Robust image classification with multi-modal large language models
作者: Francesco Villani, Igor Maljkovic, Dario Lazzaro, Angelo Sotgiu, Antonio Emanuele Cinà, Fabio Roli
分类: cs.CV, cs.CR, cs.LG
发布日期: 2024-12-13 (更新: 2025-04-18)
备注: Paper accepted at Pattern Recognition Letters journal Keywords: adversarial examples, rejection defense, multimodal-informed systems, machine learning security
期刊: Pattern Recognition Letters 2025
💡 一句话要点
提出MultiShield,利用多模态大语言模型提升图像分类模型对抗攻击的鲁棒性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对抗攻击 鲁棒性 多模态学习 大语言模型 图像分类
📋 核心要点
- 深度神经网络易受对抗样本攻击,现有防御方法多侧重于单模态数据,忽略了视觉和文本描述间的关联。
- MultiShield利用多模态大语言模型,通过检测视觉和文本表示的不一致性来识别对抗样本,并拒绝不确定的分类。
- 实验表明,MultiShield能有效集成到现有防御体系中,在CIFAR-10和ImageNet数据集上均优于原始防御方法。
📝 摘要(中文)
深度神经网络容易受到对抗样本的攻击,即经过精心设计的输入样本会导致模型以高置信度做出错误的预测。为了缓解这些漏洞,已经提出了对抗训练和基于检测的防御方法来提前加强模型。然而,大多数方法侧重于单一数据模态,忽略了视觉模式和输入文本描述之间的关系。本文提出了一种新的防御方法MultiShield,旨在结合和补充这些防御方法,利用多模态信息进一步提高其鲁棒性。MultiShield利用多模态大型语言模型来检测对抗样本,并在输入文本和视觉表示不一致时避免不确定的分类。在CIFAR-10和ImageNet数据集上使用鲁棒和非鲁棒图像分类模型进行的大量评估表明,MultiShield可以很容易地集成以检测和拒绝对抗样本,优于原始防御方法。
🔬 方法详解
问题定义:论文旨在解决深度神经网络在面对对抗样本时鲁棒性不足的问题。现有的防御方法,如对抗训练和基于检测的防御,大多只关注图像本身的特征,忽略了图像的文本描述信息,这使得模型容易受到利用视觉和文本不一致性的对抗样本的攻击。
核心思路:论文的核心思路是利用多模态大语言模型(MLLM)来判断图像的视觉内容和文本描述是否一致。如果MLLM认为两者不一致,则认为该样本可能是对抗样本,并拒绝分类,从而提高模型的鲁棒性。这种方法利用了MLLM强大的语义理解能力,可以有效地检测出利用视觉和文本不一致性设计的对抗样本。
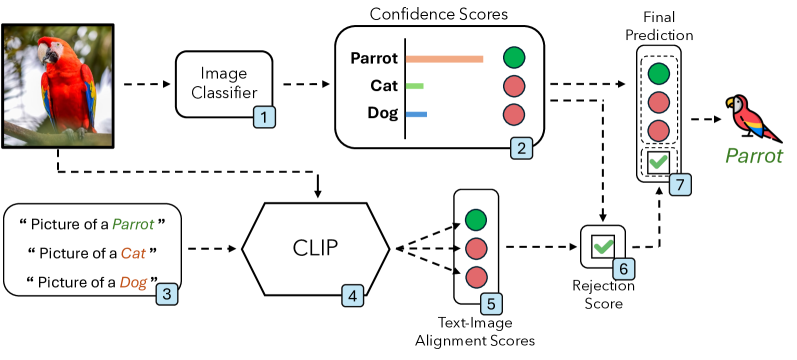
技术框架:MultiShield的整体框架包括以下几个主要步骤:1) 输入图像和对应的文本描述;2) 使用图像分类模型进行初步分类;3) 将图像和文本描述输入到多模态大语言模型中;4) MLLM判断图像和文本描述是否一致,输出一致性得分;5) 如果一致性得分低于阈值,则拒绝分类,否则接受图像分类模型的分类结果。
关键创新:MultiShield的关键创新在于将多模态大语言模型引入到对抗防御中,利用MLLM的语义理解能力来检测对抗样本。与传统的单模态防御方法相比,MultiShield可以有效地检测出利用视觉和文本不一致性设计的对抗样本,从而提高模型的鲁棒性。
关键设计:MultiShield的关键设计包括:1) 选择合适的多模态大语言模型,例如CLIP或BLIP;2) 设计合适的一致性判断方法,例如计算图像和文本嵌入向量的相似度;3) 设置合适的阈值来判断图像和文本描述是否一致。论文中具体采用的MLLM类型、一致性判断方法和阈值设置未知。
🖼️ 关键图片
📊 实验亮点
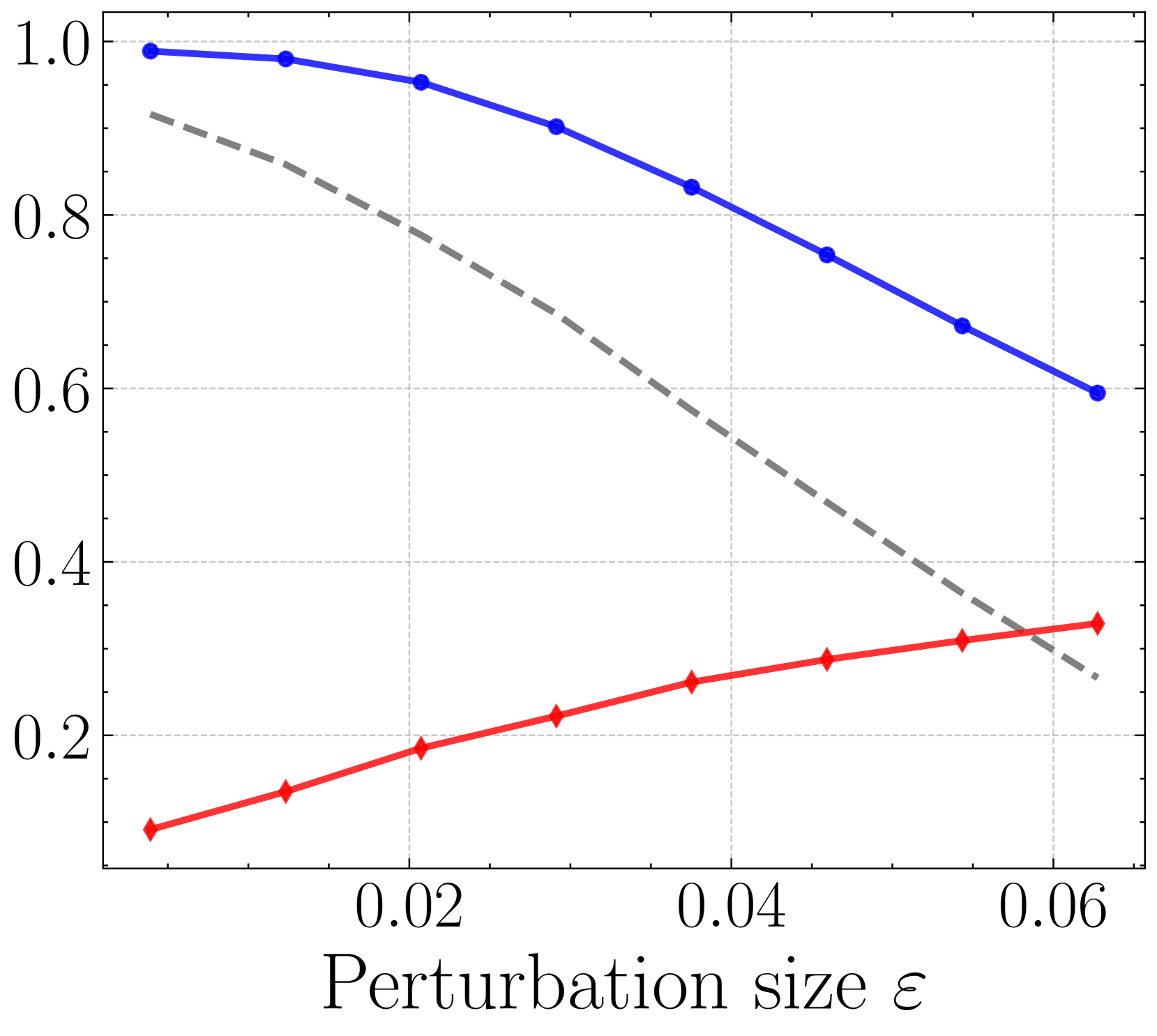
实验结果表明,MultiShield能够有效提高图像分类模型对抗攻击的鲁棒性。在CIFAR-10和ImageNet数据集上,MultiShield能够检测并拒绝大量的对抗样本,从而显著提高模型的分类准确率。与原始的防御方法相比,MultiShield在对抗攻击下的性能有明显提升,证明了其有效性。
🎯 应用场景
MultiShield可应用于各种图像分类任务中,尤其是在安全性要求较高的场景,如自动驾驶、医疗诊断等。通过提高模型对抗攻击的鲁棒性,MultiShield可以减少因对抗样本导致的误判,从而提高系统的可靠性和安全性。未来,该方法可以进一步扩展到其他模态的数据,如视频、音频等,以构建更全面的防御体系。
📄 摘要(原文)
Deep Neural Networks are vulnerable to adversarial examples, i.e., carefully crafted input samples that can cause models to make incorrect predictions with high confidence. To mitigate these vulnerabilities, adversarial training and detection-based defenses have been proposed to strengthen models in advance. However, most of these approaches focus on a single data modality, overlooking the relationships between visual patterns and textual descriptions of the input. In this paper, we propose a novel defense, MultiShield, designed to combine and complement these defenses with multi-modal information to further enhance their robustness. MultiShield leverages multi-modal large language models to detect adversarial examples and abstain from uncertain classifications when there is no alignment between textual and visual representations of the input. Extensive evaluations on CIFAR-10 and ImageNet datasets, using robust and non-robust image classification models, demonstrate that MultiShield can be easily integrated to detect and reject adversarial examples, outperforming the original defenses.