LLaVA-UHD v2: an MLLM Integrating High-Resolution Semantic Pyramid via Hierarchical Window Transformer
作者: Yipeng Zhang, Yifan Liu, Zonghao Guo, Yidan Zhang, Xuesong Yang, Xiaoying Zhang, Chi Chen, Jun Song, Bo Zheng, Yuan Yao, Zhiyuan Liu, Tat-Seng Chua, Maosong Sun
分类: cs.CV
发布日期: 2024-12-18 (更新: 2025-03-19)
💡 一句话要点
LLaVA-UHD v2:通过分层窗口Transformer集成高分辨率语义金字塔的多模态大语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉Transformer 细粒度视觉感知 分层窗口Transformer 语义金字塔
📋 核心要点
- 现有的基于视觉Transformer的MLLM在细粒度视觉感知任务中表现不佳,原因是它们在捕获多层次视觉信息(如低级细节)方面存在局限性。
- LLaVA-UHD v2通过引入Hiwin Transformer来解决这个问题,该Transformer能够捕获多样化的多模态视觉粒度,并构建高分辨率语义金字塔。
- 实验结果表明,LLaVA-UHD v2在多个基准测试中优于其他MLLM,平均提升了3.7%,在DocVQA上提升了9.3%。
📝 摘要(中文)
本文提出LLaVA-UHD v2,一个具有先进感知能力的多模态大语言模型(MLLM),通过引入精心设计的视觉-语言投影器——分层窗口(Hiwin)Transformer。Hiwin Transformer通过整合构建的高分辨率语义金字塔,增强了MLLM捕获多样多模态视觉粒度的能力,解决了视觉Transformer在细粒度视觉感知任务上的不足。具体来说,Hiwin Transformer包含两个关键模块:(i)视觉细节注入模块,将低级视觉细节逐步注入到高级语言对齐的语义特征中,从而形成逆语义金字塔(ISP);(ii)分层窗口注意力模块,利用跨尺度窗口从ISP中提取多层次语义。大量实验表明,LLaVA-UHD v2在各种基准测试中优于其他MLLM。值得注意的是,与基线方法相比,我们的设计在14个基准测试中平均提升了3.7%,例如在DocVQA上提升了9.3%。所有数据和代码将公开发布,以促进未来的研究。
🔬 方法详解
问题定义:现有的多模态大语言模型(MLLM)在处理需要细粒度视觉感知的任务时表现不佳。这主要是因为视觉Transformer(ViT)在捕获不同层次的视觉信息,特别是低层次的细节信息时存在局限性。因此,如何提升MLLM对细粒度视觉信息的感知能力是一个关键问题。
核心思路:论文的核心思路是通过构建一个高分辨率的语义金字塔,并设计一个能够有效利用该金字塔的视觉-语言投影器,即Hiwin Transformer,来增强MLLM对多层次视觉信息的感知能力。通过逐步将低级视觉细节注入到高级语义特征中,形成逆语义金字塔(ISP),从而保留更多的细节信息。
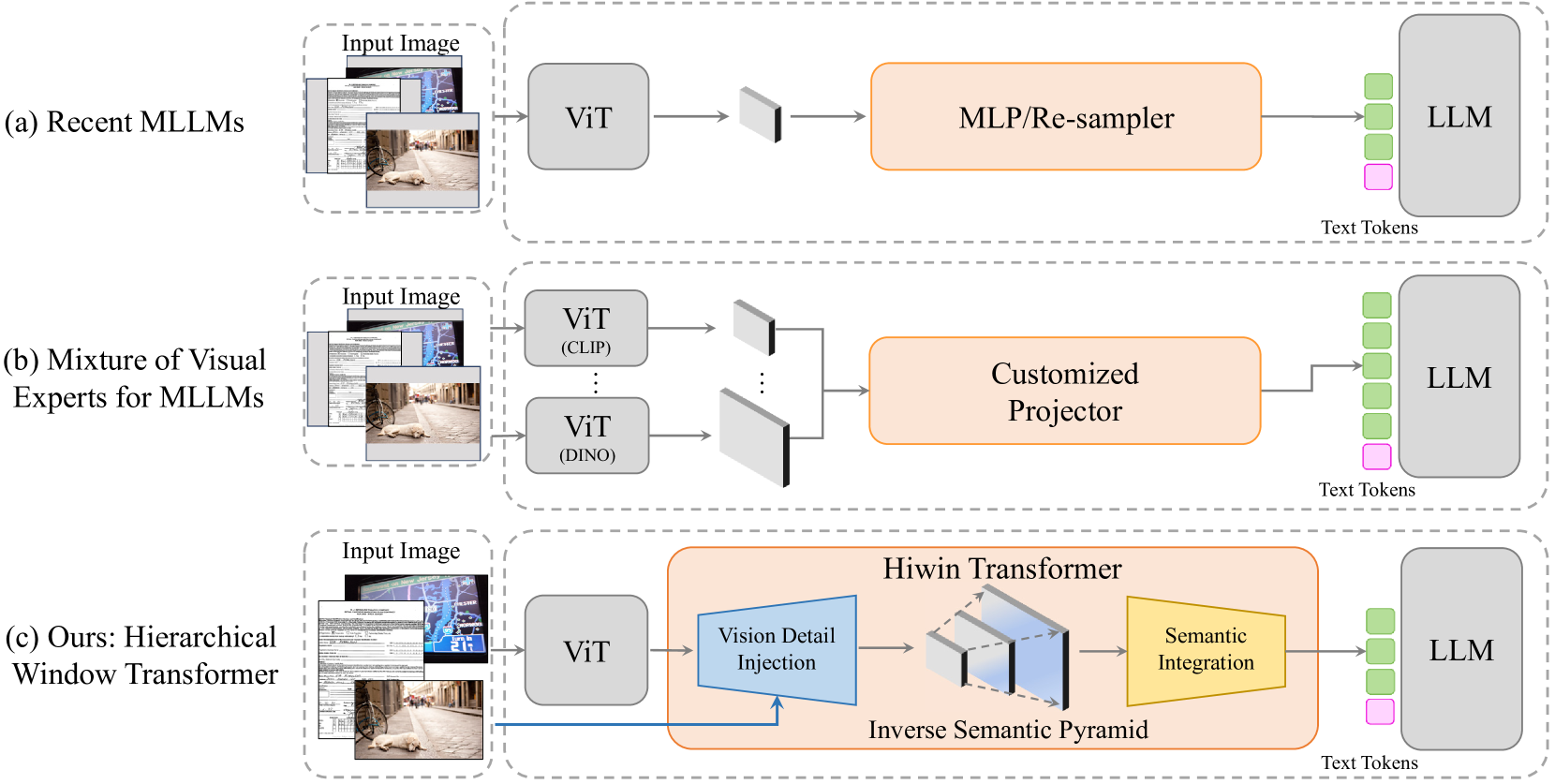
技术框架:LLaVA-UHD v2的整体框架包括一个视觉编码器(通常是ViT),一个Hiwin Transformer作为视觉-语言投影器,以及一个大型语言模型(LLM)。视觉编码器提取图像特征,Hiwin Transformer将视觉特征投影到语言模型的语义空间,并融合多层次的视觉信息,最后LLM根据融合后的特征生成文本。Hiwin Transformer是该框架的核心模块。
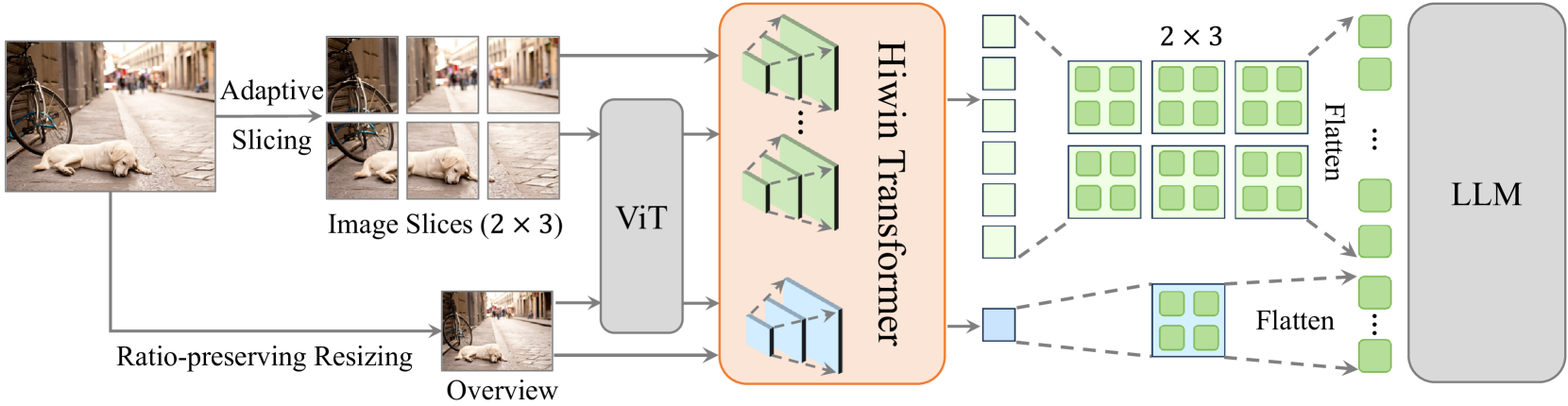
关键创新:论文的关键创新在于Hiwin Transformer的设计,它包含两个主要模块:视觉细节注入模块和分层窗口注意力模块。视觉细节注入模块通过逐步注入低级视觉细节到高级语义特征中,构建逆语义金字塔(ISP)。分层窗口注意力模块则利用跨尺度的窗口,从ISP中提取多层次的语义信息。这种设计使得模型能够同时关注全局语义信息和局部细节信息。
关键设计:视觉细节注入模块采用逐步融合的方式,将低层特征图的细节信息注入到高层特征图中,形成ISP。分层窗口注意力模块则将特征图划分为不同大小的窗口,并在每个窗口内进行自注意力计算,从而捕获不同尺度的语义信息。具体的窗口大小和数量需要根据实验进行调整。损失函数通常采用标准的交叉熵损失或对比学习损失,以优化视觉-语言对齐。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LLaVA-UHD v2在多个基准测试中取得了显著的性能提升。例如,在14个基准测试中,LLaVA-UHD v2的平均性能提升了3.7%,在DocVQA任务中提升了9.3%。这些结果表明,Hiwin Transformer能够有效地提升MLLM对细粒度视觉信息的感知能力。
🎯 应用场景
LLaVA-UHD v2在需要细粒度视觉感知的多模态任务中具有广泛的应用前景,例如文档视觉问答(DocVQA)、细粒度图像分类、医学图像诊断、遥感图像分析等。该研究可以提升机器对复杂视觉场景的理解能力,从而在实际应用中提供更准确、更可靠的决策支持。
📄 摘要(原文)
Vision transformers (ViTs) are widely employed in multimodal large language models (MLLMs) for visual encoding. However, they exhibit inferior performance on tasks regarding fine-grained visual perception. We attribute this to the limitations of ViTs in capturing diverse multi-modal visual levels, such as low-level details. To address this issue, we present LLaVA-UHD v2, an MLLM with advanced perception abilities by introducing a well-designed vision-language projector, the Hierarchical window (Hiwin) transformer. Hiwin transformer enhances MLLM's ability to capture diverse multi-modal visual granularities, by incorporating our constructed high-resolution semantic pyramid. Specifically, Hiwin transformer comprises two key modules: (i) a visual detail injection module, which progressively injects low-level visual details into high-level language-aligned semantics features, thereby forming an inverse semantic pyramid (ISP), and (ii) a hierarchical window attention module, which leverages cross-scale windows to condense multi-level semantics from the ISP. Extensive experiments show that LLaVA-UHD v2 outperforms compared MLLMs on a wide range of benchmarks. Notably, our design achieves an average boost of 3.7% across 14 benchmarks compared with the baseline method, 9.3% on DocVQA for instance. All the data and code will be publicly available to facilitate future research.