Prompt-Guided Mask Proposal for Two-Stage Open-Vocabulary Segmentation
作者: Yu-Jhe Li, Xinyang Zhang, Kun Wan, Lantao Yu, Ajinkya Kale, Xin Lu
分类: cs.CV
发布日期: 2024-12-13
备注: 17 pages. Work done during 2023 summer and has been released
💡 一句话要点
提出Prompt引导的掩码提议网络PMP,用于两阶段开放词汇分割。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 开放词汇分割 掩码提议生成 文本提示引导 交叉注意力机制 两阶段分割 多模态学习
📋 核心要点
- 现有开放词汇分割方法依赖于图像生成的掩码提议,可能无法覆盖所有目标,导致分割精度受限。
- PMP通过文本提示引导掩码生成,使生成的掩码提议与目标文本描述对齐,从而提高分割准确率。
- 实验表明,PMP在多个数据集上显著提升了开放词汇分割的性能,证明了其有效性和泛化能力。
📝 摘要(中文)
本文旨在解决开放词汇分割的挑战,即利用文本提示识别不同环境中各种类别的对象。现有方法通常采用CLIP等多模态模型,将图像和文本特征映射到共享嵌入空间,以弥合有限词汇和广泛词汇识别之间的差距,形成两阶段方法:第一阶段,掩码生成器接收输入图像并生成掩码提议;第二阶段,根据查询选择目标掩码。然而,生成的掩码提议中可能不存在期望的目标掩码,导致输出错误。为此,我们提出了一种名为Prompt引导的掩码提议(PMP)的新方法,其中掩码生成器接收输入文本提示,并在这些提示的指导下生成掩码。与没有输入提示生成的掩码提议相比,PMP生成的掩码与输入提示更好地对齐。为了实现PMP,我们设计了一种文本token和查询token之间的交叉注意力机制,能够在每次解码后生成prompt引导的掩码提议。我们将PMP与几种现有的基于查询的分割骨干网络相结合,在五个基准数据集上的实验表明了该方法的有效性,与当前的二阶段模型相比,性能有了显著提高(mIOU绝对性能提升1%~3%)。在这些基准测试中性能的稳定提高表明了我们提出的轻量级prompt感知方法的有效泛化能力。
🔬 方法详解
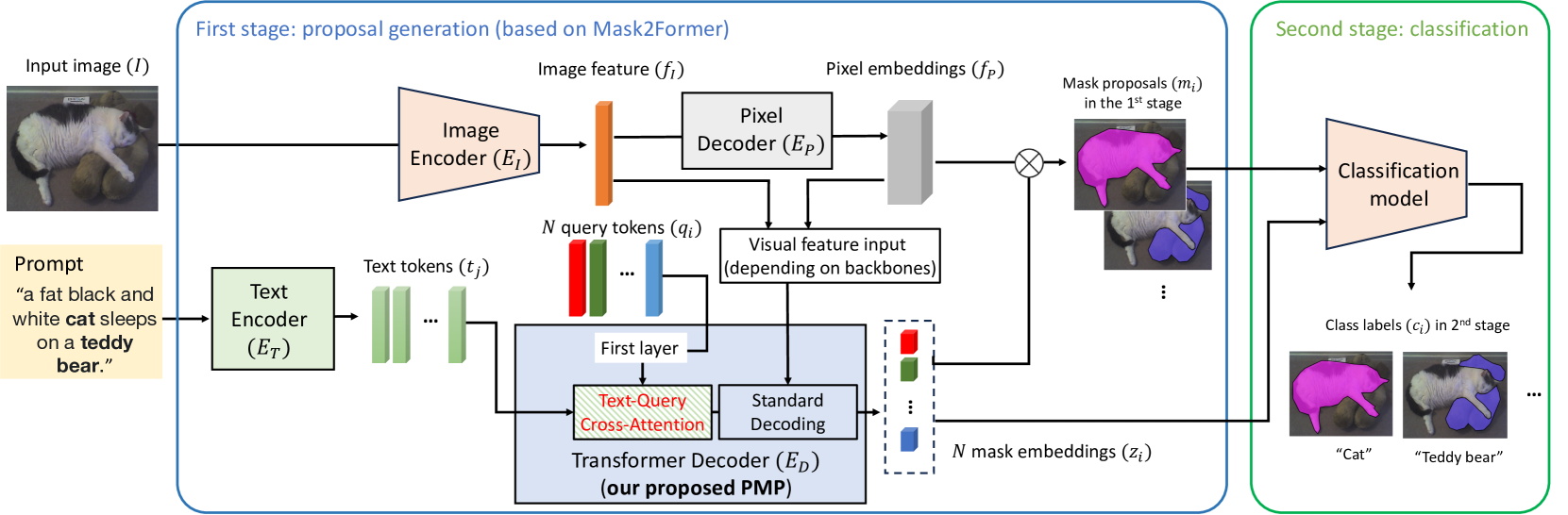
问题定义:开放词汇分割旨在识别图像中属于任意文本描述类别的对象。现有两阶段方法的瓶颈在于,第一阶段生成的掩码提议可能不包含与文本描述对应的目标对象,导致后续的分割精度受限。
核心思路:核心思路是在掩码提议生成阶段引入文本提示的引导,使得生成的掩码提议能够更好地与文本描述对齐。通过文本提示,掩码生成器能够更有针对性地生成包含目标对象的掩码,从而提高分割的召回率和准确率。
技术框架:PMP方法基于两阶段分割框架。第一阶段,Prompt引导的掩码提议生成器(PMP)接收图像和文本提示作为输入,生成与文本描述相关的掩码提议。第二阶段,利用现有的基于查询的分割骨干网络,对生成的掩码提议进行评分和选择,最终得到分割结果。PMP模块替换了原有的无prompt的掩码提议生成器。
关键创新:关键创新在于Prompt引导的掩码提议生成器(PMP)。PMP通过引入文本提示,改变了传统掩码生成器仅依赖图像信息的模式。PMP使用交叉注意力机制,将文本token的信息融入到掩码提议的生成过程中,从而实现了prompt引导的掩码提议生成。
关键设计:PMP的关键设计在于文本token和查询token之间的交叉注意力机制。具体来说,文本token通过一个文本编码器进行编码,然后与掩码生成器的查询token进行交叉注意力计算,从而将文本信息融入到查询token中。经过交叉注意力计算后的查询token,用于生成prompt引导的掩码提议。损失函数方面,可以使用标准的分割损失函数,例如Dice Loss或Focal Loss。
🖼️ 关键图片


📊 实验亮点
实验结果表明,PMP方法在五个基准数据集上均取得了显著的性能提升,mIOU绝对性能提升1%~3%。与现有二阶段模型相比,PMP能够更准确地生成与文本描述相关的掩码提议,从而提高分割精度。实验结果验证了PMP方法的有效性和泛化能力。
🎯 应用场景
该研究成果可应用于智能图像编辑、自动驾驶、机器人视觉等领域。例如,在智能图像编辑中,用户可以通过文本描述快速选择和编辑图像中的特定对象。在自动驾驶中,可以利用文本提示识别交通标志、行人等关键目标。在机器人视觉中,可以根据指令让机器人识别和操作特定物体。
📄 摘要(原文)
We tackle the challenge of open-vocabulary segmentation, where we need to identify objects from a wide range of categories in different environments, using text prompts as our input. To overcome this challenge, existing methods often use multi-modal models like CLIP, which combine image and text features in a shared embedding space to bridge the gap between limited and extensive vocabulary recognition, resulting in a two-stage approach: In the first stage, a mask generator takes an input image to generate mask proposals, and the in the second stage the target mask is picked based on the query. However, the expected target mask may not exist in the generated mask proposals, which leads to an unexpected output mask. In our work, we propose a novel approach named Prompt-guided Mask Proposal (PMP) where the mask generator takes the input text prompts and generates masks guided by these prompts. Compared with mask proposals generated without input prompts, masks generated by PMP are better aligned with the input prompts. To realize PMP, we designed a cross-attention mechanism between text tokens and query tokens which is capable of generating prompt-guided mask proposals after each decoding. We combined our PMP with several existing works employing a query-based segmentation backbone and the experiments on five benchmark datasets demonstrate the effectiveness of this approach, showcasing significant improvements over the current two-stage models (1% ~ 3% absolute performance gain in terms of mIOU). The steady improvement in performance across these benchmarks indicates the effective generalization of our proposed lightweight prompt-aware method.