A Simple yet Effective Test-Time Adaptation for Zero-Shot Monocular Metric Depth Estimation
作者: Rémi Marsal, Alexandre Chapoutot, Philippe Xu, David Filliat
分类: cs.CV
发布日期: 2024-12-18 (更新: 2025-11-28)
备注: Published at IROS 2025 https://ieeexplore.ieee.org/document/11247168
期刊: 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 7858-7865
DOI: 10.1109/IROS60139.2025.11247168
💡 一句话要点
提出一种简单有效的测试时适应方法以解决零-shot单目度量深度估计问题
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 单目深度估计 零-shot学习 深度重标定 传感器融合 鲁棒性 基础模型 自动驾驶
📋 核心要点
- 现有的零-shot单目深度估计方法通常需要复杂的微调过程,这不仅耗时且可能降低模型的泛化能力。
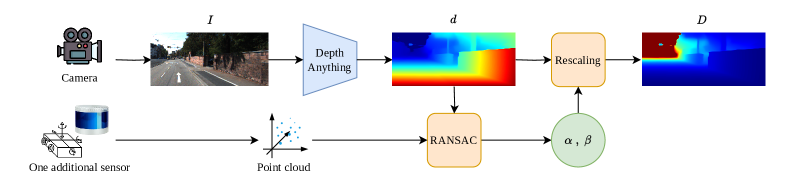
- 本文提出了一种通过3D点重新缩放Depth Anything预测的方法,避免了微调并保持了模型的泛化能力。
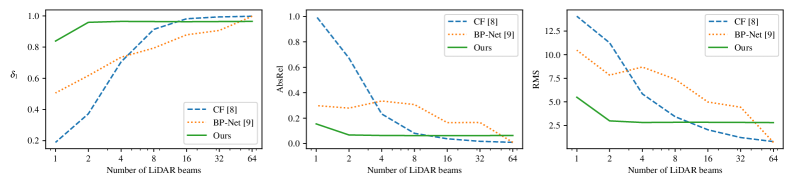
- 实验结果显示,所提方法在零-shot单目度量深度估计中相较于现有方法有显著提升,并且在鲁棒性上优于深度补全方法。
📝 摘要(中文)
近年来,基础模型在单目深度估计中的发展,如Depth Anything,为零-shot单目深度估计铺平了道路。现有方法通常需要对模型进行微调,但这一过程复杂且耗时,且可能会降低模型的泛化能力。本文提出了一种新方法,通过使用传感器提供的3D点(如低分辨率LiDAR或运动结构技术)来重新缩放Depth Anything的预测,避免了微调,同时保持了原始深度估计模型的泛化能力,并对稀疏深度、相机-LiDAR校准及深度模型的噪声具有较强的鲁棒性。实验结果表明,该方法在零-shot单目度量深度估计中相较于现有方法有显著提升,并且在与微调方法的比较中表现出竞争力。
🔬 方法详解
问题定义:现有的零-shot单目深度估计方法通常依赖于微调模型来恢复度量深度,这一过程复杂且耗时,且可能导致模型泛化能力的下降。
核心思路:本文提出了一种新的方法,通过使用传感器或低分辨率LiDAR等技术提供的3D点来重新缩放Depth Anything的预测,避免了微调的需要,同时保持了模型的泛化能力。
技术框架:整体方法包括三个主要模块:首先,利用Depth Anything生成初步的深度预测;其次,结合传感器提供的3D点进行深度预测的重新缩放;最后,评估和验证模型在不同场景下的鲁棒性。
关键创新:最重要的技术创新在于通过3D点的引入,实现了对深度预测的有效重标定,避免了传统方法中的微调过程,从而保持了模型的泛化能力。
关键设计:在参数设置上,使用了与Depth Anything兼容的损失函数,并在网络结构中引入了对3D点的处理模块,以增强模型对稀疏深度数据的鲁棒性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,所提方法在零-shot单目度量深度估计中相较于现有方法有显著提升,尤其是在鲁棒性方面表现优异。与微调方法相比,所提方法在多个测试场景中均展现出竞争力,具体性能数据未提供,但提升幅度明显。
🎯 应用场景
该研究的潜在应用领域包括自动驾驶、机器人导航和增强现实等场景,能够在不依赖大量标注数据的情况下,实现高效的深度估计。这将大大降低实际应用中的数据准备成本,并提高系统的适应性和灵活性。
📄 摘要(原文)
The recent development of \emph{foundation models} for monocular depth estimation such as Depth Anything paved the way to zero-shot monocular depth estimation. Since it returns an affine-invariant disparity map, the favored technique to recover the metric depth consists in fine-tuning the model. However, this stage is not straightforward, it can be costly and time-consuming because of the training and the creation of the dataset. The latter must contain images captured by the camera that will be used at test time and the corresponding ground truth. Moreover, the fine-tuning may also degrade the generalizing capacity of the original model. Instead, we propose in this paper a new method to rescale Depth Anything predictions using 3D points provided by sensors or techniques such as low-resolution LiDAR or structure-from-motion with poses given by an IMU. This approach avoids fine-tuning and preserves the generalizing power of the original depth estimation model while being robust to the noise of the sparse depth, of the camera-LiDAR calibration or of the depth model. Our experiments highlight enhancements relative to zero-shot monocular metric depth estimation methods, competitive results compared to fine-tuned approaches and a better robustness than depth completion approaches. Code available at github.com/ENSTA-U2IS-AI/depth-rescaling.