The Language of Motion: Unifying Verbal and Non-verbal Language of 3D Human Motion
作者: Changan Chen, Juze Zhang, Shrinidhi K. Lakshmikanth, Yusu Fang, Ruizhi Shao, Gordon Wetzstein, Li Fei-Fei, Ehsan Adeli
分类: cs.CV
发布日期: 2024-12-13
备注: Project page: languageofmotion.github.io
💡 一句话要点
提出统一 verbal 和 non-verbal 语言的 3D 人体运动生成框架
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人体运动生成 多模态融合 语言模型 co-speech手势 Transformer 预训练 运动理解
📋 核心要点
- 现有运动生成模型通常局限于特定的输入模态(语音、文本或运动数据),无法充分利用数据的多样性。
- 论文提出一种多模态语言模型,统一处理 verbal 和 non-verbal 信息,实现更灵活的人体运动理解和生成。
- 通过新颖的预训练策略,模型在 co-speech 手势生成上达到 SOTA,并减少了训练数据需求,同时支持可编辑手势生成等新任务。
📝 摘要(中文)
本文提出了一种新颖的框架,该框架使用多模态语言模型统一了 verbal 和 non-verbal 语言,用于人体运动理解和生成。该模型能够灵活地接受文本、语音和运动数据或它们的任意组合作为输入。结合我们新颖的预训练策略,我们的模型不仅在 co-speech 手势生成方面取得了最先进的性能,而且训练所需的数据也大大减少。我们的模型还解锁了一系列新颖的任务,例如可编辑的手势生成和从运动中预测情绪。我们认为统一 verbal 和 non-verbal 人体运动语言对于实际应用至关重要,而语言模型为实现这一目标提供了一种强大的方法。
🔬 方法详解
问题定义:现有的人体运动生成模型通常只能处理单一模态的输入,例如文本、语音或者运动数据本身。这限制了模型对人类交流中verbal和non-verbal信息融合的理解能力,也使得模型无法充分利用多种模态的数据进行训练。因此,如何设计一个能够同时处理多种模态输入,并生成自然、连贯的人体运动的模型是一个重要的挑战。
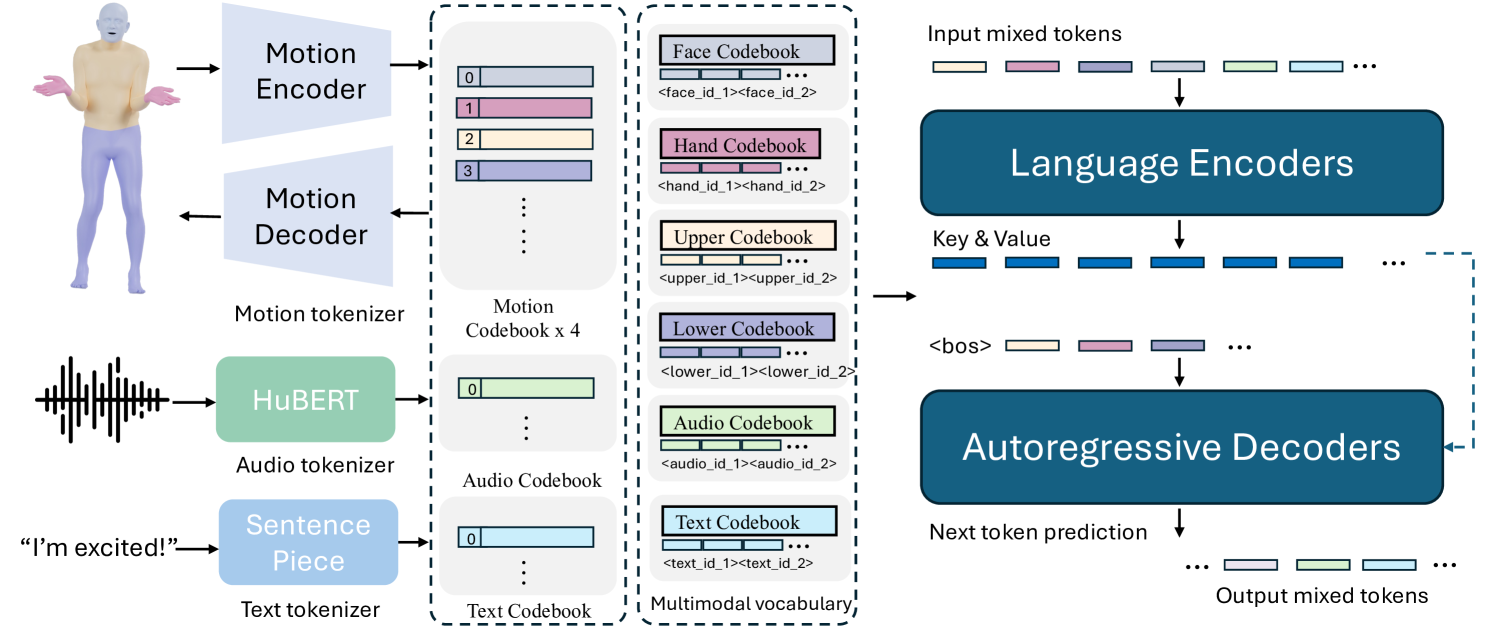
核心思路:本文的核心思路是利用多模态语言模型来统一verbal和non-verbal信息。通过将文本、语音和运动数据都编码到同一个语义空间中,模型可以学习到它们之间的关联关系,从而实现更灵活的运动生成。这种方法借鉴了自然语言处理领域中语言模型的成功经验,将人体运动视为一种“运动语言”,并利用语言模型来建模这种语言。
技术框架:该模型采用一个多模态Transformer架构,包含以下几个主要模块:1) 输入编码器:分别将文本、语音和运动数据编码成向量表示。2) 多模态融合模块:将不同模态的向量表示融合在一起,得到一个统一的语义表示。3) 运动解码器:根据融合后的语义表示生成人体运动序列。整个框架采用encoder-decoder结构,可以灵活地处理不同模态的输入,并生成相应的运动序列。
关键创新:该论文最重要的技术创新点在于提出了一个统一的verbal和non-verbal语言的框架。与以往的模型相比,该模型可以同时处理多种模态的输入,并学习到它们之间的关联关系。此外,该论文还提出了一种新颖的预训练策略,可以有效地提高模型的性能,并减少训练数据需求。
关键设计:在输入编码器方面,论文使用了预训练的文本编码器(如BERT)来提取文本特征,使用了语音识别模型来提取语音特征,并使用了变分自编码器(VAE)来编码运动数据。在多模态融合模块方面,论文使用了cross-attention机制来融合不同模态的向量表示。在运动解码器方面,论文使用了Transformer decoder来生成人体运动序列。损失函数包括运动重建损失、文本对齐损失和语音对齐损失等。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该模型在 co-speech 手势生成任务上取得了 state-of-the-art 的性能。此外,该模型还解锁了一系列新颖的任务,例如可编辑的手势生成和从运动中预测情绪。更重要的是,该模型在取得更好性能的同时,训练所需的数据量也大大减少,这使得该模型更易于在实际应用中部署。
🎯 应用场景
该研究成果可广泛应用于游戏、电影、虚拟现实等领域,创造能够自然交流的虚拟角色。例如,可以根据用户的语音和文本指令生成相应的肢体动作,或者根据角色的情绪状态生成相应的面部表情和身体姿态。此外,该技术还可以用于运动康复、人机交互等领域,具有重要的实际应用价值和广阔的发展前景。
📄 摘要(原文)
Human communication is inherently multimodal, involving a combination of verbal and non-verbal cues such as speech, facial expressions, and body gestures. Modeling these behaviors is essential for understanding human interaction and for creating virtual characters that can communicate naturally in applications like games, films, and virtual reality. However, existing motion generation models are typically limited to specific input modalities -- either speech, text, or motion data -- and cannot fully leverage the diversity of available data. In this paper, we propose a novel framework that unifies verbal and non-verbal language using multimodal language models for human motion understanding and generation. This model is flexible in taking text, speech, and motion or any combination of them as input. Coupled with our novel pre-training strategy, our model not only achieves state-of-the-art performance on co-speech gesture generation but also requires much less data for training. Our model also unlocks an array of novel tasks such as editable gesture generation and emotion prediction from motion. We believe unifying the verbal and non-verbal language of human motion is essential for real-world applications, and language models offer a powerful approach to achieving this goal. Project page: languageofmotion.github.io.