Apollo: An Exploration of Video Understanding in Large Multimodal Models
作者: Orr Zohar, Xiaohan Wang, Yann Dubois, Nikhil Mehta, Tong Xiao, Philippe Hansen-Estruch, Licheng Yu, Xiaofang Wang, Felix Juefei-Xu, Ning Zhang, Serena Yeung-Levy, Xide Xia
分类: cs.CV, cs.AI
发布日期: 2024-12-13
备注: https://apollo-lmms.github.io
💡 一句话要点
Apollo:探索大规模多模态模型中的视频理解能力,并提出高效训练策略。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长视频理解 多模态模型 视频问答 缩放一致性 高效训练 视觉编码器 Transformer架构
📋 核心要点
- 现有视频-LMM研究缺乏对视频理解机制的深入理解,设计决策缺乏依据,且训练成本高昂。
- 该研究通过探索缩放一致性,将小模型上的有效设计迁移到大模型,降低了计算成本。
- 提出的Apollo模型家族在多个视频理解基准测试中取得了显著的性能提升,尤其是在长视频处理方面。
📝 摘要(中文)
尽管视频感知能力已迅速集成到大型多模态模型(LMM)中,但驱动其视频理解的底层机制仍然知之甚少。因此,该领域的许多设计决策缺乏充分的理由或分析。训练和评估此类模型的高计算成本,以及有限的公开研究,阻碍了视频LMM的发展。为了解决这个问题,我们提出了一项全面的研究,旨在揭示有效驱动LMM中视频理解的因素。我们首先 критически 检查与视频LMM研究相关的高计算需求的主要贡献者,并发现缩放一致性,即在较小模型和数据集(直至临界大小)上做出的设计和训练决策有效地转移到较大的模型。利用这些见解,我们探索了视频LMM的许多视频特定方面,包括视频采样、架构、数据组成、训练计划等。例如,我们证明了训练期间的fps采样远优于均匀帧采样,以及哪些视觉编码器最适合视频表示。在这些发现的指导下,我们推出了Apollo,这是一个最先进的LMM系列,可在不同模型尺寸上实现卓越的性能。我们的模型可以有效地感知长达一小时的视频,其中Apollo-3B在LongVideoBench上的表现优于大多数现有的7B模型,达到了令人印象深刻的55.1。Apollo-7B与7B LMM相比是最先进的,在MLVU上达到了70.9,在Video-MME上达到了63.3。
🔬 方法详解
问题定义:现有的大型多模态模型在视频理解方面面临计算成本高、缺乏对底层机制理解的问题。现有的视频-LMM研究在设计和训练决策上缺乏充分的依据,并且由于计算资源的限制,难以进行大规模的实验和分析。这阻碍了视频-LMM的进一步发展。
核心思路:论文的核心思路是探索视频-LMM的缩放一致性,即在小规模模型和数据集上有效的训练策略和设计选择,可以有效地迁移到更大规模的模型上。通过这种方式,可以在较低的计算成本下,探索视频-LMM的关键设计因素,并指导更大模型的训练。
技术框架:Apollo模型家族的整体框架基于Transformer架构,包括视觉编码器、文本编码器和多模态融合模块。视觉编码器负责提取视频帧的特征表示,文本编码器负责处理文本输入,多模态融合模块将视觉和文本特征进行融合,用于下游任务的预测。训练过程包括预训练和微调两个阶段。
关键创新:论文的关键创新在于发现了视频-LMM的缩放一致性,并利用这一特性进行高效的模型设计和训练。此外,论文还探索了多种视频特定的设计因素,如视频采样策略(fps采样优于均匀采样)和视觉编码器的选择,并为视频-LMM的设计提供了有价值的指导。
关键设计:在视频采样方面,论文发现使用fps采样(即按照固定的帧率采样)比均匀采样更有效。在视觉编码器方面,论文评估了多种视觉编码器的性能,并选择了最适合视频表示的编码器。此外,论文还对训练计划、数据组成等方面进行了优化,以提高模型的性能。
🖼️ 关键图片

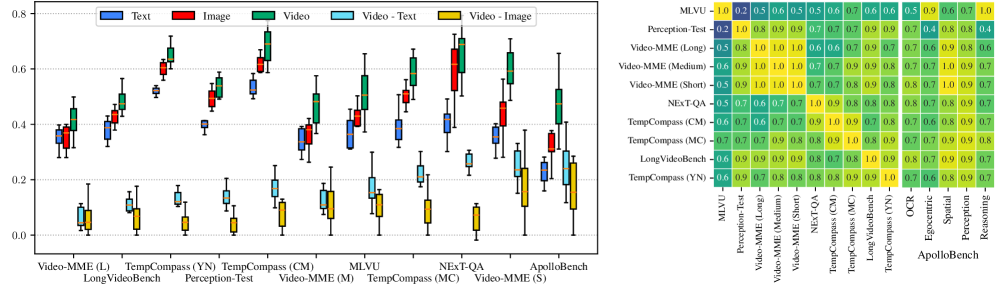
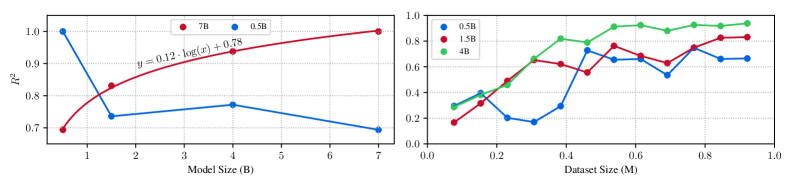
📊 实验亮点
Apollo模型家族在多个视频理解基准测试中取得了显著的性能提升。Apollo-3B在LongVideoBench上达到了55.1,优于大多数现有的7B模型。Apollo-7B在MLVU上达到了70.9,在Video-MME上达到了63.3,均优于同等规模的其他模型。这些结果表明,Apollo模型在视频理解方面具有强大的能力。
🎯 应用场景
该研究成果可应用于视频内容理解、视频问答、视频摘要、视频编辑等领域。Apollo模型能够高效处理长视频,具有在智能监控、在线教育、娱乐媒体等领域的广泛应用前景。未来的研究可以进一步探索更高效的视频表示方法和多模态融合策略,以提升视频-LMM的性能和泛化能力。
📄 摘要(原文)
Despite the rapid integration of video perception capabilities into Large Multimodal Models (LMMs), the underlying mechanisms driving their video understanding remain poorly understood. Consequently, many design decisions in this domain are made without proper justification or analysis. The high computational cost of training and evaluating such models, coupled with limited open research, hinders the development of video-LMMs. To address this, we present a comprehensive study that helps uncover what effectively drives video understanding in LMMs. We begin by critically examining the primary contributors to the high computational requirements associated with video-LMM research and discover Scaling Consistency, wherein design and training decisions made on smaller models and datasets (up to a critical size) effectively transfer to larger models. Leveraging these insights, we explored many video-specific aspects of video-LMMs, including video sampling, architectures, data composition, training schedules, and more. For example, we demonstrated that fps sampling during training is vastly preferable to uniform frame sampling and which vision encoders are the best for video representation. Guided by these findings, we introduce Apollo, a state-of-the-art family of LMMs that achieve superior performance across different model sizes. Our models can perceive hour-long videos efficiently, with Apollo-3B outperforming most existing $7$B models with an impressive 55.1 on LongVideoBench. Apollo-7B is state-of-the-art compared to 7B LMMs with a 70.9 on MLVU, and 63.3 on Video-MME.