Coherent 3D Scene Diffusion From a Single RGB Image
作者: Manuel Dahnert, Angela Dai, Norman Müller, Matthias Nießner
分类: cs.CV
发布日期: 2024-12-13
备注: Project Page: https://www.manuel-dahnert.com/research/scene-diffusion - Accepted at NeurIPS 2024
💡 一句话要点
提出一种基于扩散模型的单RGB图像三维场景连贯重建方法
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 三维场景重建 扩散模型 单视图重建 场景理解 深度学习
📋 核心要点
- 单RGB图像三维场景重建任务具有高度不确定性,现有方法难以保证场景中物体姿态和几何形状的一致性。
- 论文提出一种基于扩散模型的框架,通过学习场景先验和对象间关系,实现连贯的三维场景重建。
- 实验结果表明,该方法在SUN RGB-D和Pix3D数据集上显著优于现有技术,AP3D和F-Score分别提升12.04%和13.43%。
📝 摘要(中文)
本文提出了一种新颖的基于扩散模型的方法,用于从单张RGB图像中进行连贯的3D场景重建。我们的方法利用图像条件的3D场景扩散模型,同时对场景中所有物体的3D姿态和几何形状进行去噪。考虑到任务的不适定性以及为了获得一致的场景重建结果,我们通过同时以所有场景对象为条件来学习生成场景先验,以捕获场景上下文,并允许模型在整个扩散过程中学习对象间的关系。我们进一步提出了一种有效的表面对齐损失,即使在缺乏完整ground-truth标注的情况下也能促进训练,这在公开数据集中很常见。该损失利用了一种富有表现力的形状表示,从而能够直接从中间形状预测中进行点采样。通过将单张RGB图像3D场景重建的任务构建为条件扩散过程,我们的方法超越了当前最先进的方法,在SUN RGB-D上实现了12.04%的AP3D改进,在Pix3D上实现了13.43%的F-Score提升。
🔬 方法详解
问题定义:单RGB图像三维场景重建旨在从单个视角推断出场景中所有物体的三维姿态和几何形状。现有方法通常难以保证场景中物体之间的一致性关系,例如物体间的相对位置和尺度,并且对噪声和遮挡较为敏感。此外,缺乏完整的ground-truth标注也限制了模型的训练效果。
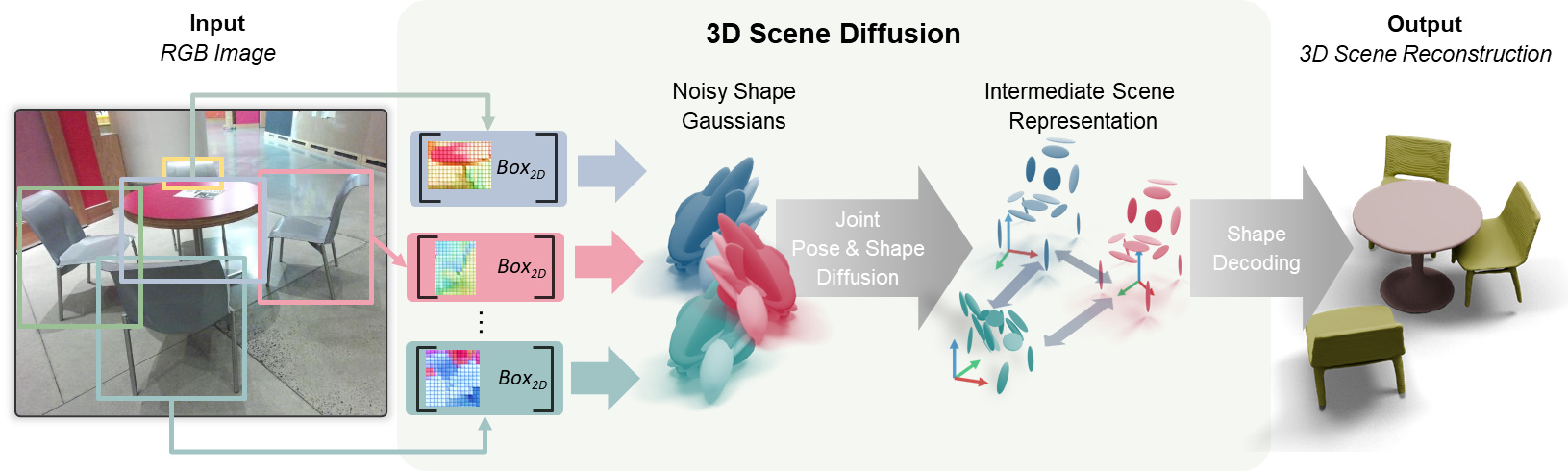
核心思路:论文的核心思路是将三维场景重建问题建模为一个条件扩散过程。通过学习一个图像条件的3D场景扩散模型,该模型能够同时对场景中所有物体的3D姿态和几何形状进行去噪。为了保证场景的一致性,模型学习场景先验,并显式地建模对象间的关系。
技术框架:该方法包含以下主要模块:1) 图像编码器:提取输入RGB图像的特征。2) 3D场景扩散模型:以图像特征为条件,对初始噪声3D场景进行迭代去噪,逐步恢复场景中物体的姿态和几何形状。3) 形状表示:使用一种富有表现力的形状表示,允许从中间形状预测中进行点采样。4) 损失函数:包括扩散模型的标准损失以及一个新颖的表面对齐损失,用于在缺乏完整ground-truth的情况下进行训练。
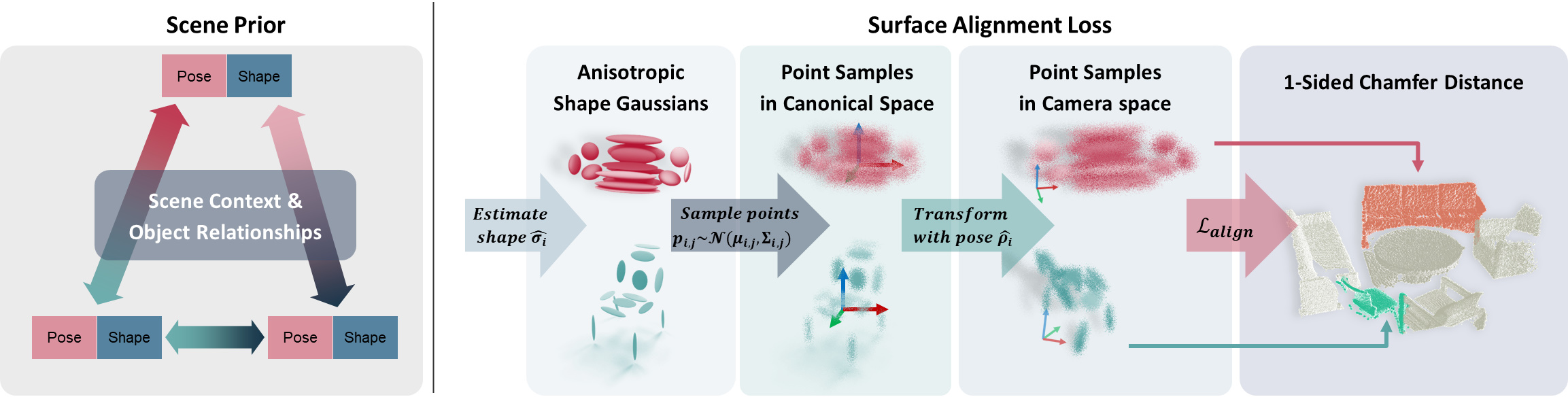
关键创新:该方法最重要的创新点在于将扩散模型应用于三维场景重建,并显式地建模场景先验和对象间关系。与现有方法相比,该方法能够更好地处理任务的不适定性,并生成更连贯的场景重建结果。此外,提出的表面对齐损失能够在不依赖完整ground-truth的情况下进行有效训练。
关键设计:扩散模型采用U-Net架构,以图像特征和当前噪声场景为输入,预测噪声的梯度。表面对齐损失通过采样中间形状预测的点云,并将其与部分ground-truth进行对齐来计算。形状表示采用隐式曲面表示,允许高效的点采样。训练过程中,使用Adam优化器,并采用学习率衰减策略。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在SUN RGB-D和Pix3D数据集上显著优于现有技术。在SUN RGB-D数据集上,该方法实现了12.04%的AP3D提升。在Pix3D数据集上,该方法实现了13.43%的F-Score提升。这些结果表明,该方法能够有效地进行连贯的三维场景重建,并具有很强的泛化能力。
🎯 应用场景
该研究成果可应用于机器人导航、增强现实、虚拟现实、自动驾驶等领域。例如,机器人可以利用该技术从单张图像中理解周围环境的三维结构,从而进行更智能的导航和交互。在增强现实中,该技术可以用于将虚拟物体无缝地融入真实场景中。该技术还有潜力应用于三维场景编辑和内容生成。
📄 摘要(原文)
We present a novel diffusion-based approach for coherent 3D scene reconstruction from a single RGB image. Our method utilizes an image-conditioned 3D scene diffusion model to simultaneously denoise the 3D poses and geometries of all objects within the scene. Motivated by the ill-posed nature of the task and to obtain consistent scene reconstruction results, we learn a generative scene prior by conditioning on all scene objects simultaneously to capture the scene context and by allowing the model to learn inter-object relationships throughout the diffusion process. We further propose an efficient surface alignment loss to facilitate training even in the absence of full ground-truth annotation, which is common in publicly available datasets. This loss leverages an expressive shape representation, which enables direct point sampling from intermediate shape predictions. By framing the task of single RGB image 3D scene reconstruction as a conditional diffusion process, our approach surpasses current state-of-the-art methods, achieving a 12.04% improvement in AP3D on SUN RGB-D and a 13.43% increase in F-Score on Pix3D.