A Light-Weight Framework for Open-Set Object Detection with Decoupled Feature Alignment in Joint Space
作者: Yonghao He, Hu Su, Haiyong Yu, Cong Yang, Wei Sui, Cong Wang, Song Liu
分类: cs.CV, cs.AI, cs.RO
发布日期: 2024-12-19 (更新: 2024-12-25)
🔗 代码/项目: GITHUB
💡 一句话要点
提出轻量级解耦开放集目标检测框架DOSOD,提升机器人应用中的实时性。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 开放集目标检测 机器人操作 视觉-语言模型 特征对齐 实时性
📋 核心要点
- 现有开放集目标检测方法计算量大、部署复杂,难以满足机器人实时操作的需求。
- DOSOD框架通过解耦特征对齐,在联合空间中直接对齐跨模态特征,避免复杂交互,提升计算效率。
- 实验表明,DOSOD在保持精度相当的同时,显著提升了实时性能,并易于部署在边缘设备上。
📝 摘要(中文)
开放集目标检测(OSOD)在非结构化环境中对机器人操作至关重要。然而,现有的OSOD方法由于计算负担重和部署复杂,通常无法满足机器人应用的需求。为了解决这个问题,本文提出了一种轻量级框架,称为解耦OSOD (DOSOD),它是一种实用且高效的解决方案,支持机器人系统中的实时OSOD任务。具体来说,DOSOD基于YOLO-World流程,通过将视觉-语言模型(VLM)与检测器集成。开发了一个多层感知器(MLP)适配器,将VLM提取的文本嵌入转换为联合空间,检测器在其中学习类别无关提议的区域表示。跨模态特征直接在联合空间中对齐,避免了复杂的特征交互,从而提高了计算效率。DOSOD在测试阶段像传统的闭集检测器一样运行,有效地弥合了闭集和开放集检测之间的差距。与基线YOLO-World相比,所提出的DOSOD在保持相当精度的同时,显著提高了实时性能。在使用类似骨干网络在LVIS minival数据集上进行测试时,轻量级的DOSOD-S模型的Fixed AP为26.7%,而YOLO-World-v1-S为26.2%,YOLO-World-v2-S为22.7%。同时,DOSOD-S的FPS比YOLO-World-v1-S高57.1%,比YOLO-World-v2-S高29.6%。此外,我们证明了DOSOD模型有助于边缘设备的部署。代码和模型可在https://github.com/D-Robotics-AI-Lab/DOSOD公开获取。
🔬 方法详解
问题定义:论文旨在解决开放集目标检测(OSOD)在机器人应用中实时性不足的问题。现有的OSOD方法通常计算量大,部署复杂,难以满足机器人实时操作的需求,限制了其在实际场景中的应用。
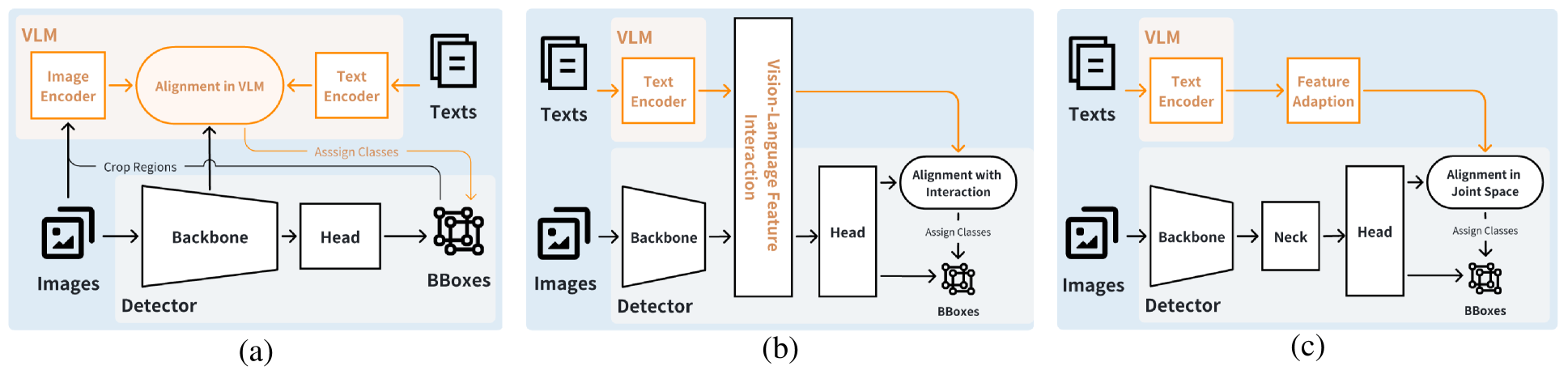
核心思路:论文的核心思路是解耦特征对齐过程,通过将视觉和语言特征映射到联合空间,直接在该空间中进行对齐,避免了复杂的特征交互。这种方法降低了计算复杂度,提高了实时性。
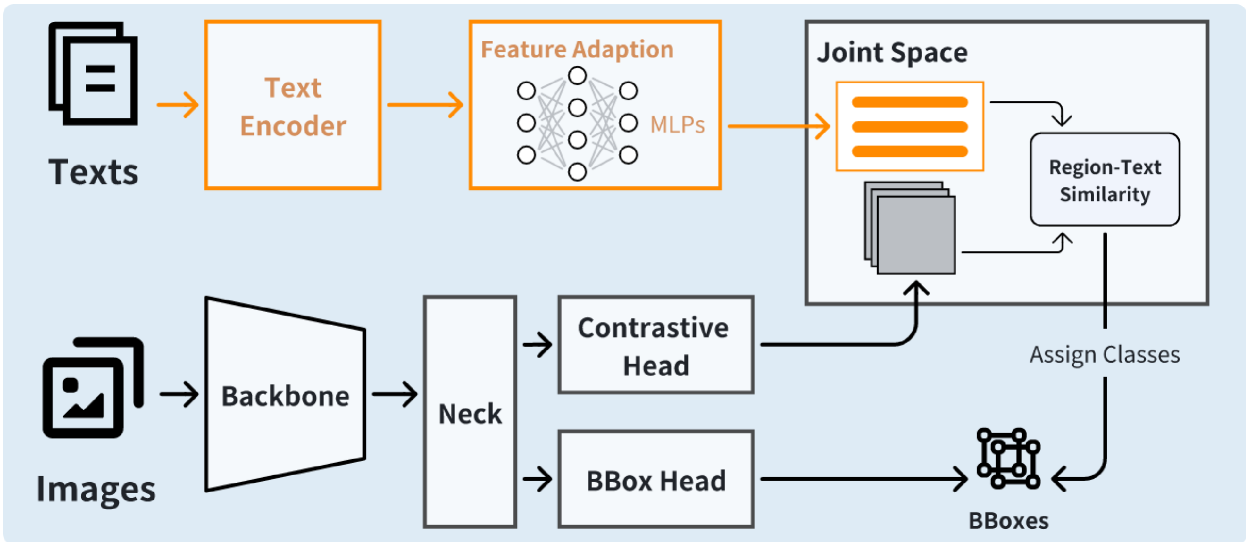
技术框架:DOSOD框架基于YOLO-World pipeline,主要包含以下模块:1) 视觉-语言模型(VLM):用于提取文本嵌入;2) 多层感知器(MLP)适配器:将文本嵌入转换到联合空间;3) 检测器:学习联合空间中类别无关提议的区域表示。整体流程是,首先使用VLM提取文本嵌入,然后通过MLP适配器将其映射到联合空间,最后检测器在联合空间中进行目标检测。
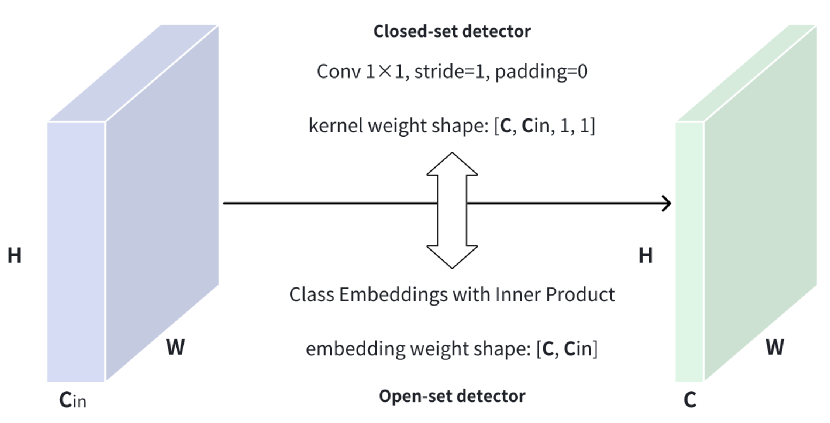
关键创新:最重要的技术创新点在于解耦的特征对齐方式。与现有方法相比,DOSOD避免了复杂的跨模态特征交互,直接在联合空间中进行特征对齐,从而显著降低了计算复杂度,提高了实时性。此外,DOSOD在测试阶段像传统的闭集检测器一样运行,有效地弥合了闭集和开放集检测之间的差距。
关键设计:MLP适配器的具体结构(层数、神经元数量等)未知,但其作用是将文本嵌入映射到与视觉特征相同的联合空间。损失函数未知,但推测使用了目标检测常用的损失函数,例如分类损失和回归损失。网络结构方面,DOSOD基于YOLO-World,因此沿用了YOLO系列的检测头设计。
🖼️ 关键图片
📊 实验亮点
DOSOD-S模型在LVIS minival数据集上取得了显著的性能提升。在保持精度相当的情况下,DOSOD-S的Fixed AP为26.7%,与YOLO-World-v1-S的26.2%和YOLO-World-v2-S的22.7%相比具有竞争力。更重要的是,DOSOD-S的FPS比YOLO-World-v1-S高57.1%,比YOLO-World-v2-S高29.6%,表明其在实时性方面具有显著优势。
🎯 应用场景
该研究成果可广泛应用于机器人操作、自动驾驶、智能监控等领域。在机器人操作中,DOSOD能够帮助机器人在非结构化环境中实时检测和识别未知物体,从而实现更灵活、智能的操作。在自动驾驶中,可以提升对复杂场景的感知能力,识别未知的交通参与者。在智能监控中,可以检测异常事件和未知目标,提高安全性和智能化水平。
📄 摘要(原文)
Open-set object detection (OSOD) is highly desirable for robotic manipulation in unstructured environments. However, existing OSOD methods often fail to meet the requirements of robotic applications due to their high computational burden and complex deployment. To address this issue, this paper proposes a light-weight framework called Decoupled OSOD (DOSOD), which is a practical and highly efficient solution to support real-time OSOD tasks in robotic systems. Specifically, DOSOD builds upon the YOLO-World pipeline by integrating a vision-language model (VLM) with a detector. A Multilayer Perceptron (MLP) adaptor is developed to transform text embeddings extracted by the VLM into a joint space, within which the detector learns the region representations of class-agnostic proposals. Cross-modality features are directly aligned in the joint space, avoiding the complex feature interactions and thereby improving computational efficiency. DOSOD operates like a traditional closed-set detector during the testing phase, effectively bridging the gap between closed-set and open-set detection. Compared to the baseline YOLO-World, the proposed DOSOD significantly enhances real-time performance while maintaining comparable accuracy. The slight DOSOD-S model achieves a Fixed AP of $26.7\%$, compared to $26.2\%$ for YOLO-World-v1-S and $22.7\%$ for YOLO-World-v2-S, using similar backbones on the LVIS minival dataset. Meanwhile, the FPS of DOSOD-S is $57.1\%$ higher than YOLO-World-v1-S and $29.6\%$ higher than YOLO-World-v2-S. Meanwhile, we demonstrate that the DOSOD model facilitates the deployment of edge devices. The codes and models are publicly available at https://github.com/D-Robotics-AI-Lab/DOSOD.