Token Preference Optimization with Self-Calibrated Visual-Anchored Rewards for Hallucination Mitigation
作者: Jihao Gu, Yingyao Wang, Meng Cao, Pi Bu, Jun Song, Yancheng He, Shilong Li, Bo Zheng
分类: cs.CV
发布日期: 2024-12-19 (更新: 2025-09-23)
💡 一句话要点
提出自校准视觉锚定奖励的Token偏好优化以缓解幻觉问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视觉语言模型 幻觉缓解 Token偏好优化 自校准机制 多模态学习
📋 核心要点
- 现有的直接偏好优化方法在处理token级奖励时缺乏可扩展性,并且未能充分利用视觉锚定token。
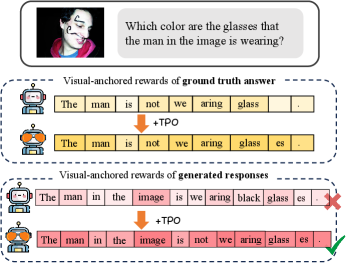
- 本文提出了一种自校准的Token偏好优化模型(TPO),通过引入视觉锚定奖励来解决上述问题,增强了模型对视觉相关token的关注。
- 实验结果显示,基于LLAVA-1.5-7B的TPO在幻觉基准测试中实现了显著的性能提升,展示了其有效性。
📝 摘要(中文)
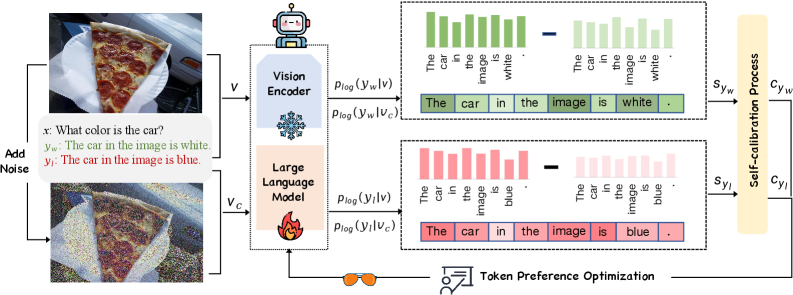
直接偏好优化(DPO)已被证明在缓解大型视觉语言模型(LVLMs)中的幻觉方面非常有效,通过使其输出更贴近人类偏好。然而,现有方法存在两个主要缺陷:缺乏可扩展的token级奖励,以及忽视视觉锚定token。为此,本文提出了一种新颖的Token偏好优化模型(TPO),该模型自适应地关注与视觉相关的token,而无需细粒度注释。具体而言,我们引入了一种token级的视觉锚定奖励,作为生成token在原始图像和损坏图像条件下的逻辑分布差异。此外,提出了一种视觉感知训练目标,以增强更准确的token级优化。大量实验结果表明,所提出的TPO在性能上达到了最先进的水平。
🔬 方法详解
问题定义:本文旨在解决大型视觉语言模型(LVLMs)中幻觉现象的缓解问题。现有方法在token级奖励的可扩展性和视觉锚定token的利用上存在不足。
核心思路:提出的TPO模型通过自适应关注视觉相关token,利用视觉锚定奖励来优化模型输出,避免了对细粒度注释的依赖。
技术框架:TPO模型的整体架构包括两个主要模块:视觉锚定奖励计算模块和视觉感知训练目标模块。前者负责生成token的奖励计算,后者则用于优化训练过程。
关键创新:本文的核心创新在于引入了token级的视觉锚定奖励,作为生成token在原始和损坏图像条件下的逻辑分布差异。这一设计使得模型能够更好地捕捉与视觉信息相关的token。
关键设计:在模型设计中,采用了自校准机制以动态调整奖励,同时引入了视觉感知训练目标,以确保模型在token级别的优化更加准确。
🖼️ 关键图片
📊 实验亮点
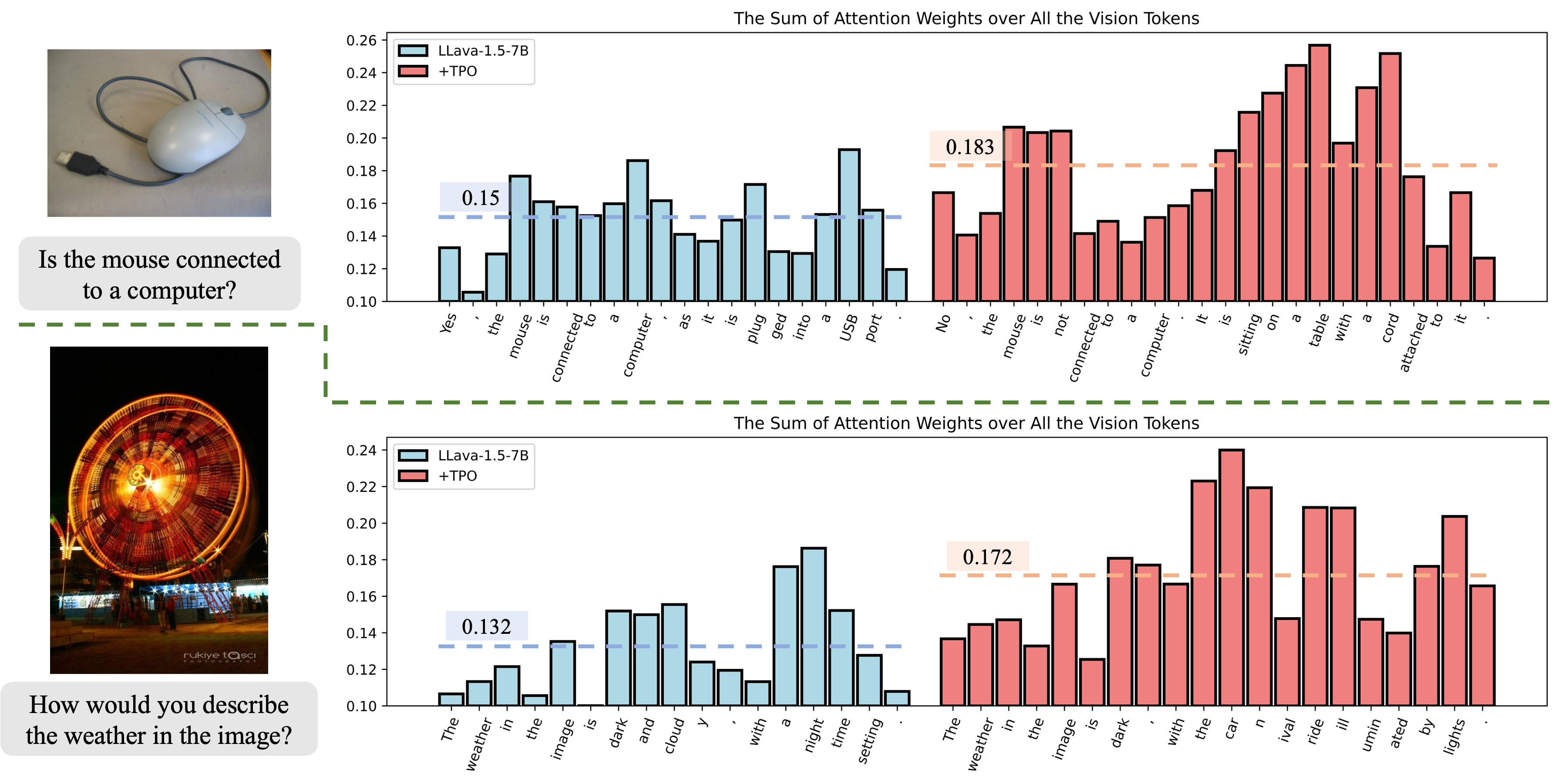
实验结果显示,基于LLAVA-1.5-7B的TPO在幻觉基准测试中实现了显著的性能提升,具体表现为相较于基线模型,性能提升幅度达到了绝对值的显著改善,展示了其在实际应用中的有效性。
🎯 应用场景
该研究的潜在应用领域包括图像生成、视觉问答和多模态内容生成等。通过提升模型对视觉信息的理解能力,TPO可以在实际应用中显著改善用户体验,推动智能助手和创作工具的发展。
📄 摘要(原文)
Direct Preference Optimization (DPO) has been demonstrated to be highly effective in mitigating hallucinations in Large Vision Language Models (LVLMs) by aligning their outputs more closely with human preferences. Despite the recent progress, existing methods suffer from two drawbacks: 1) Lack of scalable token-level rewards; and 2) Neglect of visual-anchored tokens. To this end, we propose a novel Token Preference Optimization model with self-calibrated rewards (dubbed as TPO), which adaptively attends to visual-correlated tokens without fine-grained annotations. Specifically, we introduce a token-level \emph{visual-anchored} \emph{reward} as the difference of the logistic distributions of generated tokens conditioned on the raw image and the corrupted one. In addition, to highlight the informative visual-anchored tokens, a visual-aware training objective is proposed to enhance more accurate token-level optimization. Extensive experimental results have manifested the state-of-the-art performance of the proposed TPO. For example, by building on top of LLAVA-1.5-7B, our TPO boosts the performance absolute improvement for hallucination benchmarks.