MulSMo: Multimodal Stylized Motion Generation by Bidirectional Control Flow
作者: Zhe Li, Yisheng He, Lei Zhong, Weichao Shen, Qi Zuo, Lingteng Qiu, Zilong Dong, Laurence Tianruo Yang, Weihao Yuan
分类: cs.CV
发布日期: 2024-12-13 (更新: 2025-03-17)
💡 一句话要点
MulSMo:通过双向控制流实现多模态风格化运动生成。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱四:生成式动作 (Generative Motion) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 风格化运动生成 双向控制流 多模态融合 对比学习 运动生成
📋 核心要点
- 现有风格化运动生成方法信息流通常为单向,易导致风格与内容冲突,影响融合效果。
- 本文构建风格与内容间的双向控制流,使风格适应内容,缓解冲突,保留风格动态性。
- 通过对比学习,将风格控制扩展到文本、图像等多模态,实验表明性能显著优于现有方法。
📝 摘要(中文)
本文提出了一种新的风格化运动生成方法,该方法通过双向控制流来协调内容提示和目标风格。与现有方法中信息单向流动(从风格到内容)不同,本文构建了风格和内容之间的双向控制流,从而调整风格以适应内容,缓解了风格与内容之间的冲突,并更好地保留了风格的动态性。此外,通过对比学习,本文将风格化运动生成从单一模态(风格运动)扩展到包括文本和图像在内的多种模态,从而实现了对运动生成的灵活风格控制。大量实验表明,本文方法在不同数据集上显著优于现有方法,并且支持多模态信号控制。代码将公开。
🔬 方法详解
问题定义:现有风格化运动生成方法主要痛点在于风格信息通常单向地影响内容生成,导致风格与内容之间容易产生冲突,难以实现风格和内容的有效融合,并且风格的动态性容易丢失。此外,现有方法通常只支持单一模态的风格控制,缺乏对多种模态(如文本、图像)的支持。
核心思路:本文的核心思路是建立风格和内容之间的双向控制流。通过允许风格信息影响内容生成的同时,也允许内容信息反过来调整风格,从而缓解风格与内容之间的冲突,更好地保留风格的动态性。此外,利用对比学习,将风格控制扩展到多模态,使得可以通过文本、图像等多种模态来控制运动风格。
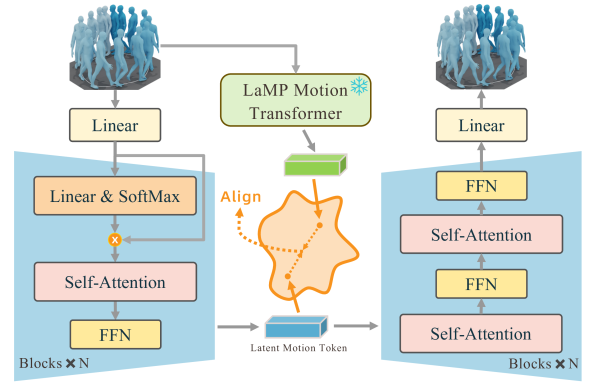
技术框架:整体框架包含内容编码器、风格编码器、双向控制模块和运动生成器。内容编码器负责提取内容提示的特征,风格编码器负责提取目标风格的特征。双向控制模块负责在风格和内容之间建立双向控制流,协调二者之间的关系。运动生成器则根据融合后的特征生成最终的运动序列。
关键创新:最重要的技术创新点在于双向控制流的设计。与现有方法中单向的信息流动不同,本文提出的双向控制流能够更好地协调风格和内容之间的关系,从而生成更符合要求的运动序列。此外,多模态风格控制也是一个重要的创新点,它使得用户可以通过多种模态的信号来控制运动风格。
关键设计:双向控制模块的具体实现方式未知,摘要中没有详细说明。对比学习损失函数的具体形式未知,摘要中没有详细说明。运动生成器的网络结构未知,摘要中没有详细说明。
🖼️ 关键图片


📊 实验亮点
实验结果表明,本文提出的方法在多个数据集上显著优于现有方法。具体性能数据和对比基线未知,摘要中没有提供详细的实验结果。但摘要强调了该方法在风格化运动生成方面的优越性,以及对多模态信号控制的支持。
🎯 应用场景
该研究成果可应用于虚拟角色的动画生成、游戏开发、电影制作等领域。通过多模态风格控制,可以更灵活地生成符合特定风格和需求的运动序列,提高内容创作的效率和质量。未来,该技术有望应用于人机交互、机器人控制等更广泛的领域。
📄 摘要(原文)
Generating motion sequences conforming to a target style while adhering to the given content prompts requires accommodating both the content and style. In existing methods, the information usually only flows from style to content, which may cause conflict between the style and content, harming the integration. Differently, in this work we build a bidirectional control flow between the style and the content, also adjusting the style towards the content, in which case the style-content collision is alleviated and the dynamics of the style is better preserved in the integration. Moreover, we extend the stylized motion generation from one modality, i.e. the style motion, to multiple modalities including texts and images through contrastive learning, leading to flexible style control on the motion generation. Extensive experiments demonstrate that our method significantly outperforms previous methods across different datasets, while also enabling multimodal signals control. The code of our method will be made publicly available.