Quaffure: Real-Time Quasi-Static Neural Hair Simulation
作者: Tuur Stuyck, Gene Wei-Chin Lin, Egor Larionov, Hsiao-yu Chen, Aljaz Bozic, Nikolaos Sarafianos, Doug Roble
分类: cs.CV, cs.GR
发布日期: 2024-12-13 (更新: 2025-04-11)
备注: CVPR 2025
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
Quaffure:实时准静态神经头发模拟,提升虚拟形象真实感
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 头发模拟 神经渲染 实时渲染 自监督学习 虚拟形象 准静态模拟 物理模拟
📋 核心要点
- 现有实时头发模拟方法计算资源需求高,难以兼顾真实感和效率,限制了虚拟形象的应用。
- Quaffure 提出一种基于神经网络的准静态头发模拟方法,通过自监督学习预测头发形变,无需大量数据。
- 实验表明,该方法在各种姿势和形状下具有良好的泛化能力,推理速度快,适合实时应用,可扩展性强。
📝 摘要(中文)
逼真的头发运动对于高质量的虚拟形象至关重要,但通常受到实时应用中可用计算资源的限制。为了解决这一挑战,我们提出了一种新颖的神经方法,用于预测物理上合理的头发形变,该方法可以推广到各种身体姿势、形状和发型。我们的模型使用自监督损失进行训练,无需昂贵的数据生成和存储。通过大量姿势和形状变化的结果,我们展示了该方法的有效性,展示了其强大的泛化能力和时间上的平滑结果。我们的方法非常适合实时应用,在消费级硬件上的推理时间仅为几毫秒,并且能够扩展到在0.3秒内预测1000个发型的悬垂。
🔬 方法详解
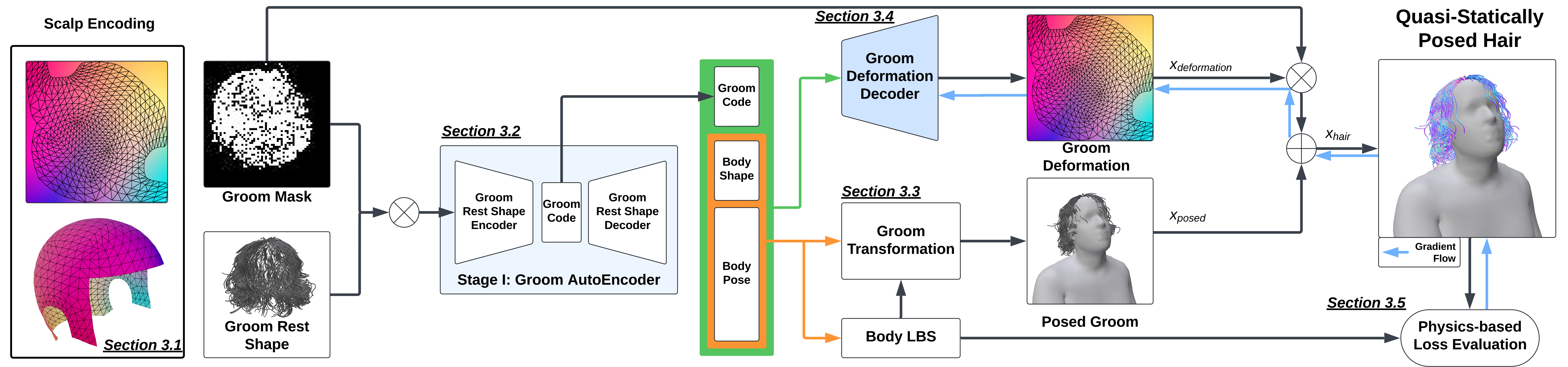
问题定义:论文旨在解决实时虚拟形象中头发模拟的计算瓶颈问题。现有基于物理的头发模拟方法虽然能产生逼真的效果,但计算复杂度高,难以满足实时性要求。此外,传统方法对不同姿势、体型和发型的泛化能力有限,需要大量针对特定情况的参数调整。
核心思路:论文的核心思路是利用神经网络学习头发的准静态形变模式。准静态假设简化了头发的动力学计算,降低了计算复杂度。通过神经网络学习头发形变与身体姿势、形状和发型之间的映射关系,实现快速且具有泛化能力的头发模拟。
技术框架:Quaffure 的整体框架包括以下几个主要步骤:1) 输入身体姿势、形状和发型参数;2) 通过训练好的神经网络预测头发的形变;3) 将预测的形变应用于头发模型,实现头发的实时模拟。该框架采用端到端的训练方式,无需手动设计复杂的物理模型。
关键创新:该方法最重要的创新点在于使用自监督学习训练神经网络。通过设计合适的自监督损失函数,模型可以从无标签数据中学习头发的形变规律,避免了昂贵的数据标注过程。此外,该方法还采用了准静态假设,简化了头发的动力学计算,提高了计算效率。
关键设计:论文中使用了多层感知机(MLP)作为神经网络的结构。输入包括身体姿势、形状和发型参数,输出为头发顶点的位移。自监督损失函数包括形变能量损失和碰撞损失,用于约束头发的形变符合物理规律,并避免头发穿透身体。具体的网络结构和损失函数参数需要在实验中进行调整,以达到最佳的性能。
🖼️ 关键图片


📊 实验亮点
该方法在消费级硬件上实现了毫秒级的推理速度,能够实时模拟头发的运动。实验结果表明,该方法在各种姿势、体型和发型下都具有良好的泛化能力,能够生成逼真的头发形变。此外,该方法还具有良好的可扩展性,能够在0.3秒内预测1000个发型的悬垂,表明其适用于大规模的虚拟场景。
🎯 应用场景
该研究成果可广泛应用于虚拟现实、增强现实、游戏、动画制作等领域。它可以提升虚拟形象的真实感和交互体验,例如在虚拟会议、在线教育、虚拟试衣等场景中,逼真的头发模拟可以增强用户的沉浸感。此外,该方法还可以用于创建更具表现力的虚拟角色,例如在游戏中,不同的发型和头发运动可以反映角色的个性和情感。
📄 摘要(原文)
Realistic hair motion is crucial for high-quality avatars, but it is often limited by the computational resources available for real-time applications. To address this challenge, we propose a novel neural approach to predict physically plausible hair deformations that generalizes to various body poses, shapes, and hairstyles. Our model is trained using a self-supervised loss, eliminating the need for expensive data generation and storage. We demonstrate our method's effectiveness through numerous results across a wide range of pose and shape variations, showcasing its robust generalization capabilities and temporally smooth results. Our approach is highly suitable for real-time applications with an inference time of only a few milliseconds on consumer hardware and its ability to scale to predicting the drape of 1000 grooms in 0.3 seconds. Please see our project page here following https://tuurstuyck.github.io/quaffure/quaffure.html