Multimodal Latent Diffusion Model for Complex Sewing Pattern Generation
作者: Shengqi Liu, Yuhao Cheng, Zhuo Chen, Xingyu Ren, Wenhan Zhu, Lincheng Li, Mengxiao Bi, Xiaokang Yang, Yichao Yan
分类: cs.CV, cs.GR, cs.LG
发布日期: 2024-12-19 (更新: 2025-07-07)
备注: Our project page: https://shengqiliu1.github.io/SewingLDM
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出 SewingLDM,用于生成受文本、体型和草图控制的复杂缝纫图案
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 缝纫图案生成 多模态学习 扩散模型 服装设计 潜在空间 条件生成 身体适应性
📋 核心要点
- 现有缝纫图案生成方法难以设计具有细节控制的复杂服装,限制了其应用。
- SewingLDM 通过多模态扩散模型,融合文本、体型和草图信息,实现对缝纫图案的精细控制。
- 实验结果表明,SewingLDM 在复杂服装设计和身体适应性方面显著优于现有方法。
📝 摘要(中文)
本文提出 SewingLDM,一种多模态生成模型,用于生成受文本提示、体型和服装草图控制的缝纫图案。为了应对现有方法在设计具有细节控制的复杂服装方面的不足,我们首先将缝纫图案的原始向量扩展为更全面的表示,以覆盖更复杂的细节,然后将其压缩到紧凑的潜在空间中。为了学习潜在空间中的缝纫图案分布,我们设计了一个两步训练策略,将多模态条件(即体型、文本提示和服装草图)注入到扩散模型中,确保生成的服装适合体型并受细节控制。全面的定性和定量实验表明,我们提出的方法是有效的,在复杂服装设计和各种身体适应性方面显著超过了以前的方法。
🔬 方法详解
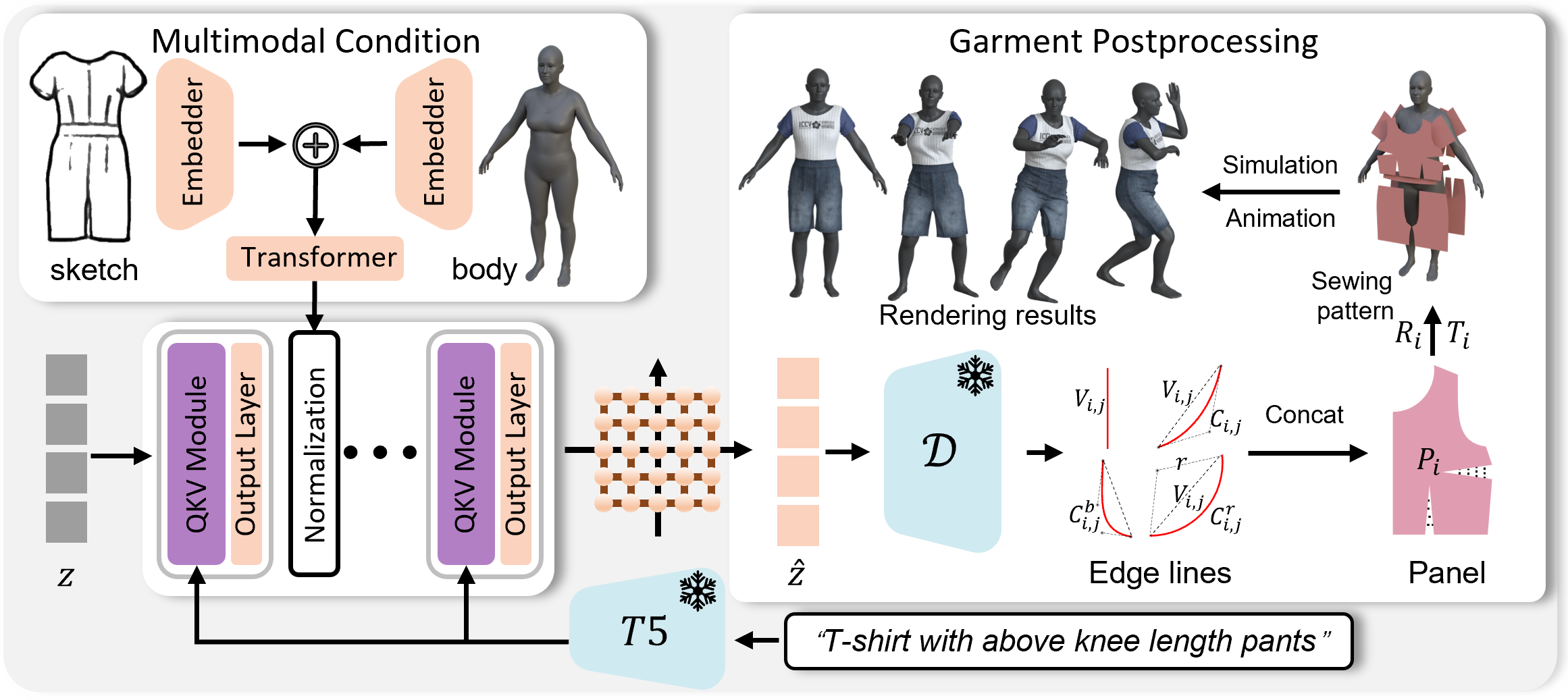
问题定义:现有缝纫图案生成方法难以生成具有复杂细节和精细控制的服装,尤其是在需要考虑体型适配和设计意图表达时。痛点在于缺乏一种能够有效融合多种模态信息,并生成高质量、可定制缝纫图案的通用框架。
核心思路:SewingLDM 的核心思路是将缝纫图案生成问题转化为一个多模态条件下的潜在扩散模型学习问题。通过将缝纫图案压缩到潜在空间,并利用文本提示、体型和服装草图等多模态信息作为条件,引导扩散模型生成符合要求的缝纫图案。这种方法能够有效利用不同模态信息的互补性,提高生成结果的质量和可控性。
技术框架:SewingLDM 的整体框架包含以下几个主要模块:1) 缝纫图案表示模块:将原始缝纫图案向量扩展为更全面的表示,以捕捉更精细的细节。2) 潜在空间编码器:将扩展后的缝纫图案表示压缩到紧凑的潜在空间。3) 多模态条件编码器:将文本提示、体型和服装草图等模态信息编码为潜在向量。4) 扩散模型:在潜在空间中学习缝纫图案的分布,并根据多模态条件生成新的缝纫图案。5) 潜在空间解码器:将生成的潜在向量解码为缝纫图案。
关键创新:SewingLDM 的关键创新在于其多模态融合和两步训练策略。通过将文本、体型和草图信息融入扩散模型,实现了对缝纫图案的精细控制。两步训练策略首先学习缝纫图案的潜在空间表示,然后将多模态条件注入扩散模型,从而提高了生成结果的质量和稳定性。与现有方法相比,SewingLDM 能够生成更复杂、更具细节的缝纫图案,并更好地适应不同的体型和设计要求。
关键设计:SewingLDM 采用了一种两步训练策略。第一步,训练一个自编码器,将缝纫图案压缩到潜在空间。第二步,训练一个条件扩散模型,以多模态信息作为条件,生成潜在空间中的缝纫图案表示。损失函数包括重构损失、对抗损失和条件损失。网络结构包括卷积神经网络、Transformer 和扩散模型。
🖼️ 关键图片


📊 实验亮点
实验结果表明,SewingLDM 在复杂服装设计和身体适应性方面显著优于现有方法。定性结果展示了 SewingLDM 生成的缝纫图案具有更高的细节和更强的可控性。定量结果表明,SewingLDM 在多个指标上都取得了显著提升,例如在服装相似度指标上优于现有方法 10% 以上。
🎯 应用场景
SewingLDM 可应用于服装设计、虚拟试衣、个性化定制等领域。设计师可以利用该模型快速生成各种款式的缝纫图案,并根据客户的体型和偏好进行调整。该模型还可以用于虚拟试衣平台,让用户在线体验不同服装的穿着效果。此外,SewingLDM 还可以促进服装行业的数字化转型,提高生产效率和降低成本。
📄 摘要(原文)
Generating sewing patterns in garment design is receiving increasing attention due to its CG-friendly and flexible-editing nature. Previous sewing pattern generation methods have been able to produce exquisite clothing, but struggle to design complex garments with detailed control. To address these issues, we propose SewingLDM, a multi-modal generative model that generates sewing patterns controlled by text prompts, body shapes, and garment sketches. Initially, we extend the original vector of sewing patterns into a more comprehensive representation to cover more intricate details and then compress them into a compact latent space. To learn the sewing pattern distribution in the latent space, we design a two-step training strategy to inject the multi-modal conditions, \ie, body shapes, text prompts, and garment sketches, into a diffusion model, ensuring the generated garments are body-suited and detail-controlled. Comprehensive qualitative and quantitative experiments show the effectiveness of our proposed method, significantly surpassing previous approaches in terms of complex garment design and various body adaptability. Our project page: https://shengqiliu1.github.io/SewingLDM.