Motion-2-to-3: Leveraging 2D Motion Data to Boost 3D Motion Generation
作者: Huaijin Pi, Ruoxi Guo, Zehong Shen, Qing Shuai, Zechen Hu, Zhumei Wang, Yajiao Dong, Ruizhen Hu, Taku Komura, Sida Peng, Xiaowei Zhou
分类: cs.CV, cs.GR
发布日期: 2024-12-17
备注: Project page: https://zju3dv.github.io/Motion-2-to-3/
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出Motion-2-to-3框架,利用2D运动数据提升文本驱动的3D人体运动生成效果
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 文本驱动运动生成 3D人体运动 2D运动数据 运动解耦 Transformer
📋 核心要点
- 现有文本驱动的3D运动生成方法依赖昂贵的3D动捕数据,限制了运动的多样性和范围。
- 提出Motion-2-to-3框架,通过解耦局部和全局运动,利用易获取的2D视频数据学习运动先验。
- 实验表明,该方法能有效利用2D数据生成逼真的3D运动,并扩展了可生成的运动类型。
📝 摘要(中文)
本文提出了一种利用2D人体运动数据来提升文本驱动的3D运动生成的新框架。现有方法依赖于3D运动捕捉数据,数据获取成本高,限制了运动的多样性。相比之下,2D人体视频提供了更广泛和易于获取的运动数据来源。该方法将局部关节运动与全局运动解耦,从而能够有效地从2D数据中学习局部运动先验。首先,在大量的文本-运动对数据集上训练一个单视角2D局部运动生成器。然后,使用3D数据对该生成器进行微调,将其转换为多视角生成器,预测视角一致的局部关节运动和根部动态。在HumanML3D数据集和新的文本提示上的实验表明,该方法能够有效地利用2D数据,支持逼真的3D人体运动生成,并扩大了其支持的运动类型范围。
🔬 方法详解
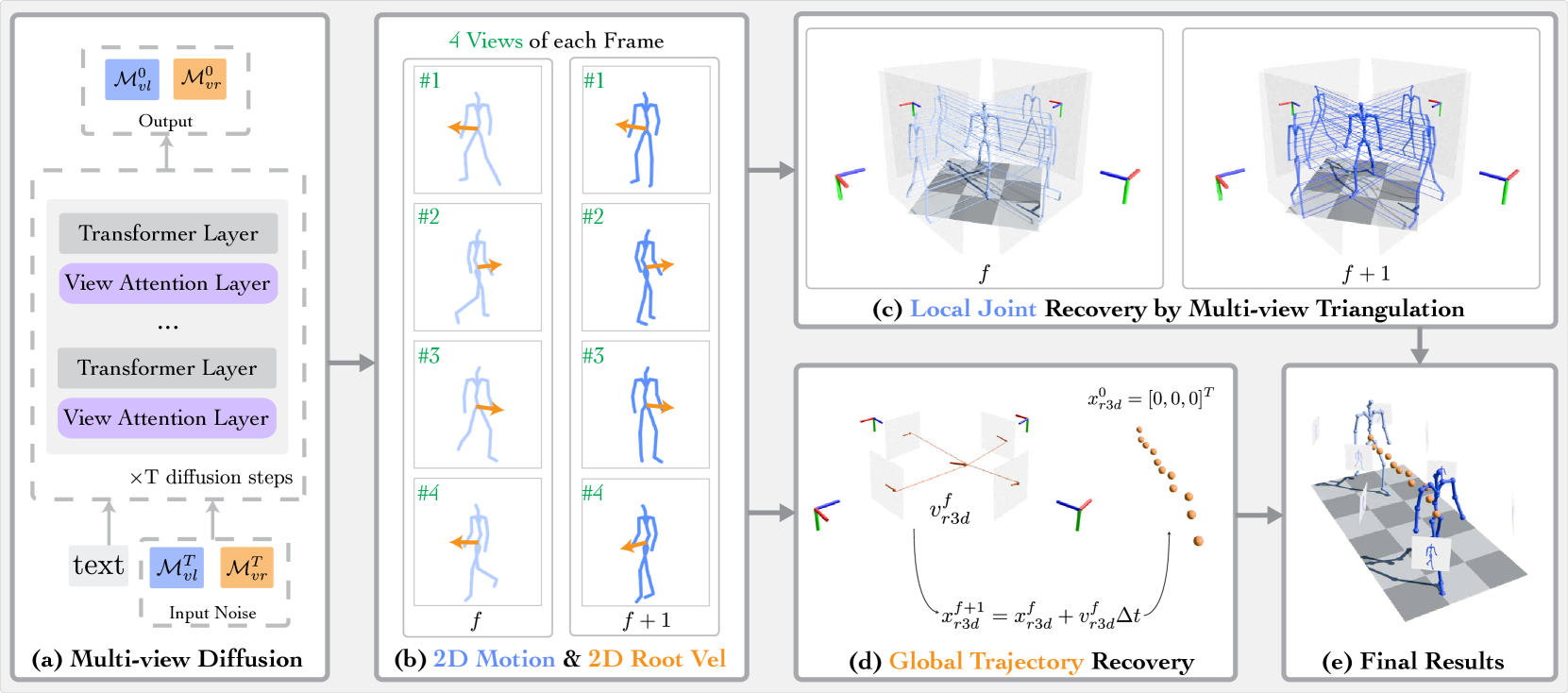
问题定义:现有文本驱动的3D人体运动生成方法主要依赖于3D运动捕捉数据,这些数据获取成本高昂,限制了数据集的规模和多样性。因此,如何利用更易获取的2D运动数据来提升3D运动生成的效果是一个关键问题。现有方法难以有效利用2D数据,因为2D数据缺乏深度信息,且视角变化较大。
核心思路:论文的核心思路是将3D运动生成问题分解为局部关节运动和全局运动两部分。首先,利用大量的2D视频数据学习局部关节运动的先验知识。然后,通过少量3D数据微调模型,使其能够生成视角一致的3D局部关节运动和根部动态。这种解耦的方式能够有效地利用2D数据的优势,同时克服其局限性。
技术框架:该框架包含两个主要阶段:2D局部运动生成器训练和3D运动生成器微调。在第一阶段,使用大量的文本-2D运动对数据训练一个单视角2D局部运动生成器。在第二阶段,使用3D数据对该生成器进行微调,使其能够预测视角一致的3D局部关节运动和根部动态。整个框架采用Transformer架构,将文本编码和运动序列作为输入,生成相应的运动序列。
关键创新:该方法最重要的技术创新点在于将2D运动数据引入到3D运动生成任务中,并提出了一种有效的利用2D数据的方法。通过解耦局部关节运动和全局运动,该方法能够有效地学习2D运动的先验知识,并将其迁移到3D运动生成任务中。与现有方法相比,该方法能够利用更广泛的2D数据,从而生成更丰富和多样的3D运动。
关键设计:在2D局部运动生成器训练阶段,使用了大量的文本-2D运动对数据,并采用对抗训练的方式来提高生成运动的真实性。在3D运动生成器微调阶段,使用了3D运动捕捉数据,并设计了一个视角一致性损失函数来保证生成的多视角运动的一致性。此外,还使用了运动平滑损失函数来提高生成运动的平滑度。
🖼️ 关键图片


📊 实验亮点
该方法在HumanML3D数据集上进行了实验,结果表明,该方法能够有效地利用2D数据,生成逼真的3D人体运动。与现有方法相比,该方法能够生成更丰富和多样的运动类型。此外,该方法还能够根据新的文本提示生成合理的3D运动,表明其具有良好的泛化能力。具体性能数据未知,但论文强调了利用2D数据扩展运动类型范围的优势。
🎯 应用场景
该研究成果可广泛应用于电影、游戏、虚拟现实等领域。例如,可以根据剧本自动生成角色的运动,降低动画制作成本;也可以在虚拟现实游戏中,根据用户的文本指令生成虚拟角色的动作,增强用户的沉浸感。此外,该技术还可以应用于康复训练、运动分析等领域,具有广阔的应用前景。
📄 摘要(原文)
Text-driven human motion synthesis is capturing significant attention for its ability to effortlessly generate intricate movements from abstract text cues, showcasing its potential for revolutionizing motion design not only in film narratives but also in virtual reality experiences and computer game development. Existing methods often rely on 3D motion capture data, which require special setups resulting in higher costs for data acquisition, ultimately limiting the diversity and scope of human motion. In contrast, 2D human videos offer a vast and accessible source of motion data, covering a wider range of styles and activities. In this paper, we explore leveraging 2D human motion extracted from videos as an alternative data source to improve text-driven 3D motion generation. Our approach introduces a novel framework that disentangles local joint motion from global movements, enabling efficient learning of local motion priors from 2D data. We first train a single-view 2D local motion generator on a large dataset of text-motion pairs. To enhance this model to synthesize 3D motion, we fine-tune the generator with 3D data, transforming it into a multi-view generator that predicts view-consistent local joint motion and root dynamics. Experiments on the HumanML3D dataset and novel text prompts demonstrate that our method efficiently utilizes 2D data, supporting realistic 3D human motion generation and broadening the range of motion types it supports. Our code will be made publicly available at https://zju3dv.github.io/Motion-2-to-3/.