佳。因此,如何获取包含丰富动态信息的视觉表征,是提升通用机器人策略的关键挑战。
核心思路:论文的核心思路是利用视频扩散模型(VDM)强大的视频预测能力,从预测的未来帧中提取视觉表征。VDM通过学习视频中的时序关系,能够捕捉到环境的动态变化,从而为机器人策略提供更全面的信息。这种基于预测的视觉表征能够更好地指导机器人动作的学习。
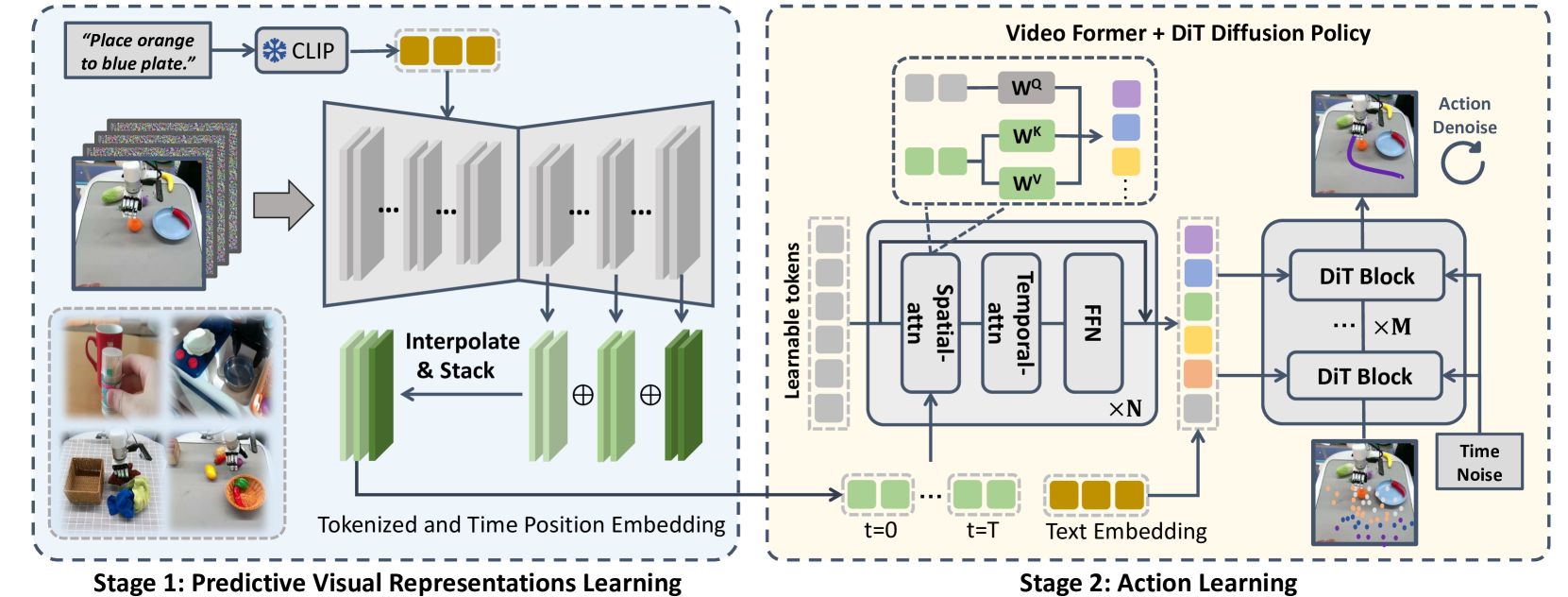
技术框架:VPP框架主要包含以下几个模块:1) 预训练的视频扩散模型(VDM):用于预测未来帧。2) 视觉表征提取器:从VDM预测的未来帧中提取视觉表征。3) 隐式逆动力学模型:以提取的视觉表征为条件,学习从状态到动作的映射。整个流程是,首先利用VDM预测未来视觉状态,然后提取这些状态的表征,最后将这些表征输入到逆动力学模型中,从而得到控制机器人的动作。
关键创新:论文的关键创新在于将视频预测模型与机器人策略学习相结合。以往的方法通常使用单图像或双图像的对比学习来获取视觉表征,而VPP则利用VDM的视频预测能力,从而能够学习到包含动态信息的视觉表征。这种基于预测的视觉表征能够更好地指导机器人动作的学习,从而提升了机器人策略的泛化性和真实世界应用能力。
关键设计:为了提高VDM的预测精度,论文在机器人数据集和互联网人类操作数据上对预训练的VDM进行了微调。此外,论文还设计了一种隐式逆动力学模型,该模型以VDM预测的未来表征为条件,学习从状态到动作的映射。损失函数包括动作预测损失和状态预测损失,用于优化逆动力学模型。
🖼️ 关键图片
📊 实验亮点
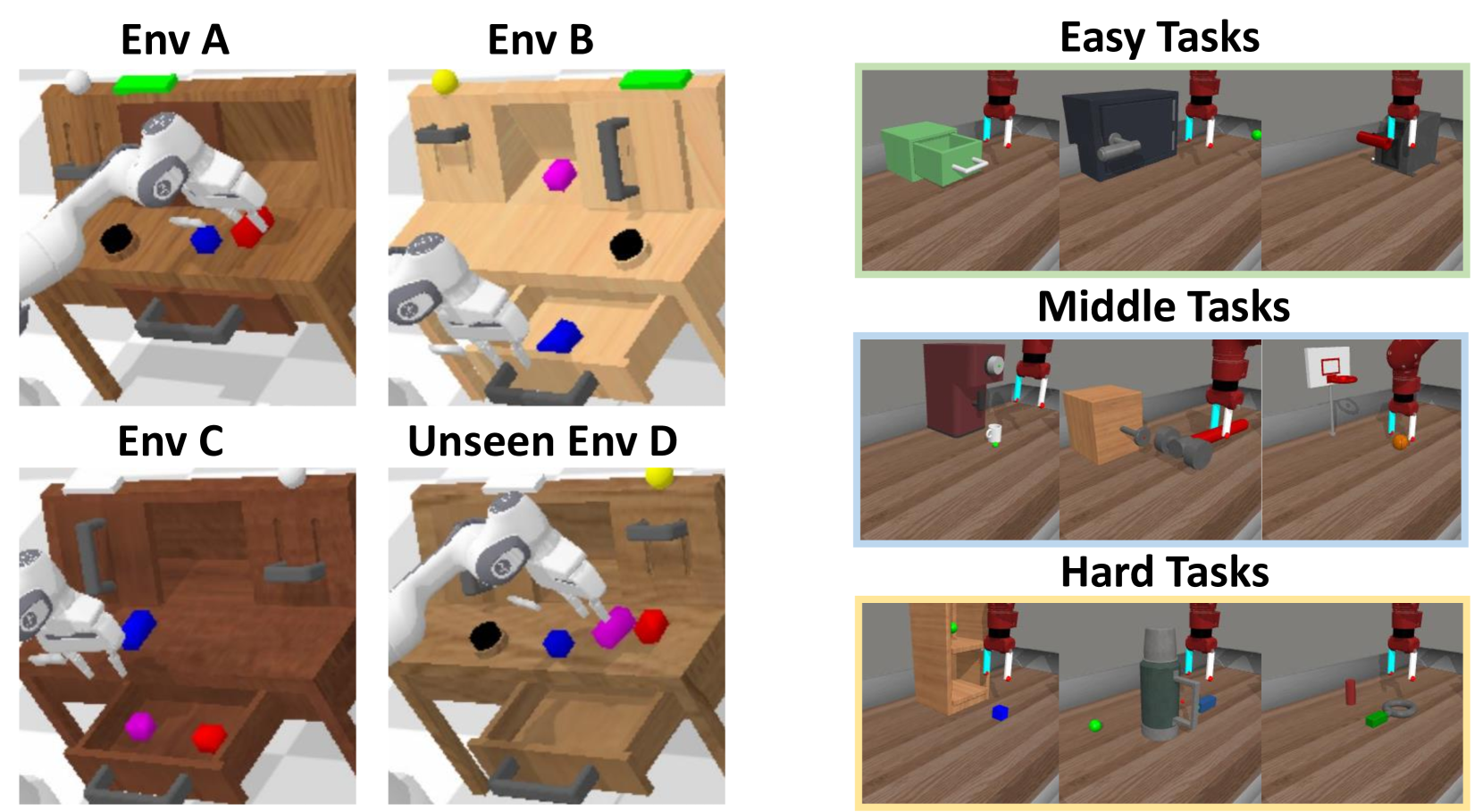
VPP在Calvin ABC-D泛化基准上实现了18.6%的相对改进,超越了之前的SOTA方法。在复杂的真实世界灵巧操作任务中,VPP的成功率提高了31.6%。这些实验结果表明,VPP能够有效地学习包含动态信息的视觉表征,从而显著提升机器人策略的泛化性和真实世界应用能力。
🎯 应用场景
该研究成果可应用于各种机器人操作任务,例如家庭服务机器人、工业自动化机器人和医疗机器人等。通过提升机器人对环境动态变化的理解能力,可以使其更好地完成复杂的操作任务,提高工作效率和安全性。未来,该方法有望进一步扩展到更广泛的机器人应用领域,例如自动驾驶和无人机等。
📄 摘要(原文)
Visual representations play a crucial role in developing generalist robotic policies. Previous vision encoders, typically pre-trained with single-image reconstruction or two-image contrastive learning, tend to capture static information, often neglecting the dynamic aspects vital for embodied tasks. Recently, video diffusion models (VDMs) demonstrate the ability to predict future frames and showcase a strong understanding of physical world. We hypothesize that VDMs inherently produce visual representations that encompass both current static information and predicted future dynamics, thereby providing valuable guidance for robot action learning. Based on this hypothesis, we propose the Video Prediction Policy (VPP), which learns implicit inverse dynamics model conditioned on predicted future representations inside VDMs. To predict more precise future, we fine-tune pre-trained video foundation model on robot datasets along with internet human manipulation data. In experiments, VPP achieves a 18.6\% relative improvement on the Calvin ABC-D generalization benchmark compared to the previous state-of-the-art, and demonstrates a 31.6\% increase in success rates for complex real-world dexterous manipulation tasks. Project page at https://video-prediction-policy.github.io