DiffSim: Taming Diffusion Models for Evaluating Visual Similarity
作者: Yiren Song, Xiaokang Liu, Mike Zheng Shou
分类: cs.CV
发布日期: 2024-12-19
💡 一句话要点
DiffSim:利用扩散模型评估视觉相似性,提升生成模型质量
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation)
关键词: 视觉相似性 扩散模型 生成模型评估 注意力机制 深度学习 图像生成 风格迁移
📋 核心要点
- 现有感知相似性度量方法主要关注低级特征,无法有效捕捉图像布局和语义信息,导致评估生成模型质量受限。
- DiffSim利用预训练扩散模型,通过对齐去噪U-Net的注意力层特征,同时评估外观和风格的相似性。
- 实验表明,DiffSim在多个视觉相似性基准测试中取得了SOTA性能,更符合人类的视觉感知。
📝 摘要(中文)
扩散模型从根本上改变了生成模型领域,使得评估定制模型输出与参考输入之间的相似性至关重要。然而,传统的感知相似性度量主要在像素和patch级别操作,比较低级的颜色和纹理,无法捕捉图像布局、物体姿态和语义内容中的中级相似性和差异。基于对比学习的CLIP和基于自监督学习的DINO常用于测量语义相似性,但它们高度压缩图像特征,无法充分评估外观细节。本文首次发现预训练的扩散模型可用于测量视觉相似性,并提出了DiffSim方法,解决了传统度量在捕捉定制生成任务中感知一致性的局限性。通过对齐去噪U-Net的注意力层中的特征,DiffSim评估了外观和风格的相似性,表现出与人类视觉偏好更好的对齐。此外,我们引入了Sref和IP基准来分别评估风格和实例级别的视觉相似性。在多个基准上的综合评估表明,DiffSim实现了最先进的性能,为测量生成模型中的视觉连贯性提供了一个强大的工具。
🔬 方法详解
问题定义:论文旨在解决现有视觉相似性度量方法在评估生成模型输出质量时,无法有效捕捉中高级语义信息和风格细节的问题。传统方法如像素级比较和基于对比学习的方法,要么过于关注低级特征,要么过度压缩特征,导致评估结果与人类感知不一致。
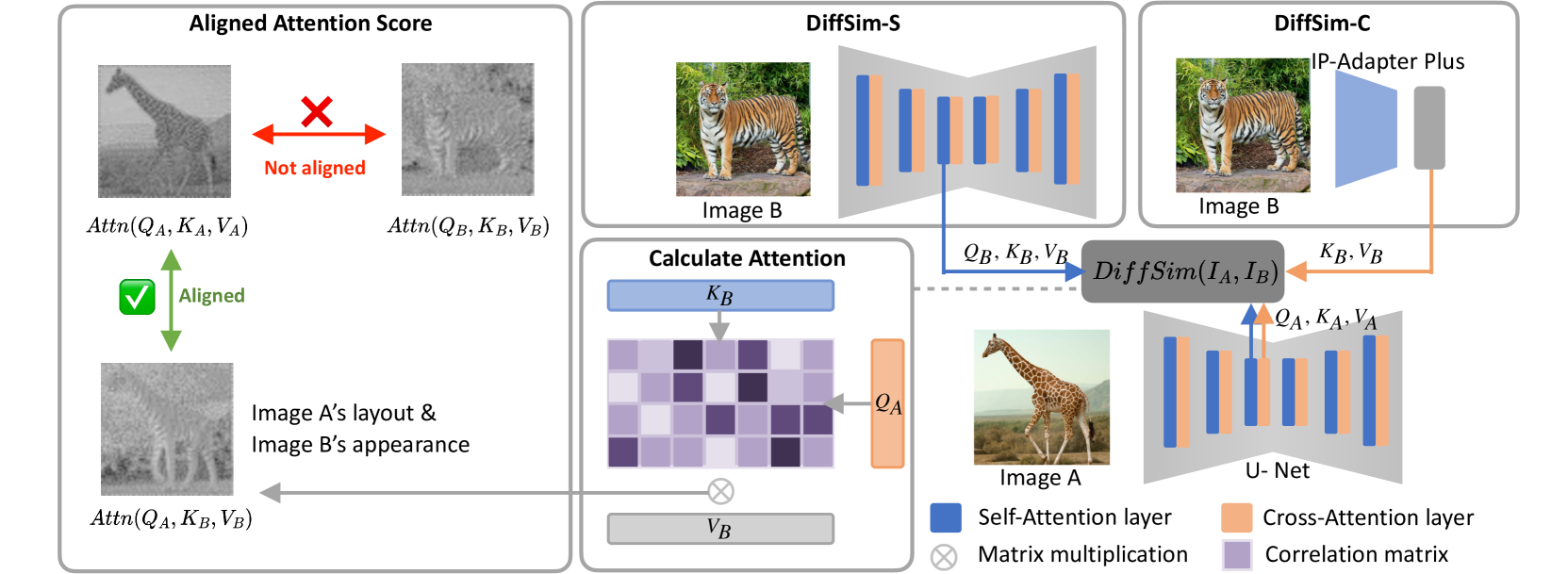
核心思路:论文的核心思路是利用预训练扩散模型强大的特征提取能力,特别是其在去噪过程中学习到的图像结构和语义信息。通过比较扩散模型中间层(特别是注意力层)的特征,可以更全面地评估图像之间的相似性,包括外观、风格和语义。
技术框架:DiffSim方法主要包含以下步骤:1) 使用预训练的扩散模型(例如,Stable Diffusion)对参考图像和生成图像进行编码;2) 提取扩散模型U-Net的注意力层特征;3) 计算参考图像和生成图像在注意力层特征上的相似度;4) 将不同层的相似度进行加权融合,得到最终的相似性得分。
关键创新:DiffSim的关键创新在于:1) 首次提出利用预训练扩散模型进行视觉相似性度量;2) 通过对齐扩散模型U-Net的注意力层特征,同时考虑了外观、风格和语义信息;3) 提出了新的Sref和IP基准,用于评估风格和实例级别的视觉相似性。
关键设计:DiffSim的关键设计包括:1) 选择合适的预训练扩散模型,例如Stable Diffusion;2) 选择合适的注意力层进行特征提取,通常选择中间层,以平衡低级和高级信息;3) 设计合适的相似度计算方法,例如余弦相似度或欧氏距离;4) 设计合适的加权融合策略,以平衡不同层特征的重要性。论文中具体参数设置和网络结构细节未知。
🖼️ 关键图片


📊 实验亮点
DiffSim在多个视觉相似性基准测试中取得了SOTA性能,包括Sref和IP基准。具体性能数据和提升幅度在论文中未明确给出,但摘要强调DiffSim在捕捉感知一致性方面优于传统方法,并与人类视觉偏好更好地对齐。DiffSim的优越性主要体现在对风格和实例级别相似性的准确评估。
🎯 应用场景
DiffSim可广泛应用于生成模型的评估和优化,例如图像生成、风格迁移、图像修复等任务。它可以帮助研究人员和开发者更准确地评估生成模型的输出质量,从而改进模型设计和训练策略。此外,DiffSim还可以用于图像检索、图像分类等领域,提高视觉任务的性能。
📄 摘要(原文)
Diffusion models have fundamentally transformed the field of generative models, making the assessment of similarity between customized model outputs and reference inputs critically important. However, traditional perceptual similarity metrics operate primarily at the pixel and patch levels, comparing low-level colors and textures but failing to capture mid-level similarities and differences in image layout, object pose, and semantic content. Contrastive learning-based CLIP and self-supervised learning-based DINO are often used to measure semantic similarity, but they highly compress image features, inadequately assessing appearance details. This paper is the first to discover that pretrained diffusion models can be utilized for measuring visual similarity and introduces the DiffSim method, addressing the limitations of traditional metrics in capturing perceptual consistency in custom generation tasks. By aligning features in the attention layers of the denoising U-Net, DiffSim evaluates both appearance and style similarity, showing superior alignment with human visual preferences. Additionally, we introduce the Sref and IP benchmarks to evaluate visual similarity at the level of style and instance, respectively. Comprehensive evaluations across multiple benchmarks demonstrate that DiffSim achieves state-of-the-art performance, providing a robust tool for measuring visual coherence in generative models.