SuperGSeg: Open-Vocabulary 3D Segmentation with Structured Super-Gaussians
作者: Siyun Liang, Sen Wang, Kunyi Li, Michael Niemeyer, Stefano Gasperini, Hendrik P. A. Lensch, Nassir Navab, Federico Tombari
分类: cs.CV
发布日期: 2024-12-13 (更新: 2026-01-20)
备注: 13 pages, 8 figures. Project page: supergseg.github.io
💡 一句话要点
SuperGSeg:利用结构化超高斯实现开放词汇3D分割
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D场景理解 高斯溅射 开放词汇分割 超高斯 语言特征蒸馏
📋 核心要点
- 现有方法在3D场景理解中,直接在高斯模型中存储高维语义特征,导致内存消耗过大,难以处理复杂场景。
- SuperGSeg通过解耦分割和语言场蒸馏,构建上下文感知的分层场景表示,从而实现高效的开放词汇3D分割。
- 实验结果表明,SuperGSeg在开放词汇对象选择和语义分割任务上表现出色,验证了其有效性。
📝 摘要(中文)
3D高斯溅射因其高效的训练和实时渲染而备受关注。虽然其原始表示主要为视图合成而设计,但最近的研究将其扩展到具有语言特征的场景理解。然而,为每个高斯存储额外的用于语义信息的高维特征会消耗大量内存,这限制了它们分割和解释复杂场景的能力。为此,我们引入了SuperGSeg,这是一种新颖的方法,通过解耦分割和语言场蒸馏来促进有凝聚力的、上下文感知的分层场景表示。SuperGSeg首先利用神经3D高斯,借助现成的2D掩码,从多视图图像中学习几何、实例和分层分割特征。然后,这些特征被用于创建一组稀疏的超高斯。超高斯有助于将2D语言特征提升和提炼到3D空间中。它们能够以适中的GPU内存成本实现具有高维语言特征渲染的分层场景理解。大量的实验表明,SuperGSeg在开放词汇对象选择和语义分割任务上都取得了显著的性能。
🔬 方法详解
问题定义:现有的基于3D高斯溅射的场景理解方法,为了赋予高斯模型语义信息,直接为每个高斯存储高维的语言特征。这种做法虽然简单直接,但会显著增加内存占用,尤其是在处理复杂场景时,高斯数量庞大,导致内存瓶颈,限制了模型对场景的分割和理解能力。因此,如何降低内存消耗,同时保持甚至提升场景理解能力,是本文要解决的核心问题。
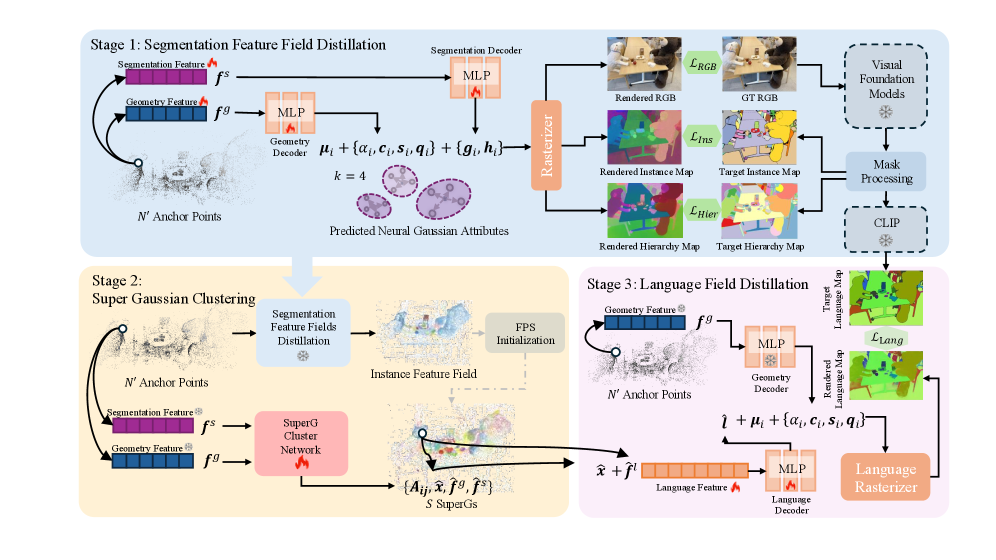
核心思路:SuperGSeg的核心思路是将分割和语言特征的学习解耦。首先,利用2D掩码信息,从多视角图像中学习几何、实例和分层分割特征,并基于这些特征构建稀疏的超高斯表示。然后,利用这些超高斯将2D语言特征提升和提炼到3D空间中。通过这种方式,避免了直接在高斯模型中存储高维语言特征,从而降低了内存消耗。同时,超高斯结构能够捕捉场景的上下文信息,提升分割和理解能力。
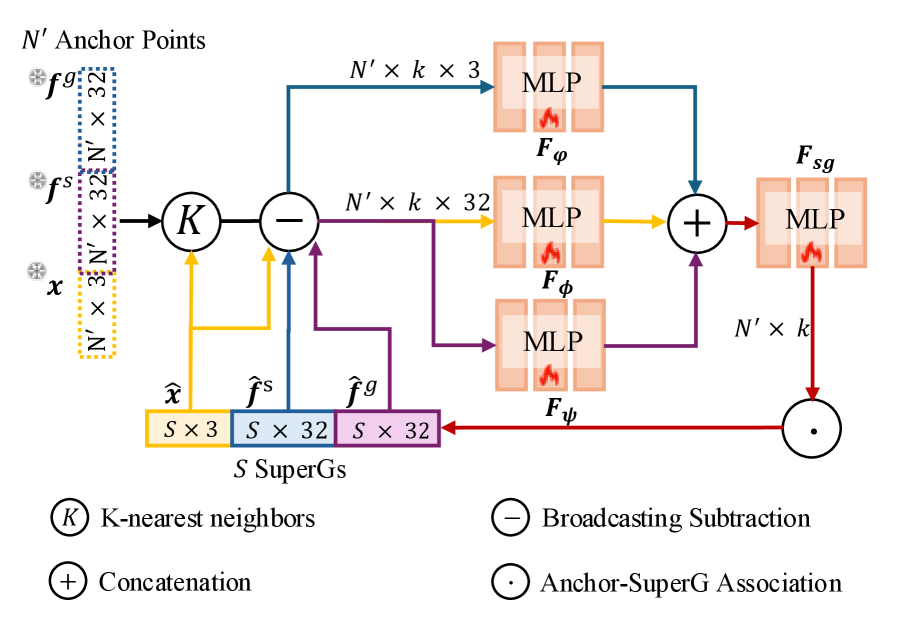
技术框架:SuperGSeg的整体框架包含以下几个主要阶段:1) 特征学习阶段:利用多视角图像和2D掩码,训练神经3D高斯网络,学习几何、实例和分层分割特征。2) 超高斯构建阶段:基于学习到的特征,构建稀疏的超高斯表示。超高斯是由多个相邻且具有相似特征的高斯聚类而成。3) 语言特征蒸馏阶段:将2D语言特征提升并提炼到3D超高斯中。4) 场景理解阶段:利用学习到的超高斯表示和语言特征,进行开放词汇对象选择和语义分割。
关键创新:SuperGSeg最关键的创新在于引入了超高斯结构,并将其用于解耦分割和语言特征的学习。与直接在高斯模型中存储高维语言特征的方法相比,SuperGSeg通过超高斯结构,实现了更高效的内存管理和更强的上下文感知能力。此外,SuperGSeg还提出了一种新的语言特征蒸馏方法,能够有效地将2D语言特征迁移到3D空间中。
关键设计:在超高斯构建阶段,需要确定如何将高斯聚类成超高斯。论文可能采用了基于特征相似度的聚类算法,例如K-means或谱聚类。在语言特征蒸馏阶段,可能使用了注意力机制或transformer结构,以选择性地将2D语言特征迁移到3D超高斯中。损失函数的设计可能包括分割损失、重建损失和语言对齐损失,以确保模型能够学习到有效的几何、语义和语言特征。
🖼️ 关键图片
📊 实验亮点
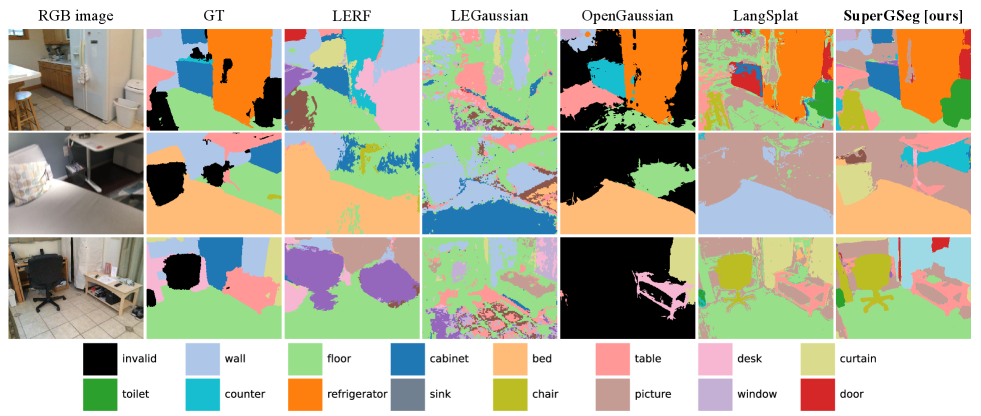
SuperGSeg在开放词汇对象选择和语义分割任务上取得了显著的性能提升。具体而言,SuperGSeg在多个数据集上超越了现有的基于3D高斯溅射的方法,尤其是在处理复杂场景时,其性能优势更加明显。这些实验结果充分证明了SuperGSeg的有效性和优越性。
🎯 应用场景
SuperGSeg在机器人导航、自动驾驶、虚拟现实和增强现实等领域具有广泛的应用前景。它可以用于构建更智能、更高效的3D场景理解系统,使机器人能够更好地感知和理解周围环境,从而实现更安全、更可靠的自主导航。此外,SuperGSeg还可以用于创建更逼真的虚拟现实和增强现实体验,例如,用户可以通过自然语言与虚拟场景进行交互。
📄 摘要(原文)
3D Gaussian Splatting has recently gained traction for its efficient training and real-time rendering. While its vanilla representation is mainly designed for view synthesis, recent works extended it to scene understanding with language features. However, storing additional high-dimensional features per Gaussian for semantic information is memory-intensive, which limits their ability to segment and interpret challenging scenes. To this end, we introduce SuperGSeg, a novel approach that fosters cohesive, context-aware hierarchical scene representation by disentangling segmentation and language field distillation. SuperGSeg first employs neural 3D Gaussians to learn geometry, instance and hierarchical segmentation features from multi-view images with the aid of off-the-shelf 2D masks. These features are then leveraged to create a sparse set of \acrlong{superg}s. \acrlong{superg}s facilitate the lifting and distillation of 2D language features into 3D space. They enable hierarchical scene understanding with high-dimensional language feature rendering at moderate GPU memory costs. Extensive experiments demonstrate that SuperGSeg achieves remarkable performance on both open-vocabulary object selection and semantic segmentation tasks.