Can We Get Rid of Handcrafted Feature Extractors? SparseViT: Nonsemantics-Centered, Parameter-Efficient Image Manipulation Localization through Spare-Coding Transformer
作者: Lei Su, Xiaochen Ma, Xuekang Zhu, Chaoqun Niu, Zeyu Lei, Ji-Zhe Zhou
分类: cs.CV
发布日期: 2024-12-19 (更新: 2024-12-23)
备注: published to AAAI2025
💡 一句话要点
SparseViT:通过稀疏编码Transformer自适应提取非语义特征,实现高效图像篡改定位
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 图像篡改定位 非语义特征 稀疏自注意力 视觉Transformer 参数效率
📋 核心要点
- 现有图像篡改定位方法依赖手工设计的非语义特征提取器,泛化能力受限,难以适应复杂场景。
- SparseViT通过稀疏自注意力机制打破图像语义,迫使模型自适应地学习对篡改敏感的非语义特征。
- 实验表明,SparseViT在多个基准数据集上实现了更好的泛化能力和计算效率,且无需手工特征提取。
📝 摘要(中文)
图像篡改定位(IML)任务依赖于对图像上下文不敏感但对图像篡改敏感的非语义特征。现有方法依赖手工设计的特征提取器来提取这些特征,这限制了模型在未见过的或复杂场景中的泛化能力。本文提出了一种稀疏视觉Transformer (SparseViT),将ViT中密集的全局自注意力机制重构为稀疏的、离散的方式。这种稀疏自注意力打破了图像语义,迫使SparseViT自适应地提取图像的非语义特征。此外,与现有的IML模型相比,稀疏自注意力机制大大减少了模型大小(FLOPs最多减少80%),实现了惊人的参数效率和计算量减少。大量实验表明,在没有任何手工设计的特征提取器的情况下,SparseViT在基准数据集上的泛化能力和效率都更胜一筹。
🔬 方法详解
问题定义:图像篡改定位旨在识别图像中被篡改的区域。现有方法依赖手工设计的特征提取器来提取对篡改敏感的非语义特征,但这些手工特征提取器难以泛化到未见过的场景,成为模型性能瓶颈。
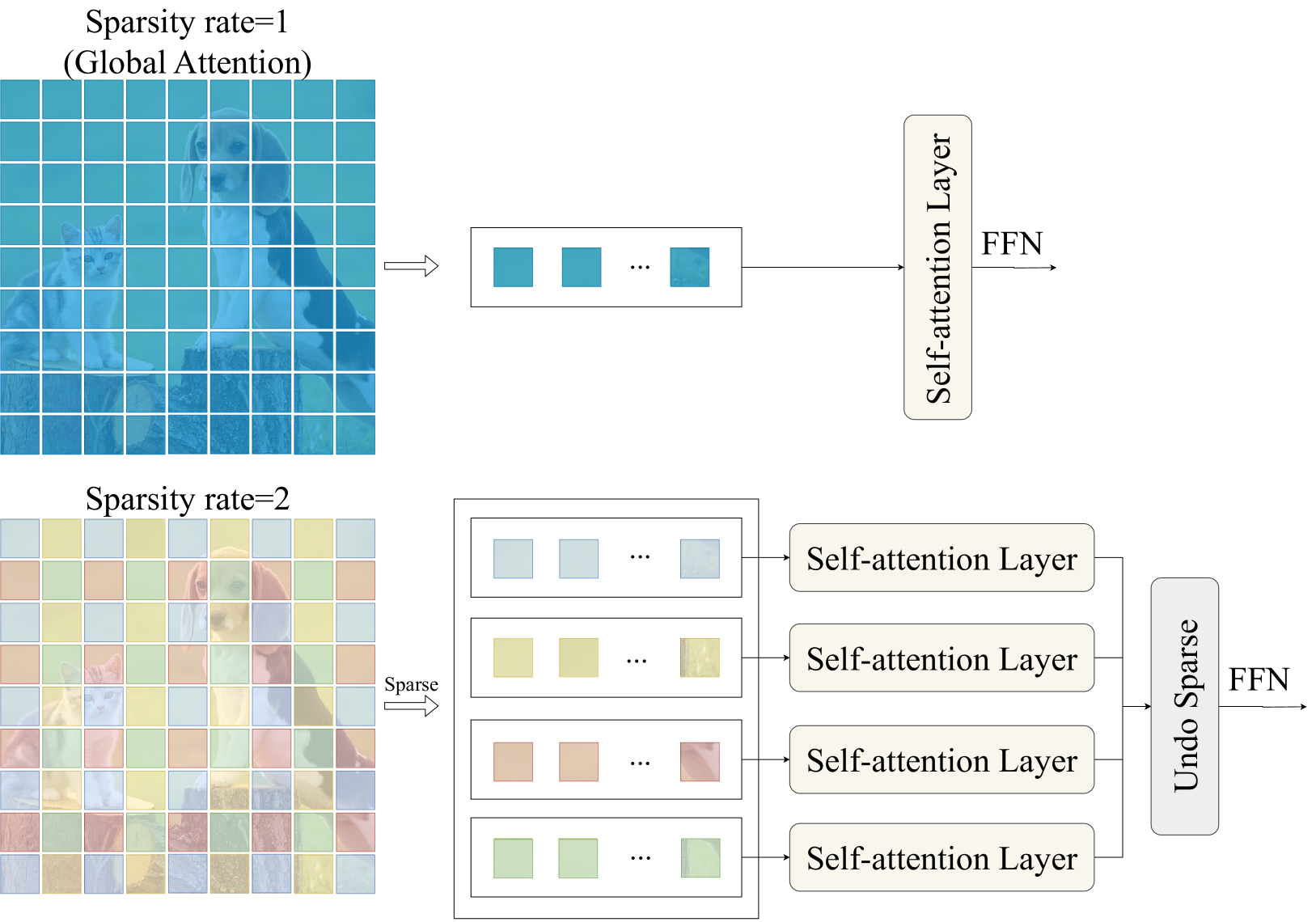
核心思路:论文的核心思想是通过稀疏自注意力机制,迫使模型自适应地学习非语义特征。非语义特征对图像上下文不敏感,因此只需要图像块之间的稀疏交互即可提取。与此相反,语义特征需要密集的全局交互。
技术框架:SparseViT基于Transformer架构,主要由稀疏自注意力模块组成。它将ViT中密集的全局自注意力替换为稀疏的、离散的自注意力。整体流程与ViT类似,包括图像分块、线性嵌入、Transformer编码器和最终的篡改定位预测。
关键创新:最重要的创新点是使用稀疏自注意力来提取非语义特征。与传统ViT的密集自注意力相比,稀疏自注意力能够打破图像语义,迫使模型关注对篡改更敏感的非语义信息。这使得模型能够自适应地学习特征,而无需手工设计特征提取器。
关键设计:SparseViT的关键设计在于稀疏自注意力的具体实现方式。论文中可能采用了某种特定的稀疏模式(例如,随机稀疏、局部稀疏等)来限制注意力计算的范围。此外,损失函数的设计也可能针对篡改定位任务进行了优化,例如,使用交叉熵损失或Focal Loss来平衡正负样本。
🖼️ 关键图片


📊 实验亮点
SparseViT在图像篡改定位任务上取得了显著的性能提升,无需任何手工设计的特征提取器。实验结果表明,SparseViT在多个基准数据集上优于现有方法,并且模型大小和计算量大幅减少(FLOPs最多减少80%),实现了更高的参数效率。
🎯 应用场景
该研究成果可应用于数字取证、新闻真实性验证、图像安全等领域。通过自动检测图像篡改,可以帮助识别虚假信息,维护网络安全,并为司法鉴定提供技术支持。未来,该方法有望扩展到视频篡改检测,并与其他模态的信息融合,提高检测的准确性和鲁棒性。
📄 摘要(原文)
Non-semantic features or semantic-agnostic features, which are irrelevant to image context but sensitive to image manipulations, are recognized as evidential to Image Manipulation Localization (IML). Since manual labels are impossible, existing works rely on handcrafted methods to extract non-semantic features. Handcrafted non-semantic features jeopardize IML model's generalization ability in unseen or complex scenarios. Therefore, for IML, the elephant in the room is: How to adaptively extract non-semantic features? Non-semantic features are context-irrelevant and manipulation-sensitive. That is, within an image, they are consistent across patches unless manipulation occurs. Then, spare and discrete interactions among image patches are sufficient for extracting non-semantic features. However, image semantics vary drastically on different patches, requiring dense and continuous interactions among image patches for learning semantic representations. Hence, in this paper, we propose a Sparse Vision Transformer (SparseViT), which reformulates the dense, global self-attention in ViT into a sparse, discrete manner. Such sparse self-attention breaks image semantics and forces SparseViT to adaptively extract non-semantic features for images. Besides, compared with existing IML models, the sparse self-attention mechanism largely reduced the model size (max 80% in FLOPs), achieving stunning parameter efficiency and computation reduction. Extensive experiments demonstrate that, without any handcrafted feature extractors, SparseViT is superior in both generalization and efficiency across benchmark datasets.