Attention-driven GUI Grounding: Leveraging Pretrained Multimodal Large Language Models without Fine-Tuning
作者: Hai-Ming Xu, Qi Chen, Lei Wang, Lingqiao Liu
分类: cs.CV
发布日期: 2024-12-14
备注: Accepted to AAAI 2025
💡 一句话要点
提出免微调的注意力驱动GUI定位方法,利用预训练多模态大语言模型实现精准GUI组件识别。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: GUI定位 多模态大语言模型 注意力机制 免微调学习 视觉语言理解
📋 核心要点
- 现有GUI组件定位方法依赖于使用专门训练数据微调MLLM,成本高昂且泛化性受限。
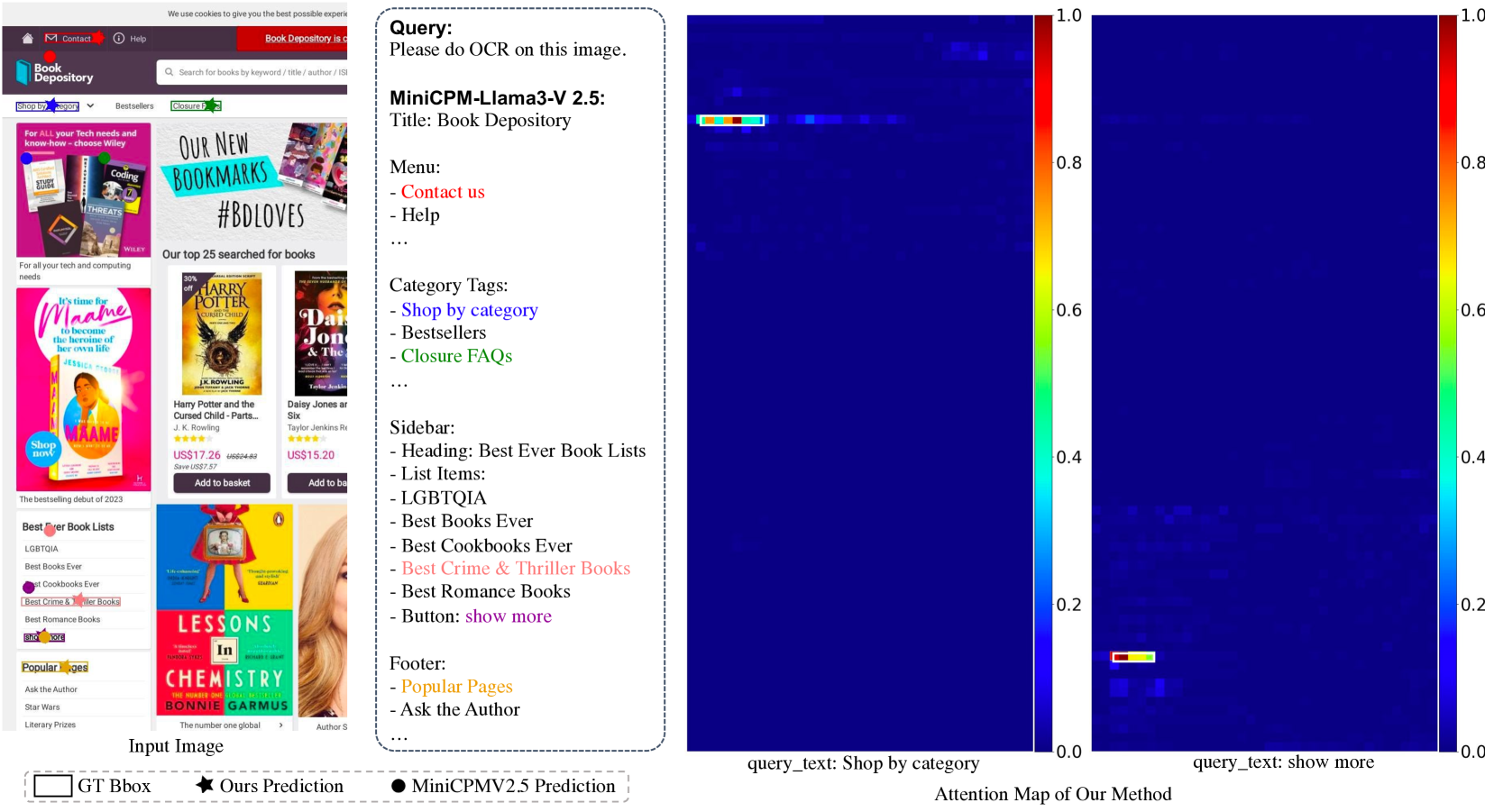
- TAG方法通过设计特定prompt,提取MLLM内部注意力图,无需微调即可实现组件定位。
- 实验表明,TAG方法在MiniCPM-Llama3-V 2.5上表现出色,媲美微调方法,文本定位效果显著。
📝 摘要(中文)
本文提出了一种免微调的注意力驱动定位(TAG)方法,旨在利用预训练多模态大语言模型(MLLM)的固有注意力模式,实现对图形用户界面(GUI)中关键组件(如文本或图标)的精确定位,而无需额外的微调。该方法通过识别和聚合精心构建的查询提示中特定token的注意力图来实现。在MiniCPM-Llama3-V 2.5这一先进的MLLM上的应用表明,该免微调方法能够达到与基于微调的方法相媲美的性能,尤其在文本定位方面表现出色。此外,该方法基于注意力图的定位技术显著优于MiniCPM-Llama3-V 2.5的直接定位预测,突显了利用预训练MLLM的注意力图的潜力,并为该领域的未来创新铺平了道路。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型(MLLM)在图形用户界面(GUI)交互中,如何准确识别和定位GUI组件(如文本、图标等)的问题。现有方法主要依赖于使用大量标注数据对MLLM进行微调,以直接预测组件的位置。这种方法的痛点在于需要大量的标注数据,微调过程耗时耗力,且模型泛化能力可能受限。
核心思路:论文的核心思路是利用预训练MLLM本身已经具备的注意力机制,通过设计特定的prompt,引导模型将注意力集中在与查询相关的GUI组件上。然后,通过提取和聚合这些注意力图,实现对GUI组件的定位,从而避免了对MLLM进行微调的需要。这种思路的优势在于可以充分利用预训练模型的知识,降低训练成本,并提高模型的泛化能力。
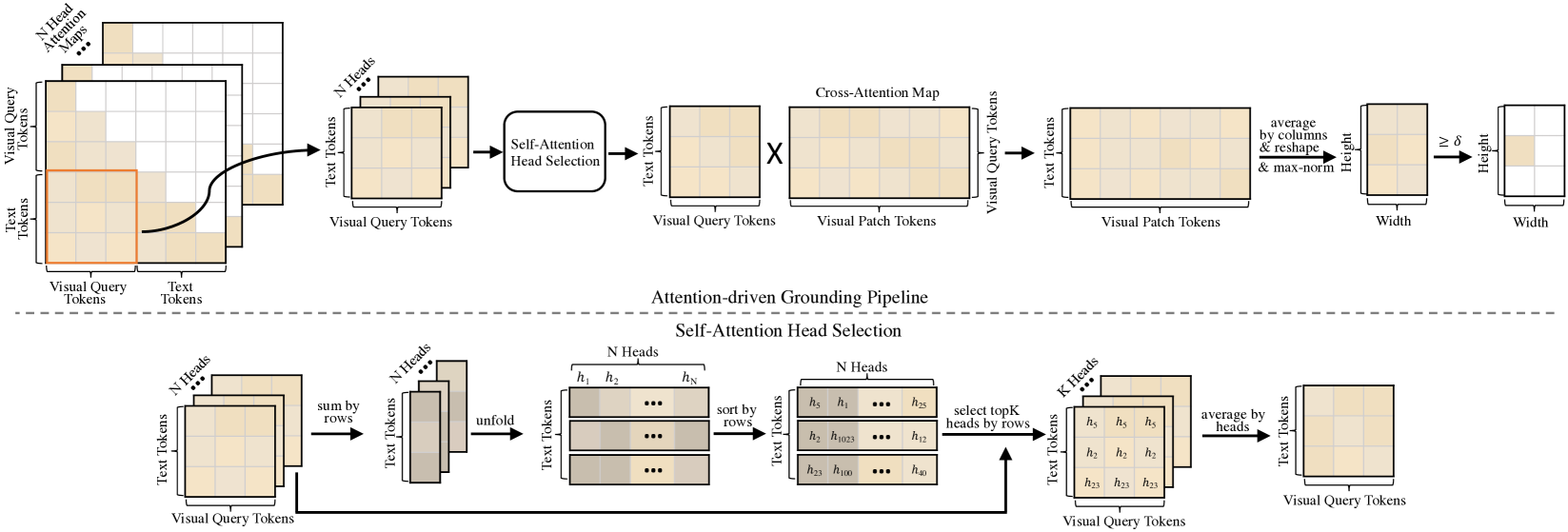
技术框架:TAG方法的技术框架主要包括以下几个步骤:1) 构建包含GUI图像和文本查询的输入;2) 将输入送入预训练的MLLM(如MiniCPM-Llama3-V 2.5);3) 从MLLM中提取与查询相关的token的注意力图;4) 对提取的注意力图进行聚合,得到最终的定位结果。整个流程无需对MLLM进行任何参数更新。
关键创新:论文最重要的技术创新点在于提出了一种免微调的GUI组件定位方法,该方法充分利用了预训练MLLM的注意力机制,避免了对大量标注数据的依赖和耗时的微调过程。与现有方法相比,TAG方法在保证定位精度的同时,显著降低了训练成本,并提高了模型的泛化能力。
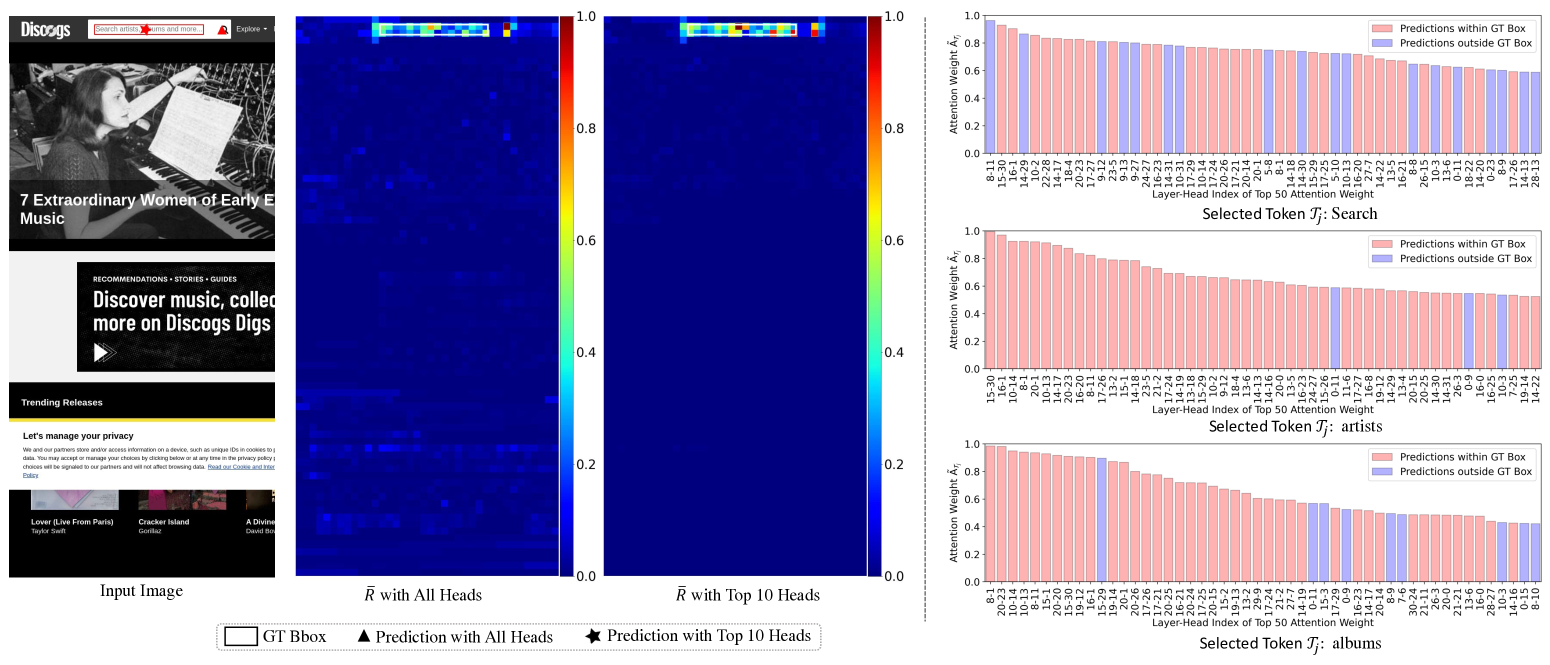
关键设计:TAG方法的关键设计包括:1) 精心设计的prompt,用于引导MLLM将注意力集中在与查询相关的GUI组件上;2) 选择合适的token提取注意力图,例如与组件类型相关的token;3) 设计有效的注意力图聚合方法,例如平均池化或加权平均等。具体参数设置和网络结构取决于所使用的预训练MLLM。
🖼️ 关键图片
📊 实验亮点
实验结果表明,TAG方法在MiniCPM-Llama3-V 2.5上取得了与微调方法相媲美的性能,尤其在文本定位方面表现出色。更重要的是,TAG方法显著优于MiniCPM-Llama3-V 2.5的直接定位预测,验证了利用预训练MLLM的注意力图进行GUI组件定位的有效性。具体性能数据未知,但论文强调了其可比性与优越性。
🎯 应用场景
该研究成果可广泛应用于智能助手、自动化测试、无障碍设计等领域。例如,智能助手可以利用该技术理解用户在GUI上的操作意图,并自动完成相关任务。自动化测试可以利用该技术自动识别GUI组件,并进行自动化测试。无障碍设计可以利用该技术帮助视障人士更好地理解和操作GUI。
📄 摘要(原文)
Recent advancements in Multimodal Large Language Models (MLLMs) have generated significant interest in their ability to autonomously interact with and interpret Graphical User Interfaces (GUIs). A major challenge in these systems is grounding-accurately identifying critical GUI components such as text or icons based on a GUI image and a corresponding text query. Traditionally, this task has relied on fine-tuning MLLMs with specialized training data to predict component locations directly. However, in this paper, we propose a novel Tuning-free Attention-driven Grounding (TAG) method that leverages the inherent attention patterns in pretrained MLLMs to accomplish this task without the need for additional fine-tuning. Our method involves identifying and aggregating attention maps from specific tokens within a carefully constructed query prompt. Applied to MiniCPM-Llama3-V 2.5, a state-of-the-art MLLM, our tuning-free approach achieves performance comparable to tuning-based methods, with notable success in text localization. Additionally, we demonstrate that our attention map-based grounding technique significantly outperforms direct localization predictions from MiniCPM-Llama3-V 2.5, highlighting the potential of using attention maps from pretrained MLLMs and paving the way for future innovations in this domain.