Llama Learns to Direct: DirectorLLM for Human-Centric Video Generation
作者: Kunpeng Song, Tingbo Hou, Zecheng He, Haoyu Ma, Jialiang Wang, Animesh Sinha, Sam Tsai, Yaqiao Luo, Xiaoliang Dai, Li Chen, Xide Xia, Peizhao Zhang, Peter Vajda, Ahmed Elgammal, Felix Juefei-Xu
分类: cs.CV
发布日期: 2024-12-19 (更新: 2025-09-08)
💡 一句话要点
提出DirectorLLM,利用LLM编排人体姿态,提升人本视频生成质量
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频生成 大型语言模型 人体姿态估计 条件生成 人本视频 运动模拟 Llama 3
📋 核心要点
- 现有文本到视频模型在生成高质量人体运动和交互方面存在挑战,难以保证真实性和可控性。
- DirectorLLM利用LLM生成人体姿态等指导信号,将人体运动模拟从视频生成器转移到LLM,实现更精细的控制。
- 实验表明,DirectorLLM在人体运动保真度、提示忠实度和渲染对象自然度方面均优于现有模型。
📝 摘要(中文)
本文介绍了一种新颖的视频生成模型DirectorLLM,该模型利用大型语言模型(LLM)来编排视频中的人体姿态。随着基础文本到视频模型的快速发展,对高质量人体运动和交互的需求日益增长。为了满足这一需求并增强人体运动的真实性,我们将LLM从文本生成器扩展到视频导演和人体运动模拟器。我们利用Llama 3的开源资源,训练DirectorLLM生成详细的指导信号,例如人体姿势,以指导视频生成。这种方法将人体运动的模拟从视频生成器转移到LLM,有效地创建了以人为中心的场景的信息性轮廓。这些信号被视频渲染器用作条件,从而促进了更逼真和符合提示的视频生成。作为一个独立的LLM模块,它可以以最小的努力应用于不同的视频渲染器,包括UNet和DiT。在自动评估基准和人工评估上的实验表明,我们的模型在生成具有更高人体运动保真度、改进的提示忠实度和增强的渲染对象自然度的视频方面优于现有模型。
🔬 方法详解
问题定义:当前文本到视频生成模型在处理包含人类角色的视频时,难以生成逼真且符合用户指令的人体运动。现有的方法通常将人体运动的生成与场景的整体生成耦合在一起,导致控制粒度不足,难以实现对人体姿态、动作和交互的精确控制。这限制了生成视频的真实感和用户可控性。
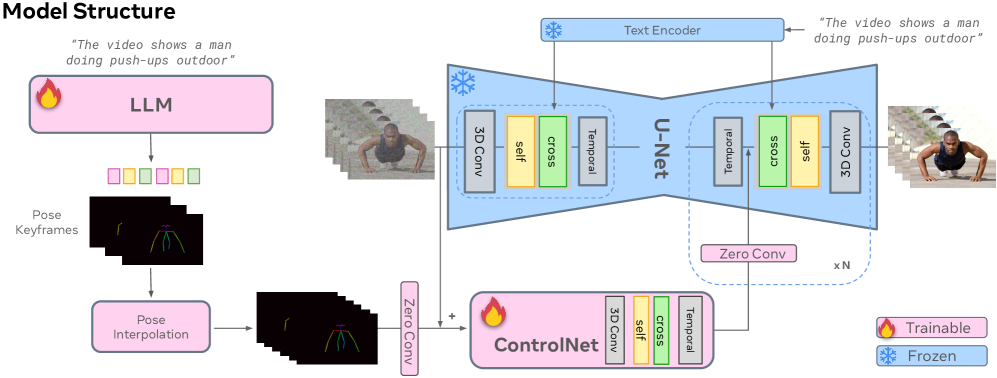
核心思路:DirectorLLM的核心思路是将人体运动的生成与视频场景的渲染解耦。通过利用大型语言模型(LLM)作为“导演”,生成详细的人体姿态指导信号,从而引导视频生成器生成更逼真的人体运动。这种解耦使得可以独立地控制人体运动,并将其作为条件输入到视频生成器中,从而提高生成视频的质量和可控性。
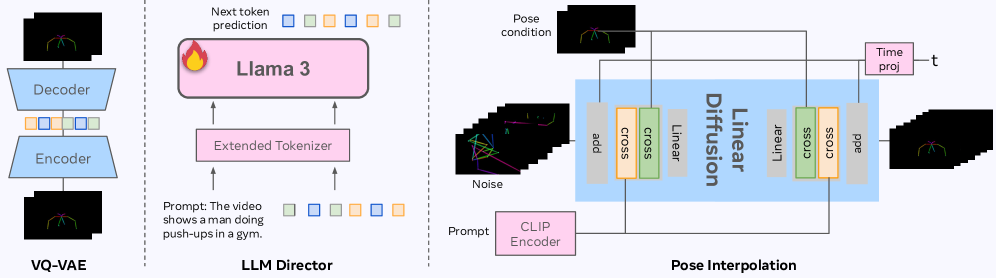
技术框架:DirectorLLM的整体框架包含两个主要模块:DirectorLLM(基于LLM的人体运动指导信号生成器)和视频渲染器(例如UNet或DiT)。首先,DirectorLLM接收文本提示,并生成一系列详细的指导信号,包括人体姿态、动作描述等。然后,这些指导信号被传递给视频渲染器,作为条件来生成最终的视频。DirectorLLM作为一个独立的模块,可以灵活地与不同的视频渲染器集成。
关键创新:DirectorLLM的关键创新在于利用LLM来模拟和控制人体运动,从而将人体运动的生成从视频生成器中解耦出来。这种方法允许更精细地控制人体姿态和动作,并提高生成视频的真实感和用户可控性。与现有方法相比,DirectorLLM能够生成更符合用户指令且具有更高质量人体运动的视频。
关键设计:DirectorLLM基于Llama 3进行训练,使用大量的人体运动数据进行微调,使其能够生成准确且连贯的人体姿态序列。指导信号包括人体关键点坐标、动作描述等。视频渲染器可以使用这些指导信号作为条件,通过条件生成的方式生成最终的视频。损失函数的设计旨在鼓励生成器生成符合指导信号的视频,并保持视频的整体一致性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,DirectorLLM在自动评估基准和人工评估中均优于现有模型。在人体运动保真度方面,DirectorLLM生成的视频具有更自然、更逼真的人体运动。在提示忠实度方面,DirectorLLM能够更好地遵循用户指令,生成符合用户期望的视频内容。在渲染对象自然度方面,DirectorLLM生成的视频具有更逼真的视觉效果。
🎯 应用场景
DirectorLLM具有广泛的应用前景,包括电影制作、游戏开发、虚拟现实、教育娱乐等领域。它可以用于生成逼真的人体动画、创建交互式虚拟角色、以及开发个性化的教育内容。通过提高视频生成中人体运动的真实感和可控性,DirectorLLM可以为用户提供更丰富、更沉浸式的体验。
📄 摘要(原文)
In this paper, we introduce DirectorLLM, a novel video generation model that employs a large language model (LLM) to orchestrate human poses within videos. As foundational text-to-video models rapidly evolve, the demand for high-quality human motion and interaction grows. To address this need and enhance the authenticity of human motions, we extend the LLM from a text generator to a video director and human motion simulator. Utilizing open-source resources from Llama 3, we train the DirectorLLM to generate detailed instructional signals, such as human poses, to guide video generation. This approach offloads the simulation of human motion from the video generator to the LLM, effectively creating informative outlines for human-centric scenes. These signals are used as conditions by the video renderer, facilitating more realistic and prompt-following video generation. As an independent LLM module, it can be applied to different video renderers, including UNet and DiT, with minimal effort. Experiments on automatic evaluation benchmarks and human evaluations show that our model outperforms existing ones in generating videos with higher human motion fidelity, improved prompt faithfulness, and enhanced rendered subject naturalness.