Iris: Breaking GUI Complexity with Adaptive Focus and Self-Refining
作者: Zhiqi Ge, Juncheng Li, Xinglei Pang, Minghe Gao, Kaihang Pan, Wang Lin, Hao Fei, Wenqiao Zhang, Siliang Tang, Yueting Zhuang
分类: cs.CV, cs.AI
发布日期: 2024-12-13 (更新: 2025-02-03)
💡 一句话要点
Iris:通过自适应聚焦和自精炼打破GUI复杂性的视觉Agent
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉Agent GUI自动化 多模态学习 信息敏感裁剪 自精炼学习
📋 核心要点
- 现有视觉Agent在处理高分辨率、视觉复杂的GUI时,面临视觉感知的挑战,计算效率和准确性有待提高。
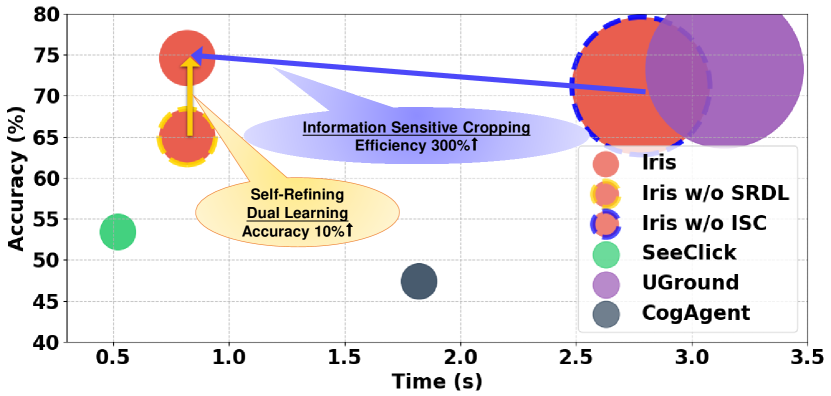
- Iris通过信息敏感裁剪(ISC)动态聚焦视觉密集区域,并利用自精炼双重学习(SRDL)提升指代和定位能力。
- 实验表明,Iris在多个基准测试中达到SOTA性能,仅使用少量数据就超越了大量数据训练的模型,并在下游任务中取得显著收益。
📝 摘要(中文)
数字代理越来越多地被用于自动化交互式数字环境(如网页、软件应用和操作系统)中的任务。基于大型语言模型(LLM)的文本代理由于平台特定API的频繁更新而需要经常更新,而利用多模态大型语言模型(MLLM)的视觉代理通过直接与图形用户界面(GUI)交互,提供了更强的适应性。然而,这些代理在视觉感知方面面临着重大挑战,尤其是在处理高分辨率、视觉复杂的数字环境时。本文介绍了一种基础视觉代理Iris,它通过两个关键创新解决了这些挑战:信息敏感裁剪(ISC)和自精炼双重学习(SRDL)。ISC动态地识别和优先处理视觉密集区域,使用边缘检测算法,通过为信息密度较高的区域分配更多计算资源来实现高效处理。SRDL通过利用双重学习循环来增强代理处理复杂任务的能力,其中指代(描述UI元素)的改进加强了定位(定位元素),反之亦然,所有这些都不需要额外的注释数据。经验评估表明,Iris仅使用850K GUI注释就在多个基准测试中实现了最先进的性能,优于使用10倍以上训练数据的方法。这些改进进一步转化为Web和OS代理下游任务的显著收益。
🔬 方法详解
问题定义:现有基于MLLM的视觉Agent在处理复杂GUI时,面临计算资源分配不均和指代/定位能力不足的问题。高分辨率GUI包含大量冗余信息,均匀处理导致效率低下。同时,指代(描述UI元素)和定位(找到UI元素)是相互关联的任务,但现有方法通常独立处理,未能充分利用二者之间的互补性。
核心思路:Iris的核心思路是模仿人类视觉注意力机制,优先处理信息密度高的区域,并利用指代和定位任务的内在联系进行互相促进的学习。通过信息敏感裁剪,减少冗余信息的干扰,提高计算效率。通过自精炼双重学习,实现指代和定位能力的同步提升。
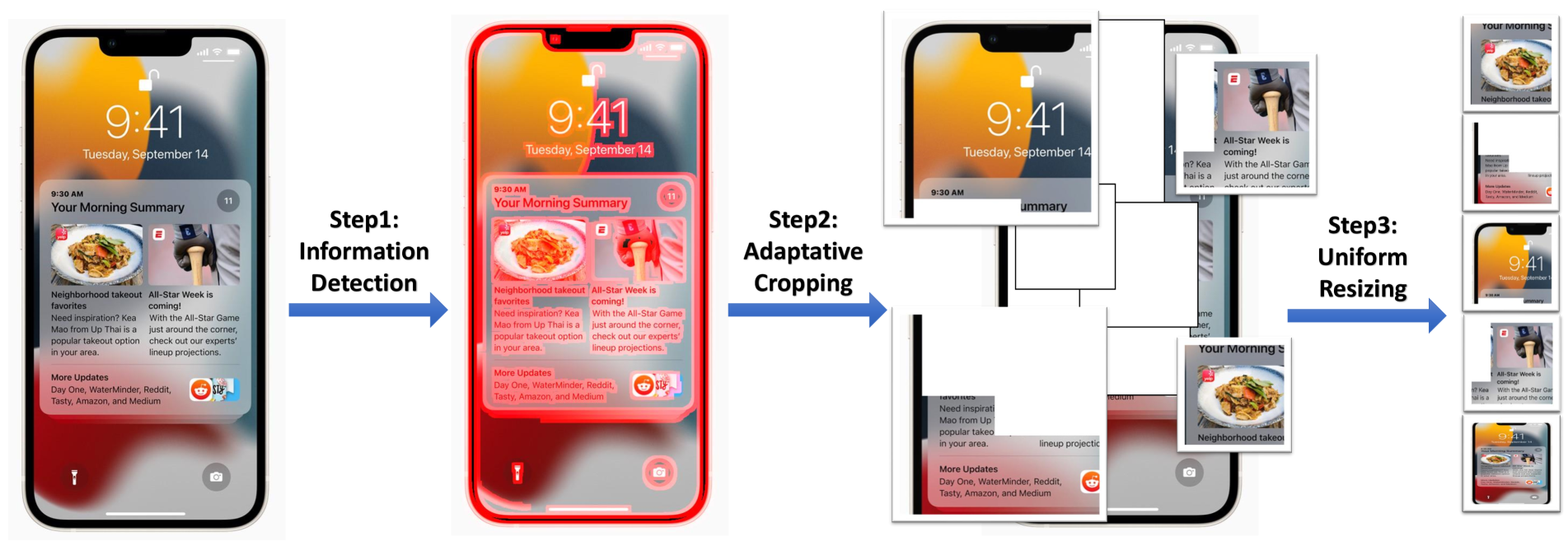
技术框架:Iris的整体框架包含两个主要模块:信息敏感裁剪(ISC)和自精炼双重学习(SRDL)。首先,ISC模块使用边缘检测算法识别GUI中的视觉密集区域,并根据信息密度动态调整裁剪区域的大小和位置。然后,裁剪后的图像和任务指令被输入到MLLM中。SRDL模块包含两个子网络:指代网络和定位网络。指代网络负责生成UI元素的描述,定位网络负责在GUI中定位UI元素。两个网络通过双重学习循环进行训练,指代网络的输出作为定位网络的输入,反之亦然。
关键创新:Iris的关键创新在于信息敏感裁剪(ISC)和自精炼双重学习(SRDL)。ISC能够动态地关注GUI中最重要的区域,从而提高计算效率和准确性。SRDL利用指代和定位任务的互补性,通过双重学习循环实现性能提升,无需额外标注数据。
关键设计:ISC使用Canny边缘检测算法来计算图像的边缘密度,并根据边缘密度自适应地调整裁剪区域的大小和位置。SRDL使用Transformer架构作为指代和定位网络的基础模型。损失函数包括指代损失和定位损失,指代损失衡量生成描述的准确性,定位损失衡量定位的准确性。双重学习循环通过最小化重构误差来促进指代和定位任务的互相学习。
🖼️ 关键图片
📊 实验亮点
Iris在多个GUI基准测试中取得了显著的性能提升,例如在WebShop数据集上,Iris的准确率超过了现有SOTA方法,并且仅使用了850K的GUI标注数据,而其他方法使用了10倍以上的数据。在下游Web和OS代理任务中,Iris也表现出显著的性能提升。
🎯 应用场景
Iris具有广泛的应用前景,可用于自动化网页操作、软件测试、操作系统控制等领域。它可以帮助用户更高效地完成重复性任务,提高工作效率。此外,Iris还可以应用于辅助残疾人使用计算机,例如通过语音指令控制GUI。
📄 摘要(原文)
Digital agents are increasingly employed to automate tasks in interactive digital environments such as web pages, software applications, and operating systems. While text-based agents built on Large Language Models (LLMs) often require frequent updates due to platform-specific APIs, visual agents leveraging Multimodal Large Language Models (MLLMs) offer enhanced adaptability by interacting directly with Graphical User Interfaces (GUIs). However, these agents face significant challenges in visual perception, particularly when handling high-resolution, visually complex digital environments. This paper introduces Iris, a foundational visual agent that addresses these challenges through two key innovations: Information-Sensitive Cropping (ISC) and Self-Refining Dual Learning (SRDL). ISC dynamically identifies and prioritizes visually dense regions using a edge detection algorithm, enabling efficient processing by allocating more computational resources to areas with higher information density. SRDL enhances the agent's ability to handle complex tasks by leveraging a dual-learning loop, where improvements in referring (describing UI elements) reinforce grounding (locating elements) and vice versa, all without requiring additional annotated data. Empirical evaluations demonstrate that Iris achieves state-of-the-art performance across multiple benchmarks with only 850K GUI annotations, outperforming methods using 10x more training data. These improvements further translate to significant gains in both web and OS agent downstream tasks.