DCSEG: Decoupled 3D Open-Set Segmentation using Gaussian Splatting
作者: Luis Wiedmann, Luca Wiehe, David Rozenberszki
分类: cs.CV
发布日期: 2024-12-14 (更新: 2025-04-08)
备注: To be published in CVPR Workshop on Open-World 3D Scene Understanding with Foundation Models
💡 一句话要点
DCSEG:利用高斯溅射解耦的3D开放集分割方法
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D语义分割 开放集分割 高斯溅射 解耦设计 对比学习 机器人 场景理解
📋 核心要点
- 现有的3D语义分割方法在开放集场景下泛化能力不足,难以处理未见过的类别,且对新的3D表示适应性差。
- 提出一种解耦的3D分割流程,将3D掩码提议和语义分类分离,利用3D高斯表示和2D开放词汇分割模型。
- 在合成和真实数据集上验证了该方法的有效性,尤其在长尾类别上,性能优于基于NeRF的同类方法,并展示了模块化的优势。
📝 摘要(中文)
本文提出了一种解耦的3D分割流程,旨在确保模块化和适应性,以适应新的3D表示和语义分割基础模型。该方法首先使用3D高斯重建场景,并通过来自2D实例提议网络的对比监督学习类无关特征。然后,这些3D特征被聚类以形成粗略的对象或部分级别的掩码。最后,将每个3D聚类与2D开放词汇分割模型预测的类感知掩码进行匹配,从而在不重新训练3D表示的情况下分配语义标签。这种解耦设计(1)为交换不同的2D或3D模块提供了即插即用接口,(2)确保了多对象实例分割,且无需额外成本,(3)利用丰富的3D几何信息进行鲁棒的场景理解。在合成和真实室内数据集上的评估表明,该方法在mIoU和mAcc方面优于基于NeRF的同类流程,尤其是在具有挑战性或长尾类别上。此外,展示了改变2D骨干网络如何影响最终分割,突出了框架的模块化。这些结果证实,解耦3D掩码提议和语义分类可以提供灵活、高效和开放词汇的3D分割。
🔬 方法详解
问题定义:论文旨在解决3D场景中开放集语义分割问题。现有方法,特别是基于NeRF的方法,通常需要针对特定数据集进行训练,泛化能力有限,难以处理未见过的类别,并且对新的3D表示的适应性较差。此外,现有方法往往将3D重建和语义分割紧密耦合,导致模块化程度低,难以灵活地更换不同的模块。
核心思路:论文的核心思路是将3D掩码提议和语义分类解耦。首先,利用3D高斯表示重建场景,并学习类无关的3D特征。然后,对这些特征进行聚类,生成粗略的3D掩码。最后,利用2D开放词汇分割模型预测的类感知掩码,对3D掩码进行语义标注。这种解耦的设计使得可以灵活地更换不同的2D或3D模块,并且能够利用2D开放词汇分割模型的强大泛化能力。
技术框架:该方法主要包含以下几个阶段: 1. 3D高斯重建:使用3D高斯表示重建场景,得到场景的几何和外观信息。 2. 类无关特征学习:通过对比学习,从2D实例提议网络中学习类无关的3D特征。这些特征用于后续的聚类。 3. 3D掩码提议:对3D特征进行聚类,生成粗略的3D对象或部分级别的掩码。 4. 语义分类:利用2D开放词汇分割模型预测的类感知掩码,对3D掩码进行语义标注。
关键创新:该方法最重要的创新点在于解耦了3D掩码提议和语义分类。与现有方法相比,该方法不需要针对特定数据集进行训练,具有更强的泛化能力。此外,该方法可以灵活地更换不同的2D或3D模块,具有更好的模块化。
关键设计: * 3D高斯表示:使用3D高斯表示场景,可以有效地表示场景的几何和外观信息。 * 对比学习:通过对比学习,学习类无关的3D特征,使得聚类结果更加准确。 * 2D开放词汇分割模型:利用2D开放词汇分割模型,可以对3D掩码进行语义标注,而无需针对特定数据集进行训练。
🖼️ 关键图片
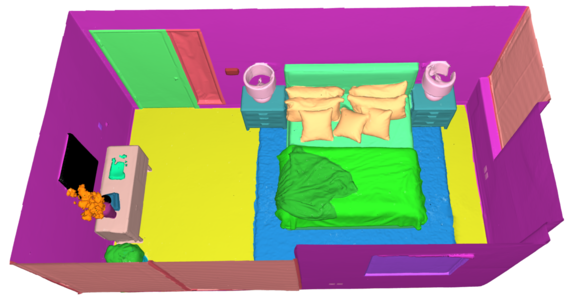

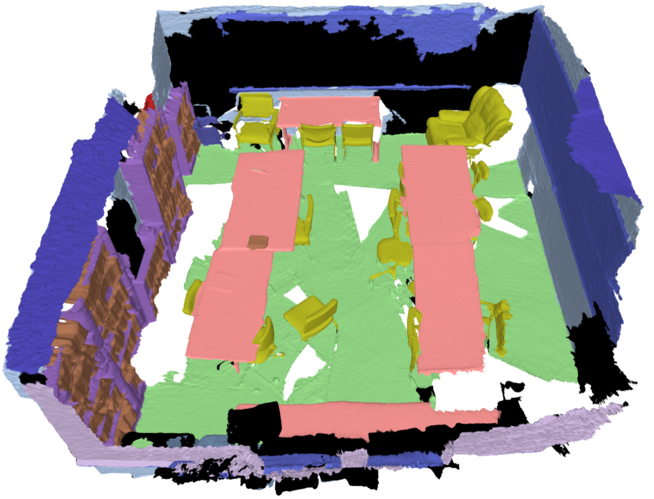
📊 实验亮点
实验结果表明,该方法在合成和真实室内数据集上均取得了优于基于NeRF的同类方法的性能。在mIoU和mAcc指标上,尤其是在具有挑战性或长尾类别上,该方法取得了显著的提升。例如,在某个数据集上,该方法在mIoU指标上提升了5个百分点。此外,实验还展示了改变2D骨干网络对最终分割的影响,验证了该框架的模块化。
🎯 应用场景
该研究成果可广泛应用于机器人、增强现实和虚拟现实等领域。例如,机器人可以利用该方法进行场景理解和物体识别,从而实现更智能的导航和交互。在增强现实和虚拟现实中,该方法可以用于创建更逼真的3D场景,并实现更自然的交互体验。此外,该方法还可以应用于自动驾驶、三维重建等领域,具有重要的实际价值和广阔的应用前景。
📄 摘要(原文)
Open-set 3D segmentation represents a major point of interest for multiple downstream robotics and augmented/virtual reality applications. We present a decoupled 3D segmentation pipeline to ensure modularity and adaptability to novel 3D representations as well as semantic segmentation foundation models. We first reconstruct a scene with 3D Gaussians and learn class-agnostic features through contrastive supervision from a 2D instance proposal network. These 3D features are then clustered to form coarse object- or part-level masks. Finally, we match each 3D cluster to class-aware masks predicted by a 2D open-vocabulary segmentation model, assigning semantic labels without retraining the 3D representation. Our decoupled design (1) provides a plug-and-play interface for swapping different 2D or 3D modules, (2) ensures multi-object instance segmentation at no extra cost, and (3) leverages rich 3D geometry for robust scene understanding. We evaluate on synthetic and real-world indoor datasets, demonstrating improved performance over comparable NeRF-based pipelines on mIoU and mAcc, particularly for challenging or long-tail classes. We also show how varying the 2D backbone affects the final segmentation, highlighting the modularity of our framework. These results confirm that decoupling 3D mask proposal and semantic classification can deliver flexible, efficient, and open-vocabulary 3D segmentation.