Towards Consistent and Efficient Dataset Distillation via Diffusion-Driven Selection
作者: Xinhao Zhong, Shuoyang Sun, Xulin Gu, Zhaoyang Xu, Yaowei Wang, Min Zhang, Bin Chen
分类: cs.CV
发布日期: 2024-12-13 (更新: 2025-11-13)
💡 一句话要点
提出基于扩散驱动选择的数据集蒸馏方法,提升一致性和效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 数据集蒸馏 扩散模型 patch选择 类内聚类 图像识别
📋 核心要点
- 大规模数据集蒸馏面临优化空间巨大、蒸馏效果受限的挑战,现有方法难以兼顾效率和一致性。
- 利用预训练扩散模型进行patch选择,而非直接生成图像,从而避免分布偏移问题,实现高效蒸馏。
- 通过类内聚类和排序增强patch的多样性,实验证明该方法在多种设置下优于现有技术。
📝 摘要(中文)
数据集蒸馏通过优化一个紧凑的数据集来降低内存和计算成本,使其性能与完整原始数据集相当。然而,对于大规模数据集和复杂的深度网络(例如,带有ResNet-101的ImageNet-1K),巨大的优化空间阻碍了蒸馏效果,限制了实际应用。最近的方法利用预训练的扩散模型直接生成信息丰富的图像,从而绕过像素级优化并取得有希望的结果。然而,这些方法通常受到预训练扩散先验和目标数据集之间的分布偏移的影响,并且需要在不同的设置下进行多个蒸馏步骤。为了克服这些挑战,我们提出了一种新颖的框架,它通过利用扩散先验进行patch选择而不是生成,与现有的基于扩散的蒸馏技术正交。我们的方法预测扩散模型在输入图像和可选文本提示(有或没有标签信息)条件下产生的噪声,并计算每个图像-patch对的相关损失。基于损失差异,我们识别原始图像中独特的区域。此外,我们在所选patch上应用类内聚类和排序,以强制执行多样性约束。这种简化的流程能够实现一步蒸馏过程。大量的实验表明,我们的方法在各种指标和设置下始终优于最先进的方法。
🔬 方法详解
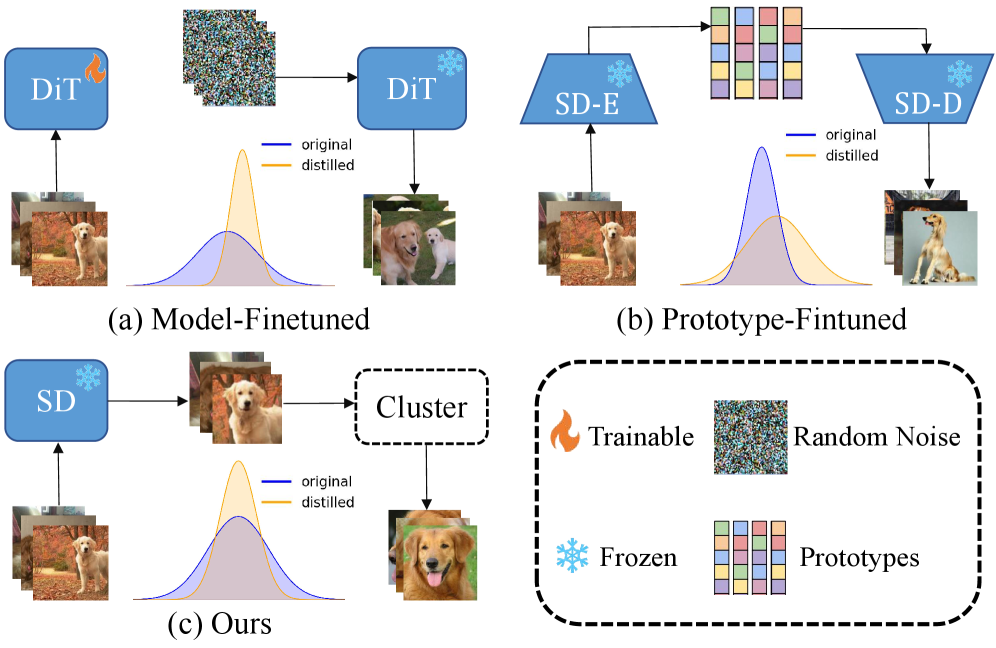
问题定义:数据集蒸馏旨在从原始大数据集中提取一个小的、具有代表性的子集,使得在这个子集上训练的模型能够达到与在完整数据集上训练的模型相近的性能。现有的基于扩散模型的数据集蒸馏方法,虽然避免了像素级别的优化,但容易受到预训练扩散模型与目标数据集之间分布偏移的影响,并且需要多步蒸馏,效率较低。
核心思路:本文的核心思路是利用扩散模型作为一种先验知识,指导从原始图像中选择最具代表性的patch,而不是直接生成新的图像。通过分析扩散模型预测的噪声与原始图像patch之间的关系,可以识别出图像中信息量最大的区域,从而实现高效且一致的数据集蒸馏。
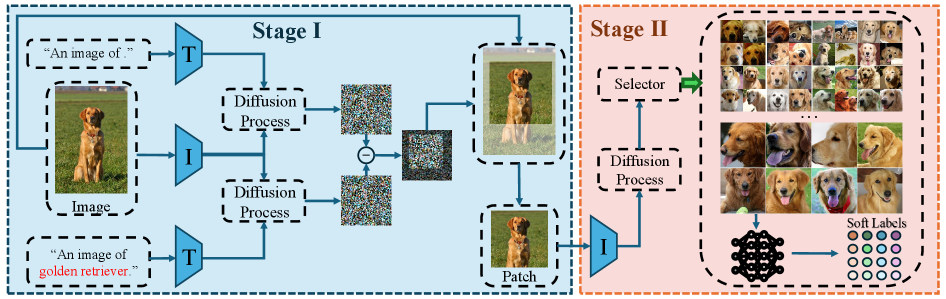
技术框架:该方法主要包含以下几个步骤:1) 噪声预测:使用预训练的扩散模型,在输入图像和可选的文本提示(包含或不包含标签信息)的条件下,预测图像中的噪声。2) 损失计算:计算每个图像patch与其对应噪声之间的损失。3) Patch选择:基于损失差异,选择原始图像中具有代表性的区域。4) 类内聚类和排序:在选择的patch上进行类内聚类,并根据聚类结果进行排序,以保证patch的多样性。5) 数据集构建:将选择的patch组合成蒸馏后的数据集。
关键创新:该方法最重要的创新点在于将扩散模型应用于patch选择而非图像生成。这种方法避免了直接生成图像可能带来的分布偏移问题,并且能够更有效地利用原始图像的信息。此外,通过类内聚类和排序,进一步增强了蒸馏数据集的多样性,提高了模型的泛化能力。
关键设计:在噪声预测阶段,可以使用不同的扩散模型架构和训练策略。损失函数的选择也很重要,常用的损失函数包括均方误差(MSE)等。类内聚类可以使用K-means等算法,排序可以基于聚类中心与patch之间的距离。文本提示的使用可以进一步引导patch的选择,使其更符合特定任务的需求。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在多个数据集和模型上均优于现有的数据集蒸馏方法。例如,在ImageNet-1K数据集上,使用ResNet-101模型进行训练,该方法能够以更少的蒸馏数据达到与使用完整数据集训练的模型相近的性能,并且在一致性和效率方面均有显著提升。
🎯 应用场景
该研究成果可应用于各种需要减少数据存储和计算成本的场景,例如移动设备上的图像识别、边缘计算环境下的目标检测、以及大规模数据集上的快速模型训练。通过数据集蒸馏,可以在资源受限的环境下部署高性能的深度学习模型,并加速模型开发和迭代过程。
📄 摘要(原文)
Dataset distillation provides an effective approach to reduce memory and computational costs by optimizing a compact dataset that achieves performance comparable to the full original. However, for large-scale datasets and complex deep networks (e.g., ImageNet-1K with ResNet-101), the vast optimization space hinders distillation effectiveness, limiting practical applications. Recent methods leverage pre-trained diffusion models to directly generate informative images, thereby bypassing pixel-level optimization and achieving promising results. Nonetheless, these approaches often suffer from distribution shifts between the pre-trained diffusion prior and target datasets, as well as the need for multiple distillation steps under varying settings. To overcome these challenges, we propose a novel framework that is orthogonal to existing diffusion-based distillation techniques by utilizing the diffusion prior for patch selection rather than generation. Our method predicts noise from the diffusion model conditioned on input images and optional text prompts (with or without label information), and computes the associated loss for each image-patch pair. Based on the loss differences, we identify distinctive regions within the original images. Furthermore, we apply intra-class clustering and ranking on the selected patches to enforce diversity constraints. This streamlined pipeline enables a one-step distillation process. Extensive experiments demonstrate that our approach consistently outperforms state-of-the-art methods across various metrics and settings.