MambaPro: Multi-Modal Object Re-Identification with Mamba Aggregation and Synergistic Prompt
作者: Yuhao Wang, Xuehu Liu, Tianyu Yan, Yang Liu, Aihua Zheng, Pingping Zhang, Huchuan Lu
分类: cs.CV, cs.MM
发布日期: 2024-12-14
备注: This work is accepted by AAAI2025. More modifications may be performed
🔗 代码/项目: GITHUB
💡 一句话要点
MambaPro:利用Mamba聚合和协同提示进行多模态物体重识别
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多模态学习 物体重识别 Mamba 序列建模 CLIP 协同提示 特征聚合
📋 核心要点
- 现有方法在多模态物体重识别中,难以有效处理来自不同模态的长序列,限制了性能。
- MambaPro通过引入Mamba聚合和协同提示,有效建模多模态特征间的交互,提升特征表达能力。
- 在多个基准数据集上,MambaPro取得了显著的性能提升,验证了其在多模态物体重识别任务中的有效性。
📝 摘要(中文)
本文提出了一种名为MambaPro的新框架,用于多模态物体重识别。该框架旨在解决现有方法在处理来自不同模态的长序列时存在的局限性。具体来说,首先采用并行前馈适配器(PFA)使CLIP适应多模态物体重识别任务。然后,提出协同残差提示(SRP)来引导多模态特征的联合学习。最后,利用Mamba在处理长序列方面的优越可扩展性,引入Mamba聚合(MA)来有效地建模不同模态之间的交互。因此,MambaPro能够以较低的复杂度提取更鲁棒的特征。在RGBNT201、RGBNT100和MSVR310三个多模态物体重识别基准数据集上的大量实验验证了所提出方法的有效性。
🔬 方法详解
问题定义:多模态物体重识别旨在利用来自不同模态(如RGB和红外)的图像信息来检索特定物体。现有方法,特别是基于Transformer的方法,在处理长序列时计算复杂度高,难以有效建模不同模态间的长程依赖关系。此外,如何有效利用预训练模型(如CLIP)并将其适配到多模态重识别任务中也是一个挑战。
核心思路:MambaPro的核心思路是利用Mamba结构的线性复杂度来高效处理长序列,从而更好地建模不同模态间的交互。同时,通过协同提示引导多模态特征的联合学习,增强特征的判别性。此外,采用并行前馈适配器将CLIP的知识迁移到多模态重识别任务中。
技术框架:MambaPro的整体框架包含三个主要模块:1) 并行前馈适配器(PFA):用于将CLIP模型适配到多模态重识别任务。2) 协同残差提示(SRP):用于引导多模态特征的联合学习。3) Mamba聚合(MA):用于高效建模不同模态之间的交互。首先,使用PFA提取多模态特征。然后,通过SRP引导多模态特征的融合。最后,利用MA模块聚合不同模态的信息,得到最终的物体表示。
关键创新:MambaPro的关键创新在于引入了Mamba聚合(MA)来建模多模态特征之间的交互。与传统的Transformer结构相比,Mamba具有线性复杂度,可以高效处理长序列。此外,协同残差提示(SRP)通过引入残差连接,可以更好地引导多模态特征的联合学习,避免信息损失。
关键设计:并行前馈适配器(PFA)采用并行的前馈网络结构,可以有效地将CLIP的知识迁移到多模态重识别任务中。协同残差提示(SRP)通过引入残差连接,可以更好地引导多模态特征的联合学习。Mamba聚合(MA)采用Mamba结构,可以高效处理长序列,并建模不同模态之间的长程依赖关系。损失函数方面,可能采用了交叉熵损失或三元组损失等常用的重识别损失函数,具体细节未知。
🖼️ 关键图片
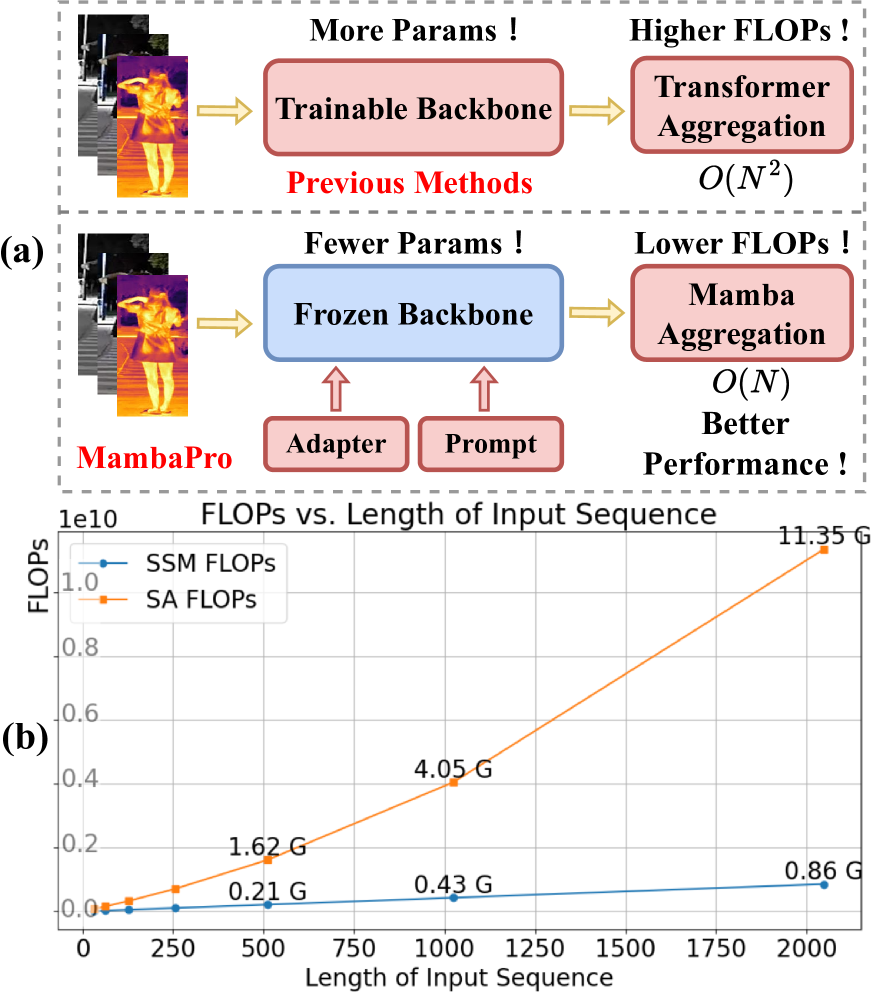


📊 实验亮点
MambaPro在RGBNT201、RGBNT100和MSVR310三个多模态物体重识别基准数据集上取得了显著的性能提升。具体的数据提升幅度未知,但摘要中明确指出实验验证了所提出方法的有效性,表明MambaPro优于现有的多模态物体重识别方法。
🎯 应用场景
MambaPro在智能安防、机器人导航、自动驾驶等领域具有广泛的应用前景。例如,在智能安防中,可以利用多模态信息(如可见光和红外图像)进行更准确的物体识别和跟踪。在机器人导航中,可以利用多模态传感器数据进行环境感知和定位。该研究的实际价值在于提高了多模态物体重识别的准确性和效率,为相关应用提供了更可靠的技术支持。
📄 摘要(原文)
Multi-modal object Re-IDentification (ReID) aims to retrieve specific objects by utilizing complementary image information from different modalities. Recently, large-scale pre-trained models like CLIP have demonstrated impressive performance in traditional single-modal object ReID tasks. However, they remain unexplored for multi-modal object ReID. Furthermore, current multi-modal aggregation methods have obvious limitations in dealing with long sequences from different modalities. To address above issues, we introduce a novel framework called MambaPro for multi-modal object ReID. To be specific, we first employ a Parallel Feed-Forward Adapter (PFA) for adapting CLIP to multi-modal object ReID. Then, we propose the Synergistic Residual Prompt (SRP) to guide the joint learning of multi-modal features. Finally, leveraging Mamba's superior scalability for long sequences, we introduce Mamba Aggregation (MA) to efficiently model interactions between different modalities. As a result, MambaPro could extract more robust features with lower complexity. Extensive experiments on three multi-modal object ReID benchmarks (i.e., RGBNT201, RGBNT100 and MSVR310) validate the effectiveness of our proposed methods. The source code is available at https://github.com/924973292/MambaPro.