Thinking in Space: How Multimodal Large Language Models See, Remember, and Recall Spaces
作者: Jihan Yang, Shusheng Yang, Anjali W. Gupta, Rilyn Han, Li Fei-Fei, Saining Xie
分类: cs.CV
发布日期: 2024-12-18 (更新: 2025-07-02)
备注: Project page: https://vision-x-nyu.github.io/thinking-in-space.github.io/
💡 一句话要点
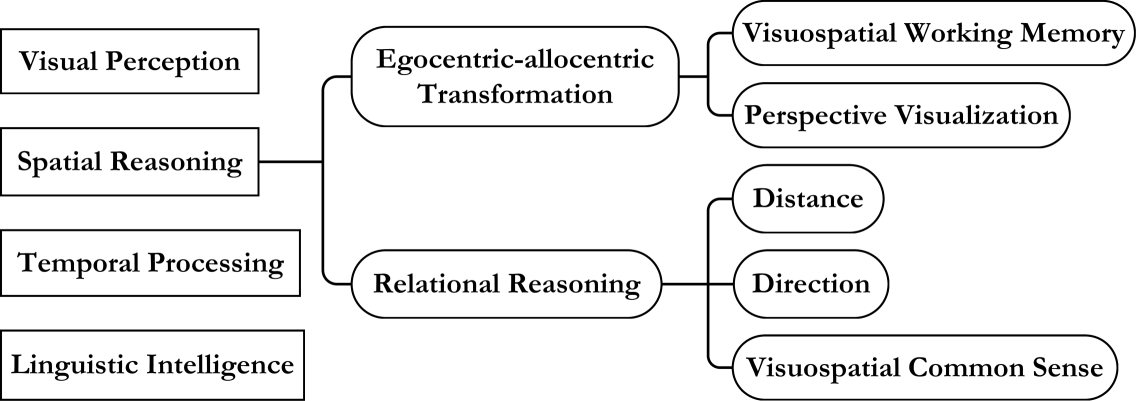
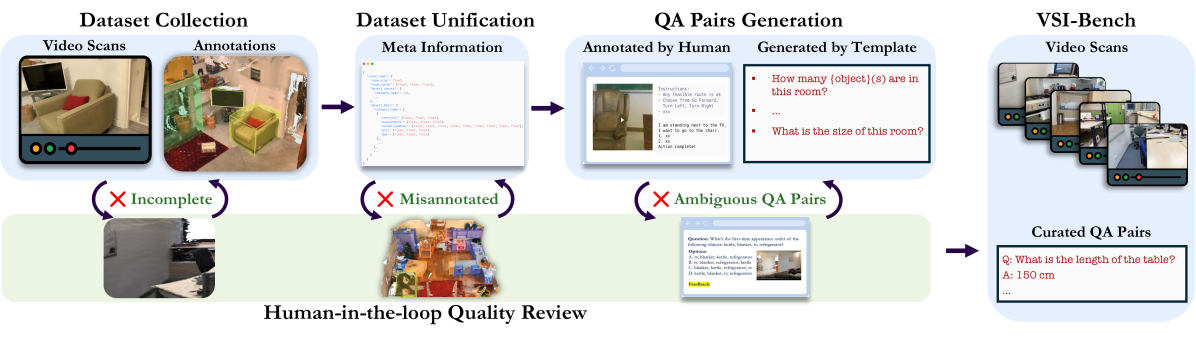
提出VSI-Bench基准测试MLLM在视频中进行视觉空间推理的能力,并探索认知地图生成方法。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大型语言模型 视觉空间推理 认知地图 视频理解 基准测试
📋 核心要点
- 现有的MLLM在处理视觉空间推理任务时存在不足,难以像人类一样从视频中理解和记忆空间信息。
- 论文提出VSI-Bench基准测试,并探索通过显式生成认知地图来提升MLLM的空间推理能力。
- 实验表明,MLLM在VSI-Bench上表现出一定的视觉空间智能,但仍低于人类水平,认知地图生成能有效提升空间距离计算能力。
📝 摘要(中文)
人类具备从连续视觉观察中记忆空间信息的视觉空间智能。本文旨在探究在百万级视频数据集上训练的多模态大型语言模型(MLLM)是否也能从视频中进行“空间思考”。为此,作者提出了一个新颖的基于视频的视觉空间智能基准测试(VSI-Bench),包含超过5000个问答对。研究发现,MLLM表现出具有竞争力的,但低于人类水平的视觉空间智能。通过语言和视觉方式探究模型如何进行空间思考,发现空间推理能力仍然是MLLM达到更高基准性能的主要瓶颈,但局部世界模型和空间感知确实在这些模型中涌现。值得注意的是,流行的语言推理技术(例如,思维链、自我一致性、思维树)未能提高性能,而显式生成认知地图在问答过程中增强了MLLM的空间距离能力。
🔬 方法详解
问题定义:论文旨在评估和提升多模态大型语言模型(MLLM)在视频中进行视觉空间推理的能力。现有方法,如直接使用MLLM进行问答,或采用思维链等语言推理技巧,在空间推理任务上表现不佳,无法有效利用视频中的空间信息。痛点在于MLLM缺乏对空间关系的显式建模和推理能力。
核心思路:论文的核心思路是通过显式地让MLLM生成认知地图,从而增强其空间推理能力。认知地图是一种对环境的空间表示,可以帮助模型更好地理解和记忆空间关系,从而更准确地回答关于空间的问题。这种方法模拟了人类在空间推理时构建心理地图的过程。
技术框架:整体框架包含视频输入、特征提取、认知地图生成和问答四个主要阶段。首先,从视频中提取视觉特征。然后,利用MLLM根据视觉特征生成认知地图,认知地图可以是一种结构化的空间表示,例如节点和边的图结构,节点代表地点,边代表地点之间的关系。最后,将问题和认知地图输入MLLM,让其根据认知地图进行推理并生成答案。
关键创新:最重要的技术创新点在于显式地将认知地图引入到MLLM的视觉空间推理过程中。与以往直接使用MLLM进行问答的方法不同,该方法通过中间的认知地图生成步骤,让模型能够更好地理解和记忆空间信息,从而提高推理的准确性。
关键设计:认知地图的具体表示形式未知,可能采用图结构或其他空间表示方法。损失函数的设计也未知,可能包括鼓励认知地图与视频内容一致的损失项,以及鼓励认知地图能够有效支持问答的损失项。具体的网络结构细节也未知,但可以推测使用了Transformer等模型来处理视频特征和生成认知地图。
🖼️ 关键图片

📊 实验亮点
实验结果表明,MLLM在VSI-Bench基准测试上表现出一定的视觉空间智能,但仍低于人类水平。通过显式生成认知地图,MLLM的空间距离计算能力得到了显著提升。虽然具体的性能提升幅度未知,但该方法为提升MLLM的视觉空间推理能力提供了一种有效的途径。流行的语言推理技术(例如,思维链、自我一致性、思维树)未能提高性能,进一步验证了空间推理的特殊性。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、虚拟现实等领域。例如,机器人可以利用该方法理解周围环境,进行自主导航;自动驾驶系统可以更好地理解交通场景,提高驾驶安全性;虚拟现实应用可以提供更逼真的空间体验。此外,该研究还可以促进对人类空间认知机制的理解。
📄 摘要(原文)
Humans possess the visual-spatial intelligence to remember spaces from sequential visual observations. However, can Multimodal Large Language Models (MLLMs) trained on million-scale video datasets also ``think in space'' from videos? We present a novel video-based visual-spatial intelligence benchmark (VSI-Bench) of over 5,000 question-answer pairs, and find that MLLMs exhibit competitive - though subhuman - visual-spatial intelligence. We probe models to express how they think in space both linguistically and visually and find that while spatial reasoning capabilities remain the primary bottleneck for MLLMs to reach higher benchmark performance, local world models and spatial awareness do emerge within these models. Notably, prevailing linguistic reasoning techniques (e.g., chain-of-thought, self-consistency, tree-of-thoughts) fail to improve performance, whereas explicitly generating cognitive maps during question-answering enhances MLLMs' spatial distance ability.