GAF: Gaussian Avatar Reconstruction from Monocular Videos via Multi-view Diffusion
作者: Jiapeng Tang, Davide Davoli, Tobias Kirschstein, Liam Schoneveld, Matthias Niessner
分类: cs.CV, cs.AI, cs.GR
发布日期: 2024-12-13 (更新: 2025-04-14)
备注: Paper Video: https://youtu.be/QuIYTljvhyg Project Page: https://tangjiapeng.github.io/projects/GAF
💡 一句话要点
提出GAF,利用多视角扩散模型从单目视频重建高逼真度可动画3D高斯头像
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D人脸重建 单目视频 扩散模型 高斯溅射 新视角合成
📋 核心要点
- 单目视频重建3D头像面临观测不足的挑战,导致新视角合成时出现伪影,影响真实感。
- GAF利用多视角扩散模型,结合FLAME法线贴图和VAE特征,实现视角一致性和身份保留。
- 实验表明,GAF在NeRSemble数据集上超越现有方法,并能从消费级设备视频重建高保真头像。
📝 摘要(中文)
本文提出了一种新方法,用于从智能手机等消费级设备拍摄的单目视频中重建可动画的3D高斯头像。由于观测有限,从这类记录中重建逼真的3D头部头像极具挑战性,未观测到的区域约束不足,可能导致新视角中出现伪影。为了解决这个问题,我们引入了一个多视角头部扩散模型,利用其先验来填充缺失区域,并确保高斯溅射渲染中的视角一致性。为了实现精确的视点控制,我们使用从基于FLAME的头部重建渲染的法线贴图,这提供了像素对齐的归纳偏置。我们还将扩散模型以从输入图像中提取的VAE特征为条件,以保留面部身份和外观细节。对于高斯头像重建,我们通过使用迭代去噪图像作为伪真值来提炼多视角扩散先验,有效地缓解了过度饱和问题。为了进一步提高照片真实感,我们应用潜在上采样先验来细化去噪的潜在变量,然后将其解码为图像。我们在NeRSemble数据集上评估了我们的方法,表明GAF在新的视角合成方面优于以前最先进的方法。此外,我们还展示了从消费级设备上捕获的单目视频中更高保真度的头像重建。
🔬 方法详解
问题定义:从单目视频重建高质量、可动画的3D人脸头像是一个极具挑战性的问题。现有的方法在处理单目视频时,由于视角信息不足,导致重建出的3D模型在新视角下出现伪影,并且难以保持身份信息和细节,真实感较差。
核心思路:本文的核心思路是利用多视角扩散模型的强大先验知识,来填充单目视频中缺失的视角信息,从而提高重建质量。通过将扩散模型与高斯溅射渲染相结合,并引入FLAME法线贴图和VAE特征作为条件,可以实现视角一致性和身份保留,最终得到高质量的3D人脸头像。
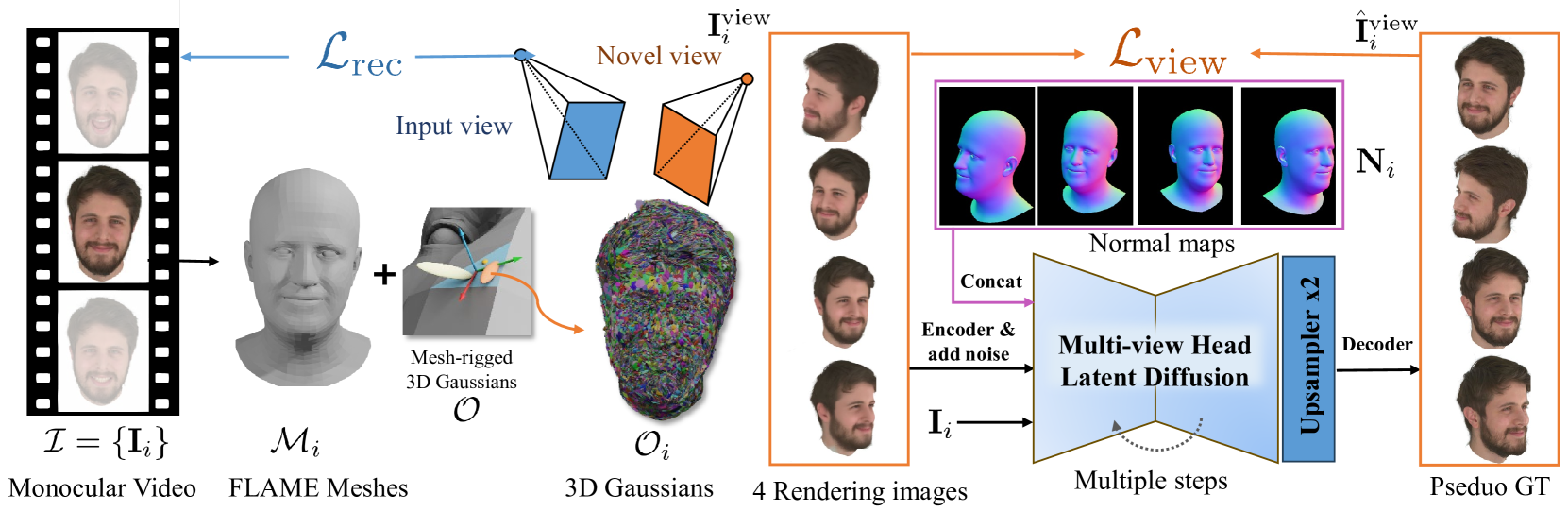
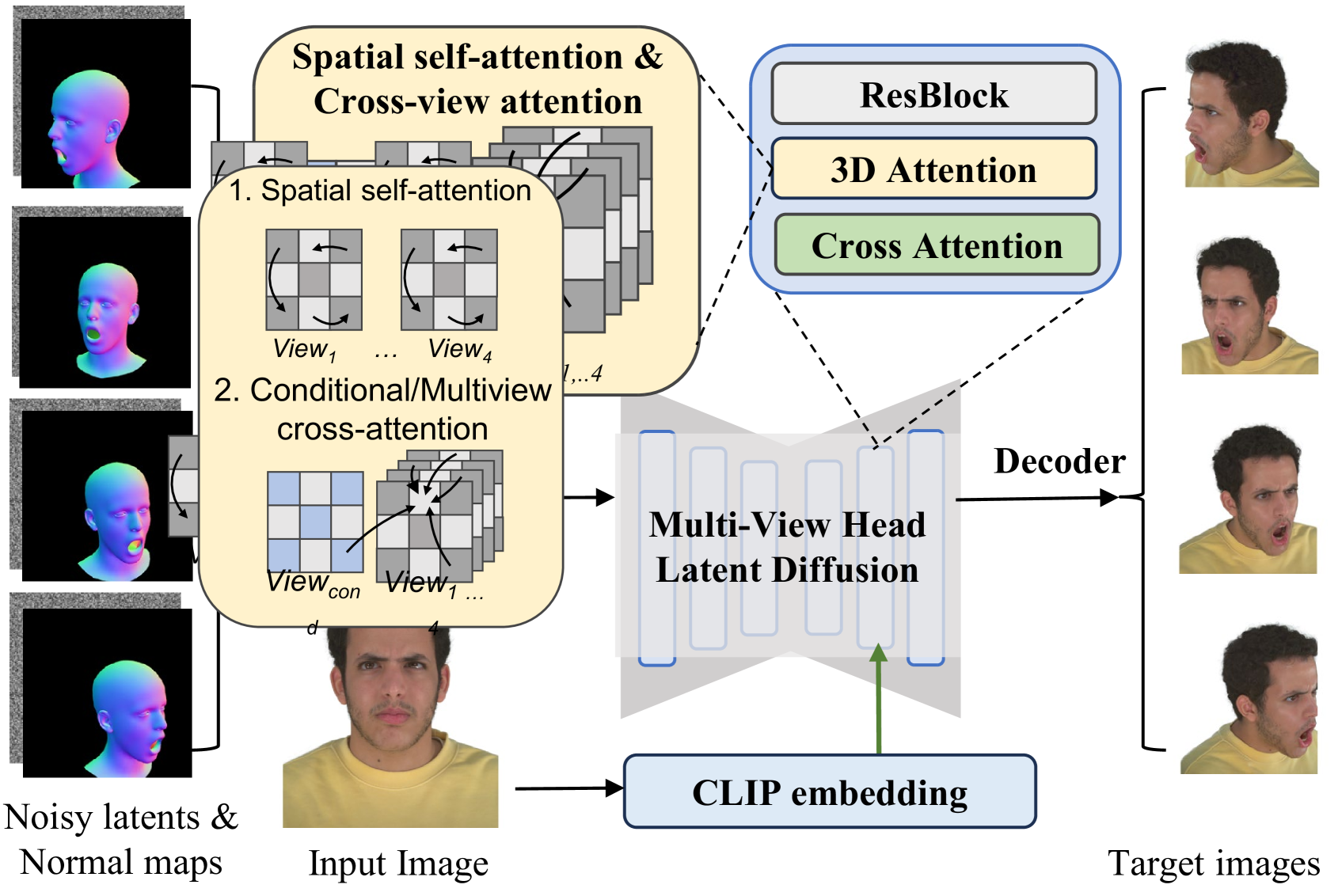
技术框架:GAF的整体框架包含以下几个主要阶段:1) 使用FLAME模型进行初始人脸重建,并渲染法线贴图;2) 从输入图像中提取VAE特征;3) 使用多视角扩散模型,以法线贴图和VAE特征为条件,生成多视角图像;4) 使用迭代去噪图像作为伪真值,提炼多视角扩散先验,缓解过度饱和问题;5) 应用潜在上采样先验来细化去噪的潜在变量,然后将其解码为图像;6) 使用高斯溅射渲染生成最终的3D人脸头像。
关键创新:GAF的关键创新在于将多视角扩散模型引入到单目视频人脸重建任务中。与传统的基于几何或纹理的方法不同,GAF利用扩散模型的生成能力,可以有效地填充缺失的视角信息,并生成高质量的新视角图像。此外,GAF还引入了FLAME法线贴图和VAE特征作为条件,从而实现了更精确的视角控制和身份保留。
关键设计:GAF的关键设计包括:1) 使用FLAME模型渲染的法线贴图作为扩散模型的条件,提供像素对齐的归纳偏置;2) 使用VAE特征作为扩散模型的条件,保留面部身份和外观细节;3) 使用迭代去噪图像作为伪真值,提炼多视角扩散先验,缓解过度饱和问题;4) 应用潜在上采样先验来细化去噪的潜在变量,提高图像分辨率和细节。
🖼️ 关键图片

📊 实验亮点
GAF在NeRSemble数据集上取得了显著的性能提升,超越了现有的SOTA方法。实验结果表明,GAF能够从单目视频中重建出更高质量、更逼真的3D人脸头像,尤其是在新视角合成方面表现出色。此外,GAF还展示了从消费级设备拍摄的视频中重建高保真头像的能力,证明了其在实际应用中的可行性。
🎯 应用场景
GAF技术可广泛应用于虚拟现实、增强现实、游戏、视频会议等领域。例如,用户可以使用智能手机拍摄一段视频,即可生成自己的高逼真度3D头像,用于虚拟形象、社交互动或个性化定制。该技术还能提升远程协作的真实感,并为数字内容创作提供更便捷的工具,具有广阔的应用前景。
📄 摘要(原文)
We propose a novel approach for reconstructing animatable 3D Gaussian avatars from monocular videos captured by commodity devices like smartphones. Photorealistic 3D head avatar reconstruction from such recordings is challenging due to limited observations, which leaves unobserved regions under-constrained and can lead to artifacts in novel views. To address this problem, we introduce a multi-view head diffusion model, leveraging its priors to fill in missing regions and ensure view consistency in Gaussian splatting renderings. To enable precise viewpoint control, we use normal maps rendered from FLAME-based head reconstruction, which provides pixel-aligned inductive biases. We also condition the diffusion model on VAE features extracted from the input image to preserve facial identity and appearance details. For Gaussian avatar reconstruction, we distill multi-view diffusion priors by using iteratively denoised images as pseudo-ground truths, effectively mitigating over-saturation issues. To further improve photorealism, we apply latent upsampling priors to refine the denoised latent before decoding it into an image. We evaluate our method on the NeRSemble dataset, showing that GAF outperforms previous state-of-the-art methods in novel view synthesis. Furthermore, we demonstrate higher-fidelity avatar reconstructions from monocular videos captured on commodity devices.