Enriching Multimodal Sentiment Analysis through Textual Emotional Descriptions of Visual-Audio Content
作者: Sheng Wu, Xiaobao Wang, Longbiao Wang, Dongxiao He, Jianwu Dang
分类: cs.CV, cs.AI, cs.SD, eess.AS
发布日期: 2024-12-12
期刊: AAAI 2025
💡 一句话要点
提出DEVA框架,通过文本情感描述增强视听内容的多模态情感分析。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态情感分析 情感描述生成 视听内容理解 文本引导融合 情感特征增强
📋 核心要点
- 现有方法难以捕捉视听数据中细微的情感差异,尤其在情感极性相似时。
- DEVA框架通过情感描述生成器将视听数据转化为文本情感描述,增强情感特征。
- 实验结果表明,DEVA在多个基准数据集上优于现有方法,并对细微情感变化敏感。
📝 摘要(中文)
多模态情感分析(MSA)旨在融合文本、音频和视觉数据,全面解析人类情感。然而,在视听表达中识别细微的情感差异极具挑战性,尤其当不同片段的情感极性相似时。本文旨在突出音频和视觉模态中与情感相关的属性,以促进视听场景中细微情感变化的融合。为此,我们引入DEVA,一个基于文本情感描述的渐进式融合框架,旨在增强视听内容的情感特征。DEVA采用情感描述生成器(EDG)将原始音频和视觉数据转化为文本情感描述,从而放大其情感特征。然后,将这些描述与源数据集成,以产生更丰富、更增强的特征。此外,DEVA还包含文本引导的渐进式融合模块(TPF),利用不同级别的文本作为核心模态指导,逐步融合视听次要模态,以减轻文本与视听模态之间的差异。在MOSI、MOSEI和CH-SIMS等广泛使用的情感分析基准数据集上的实验结果表明,与最先进的模型相比,DEVA具有显著的增强效果。此外,细粒度的情感实验证实了DEVA对细微情感变化的强大敏感性。
🔬 方法详解
问题定义:多模态情感分析旨在融合文本、音频和视觉信息来理解人类情感。然而,现有方法在处理视听数据时,难以捕捉到细微的情感差异,尤其是在不同片段的情感极性相似的情况下。这主要是因为音频和视觉模态的情感表达方式复杂,且与文本模态存在差异,导致融合效果不佳。
核心思路:DEVA的核心思路是通过文本情感描述来增强视听模态的情感特征。具体来说,它将原始的音频和视觉数据转化为文本形式的情感描述,从而将视听信息的情感表达方式与文本模态对齐,并放大其情感特征。这样做的目的是为了更好地利用文本模态作为指导,促进多模态融合,从而更准确地识别细微的情感变化。
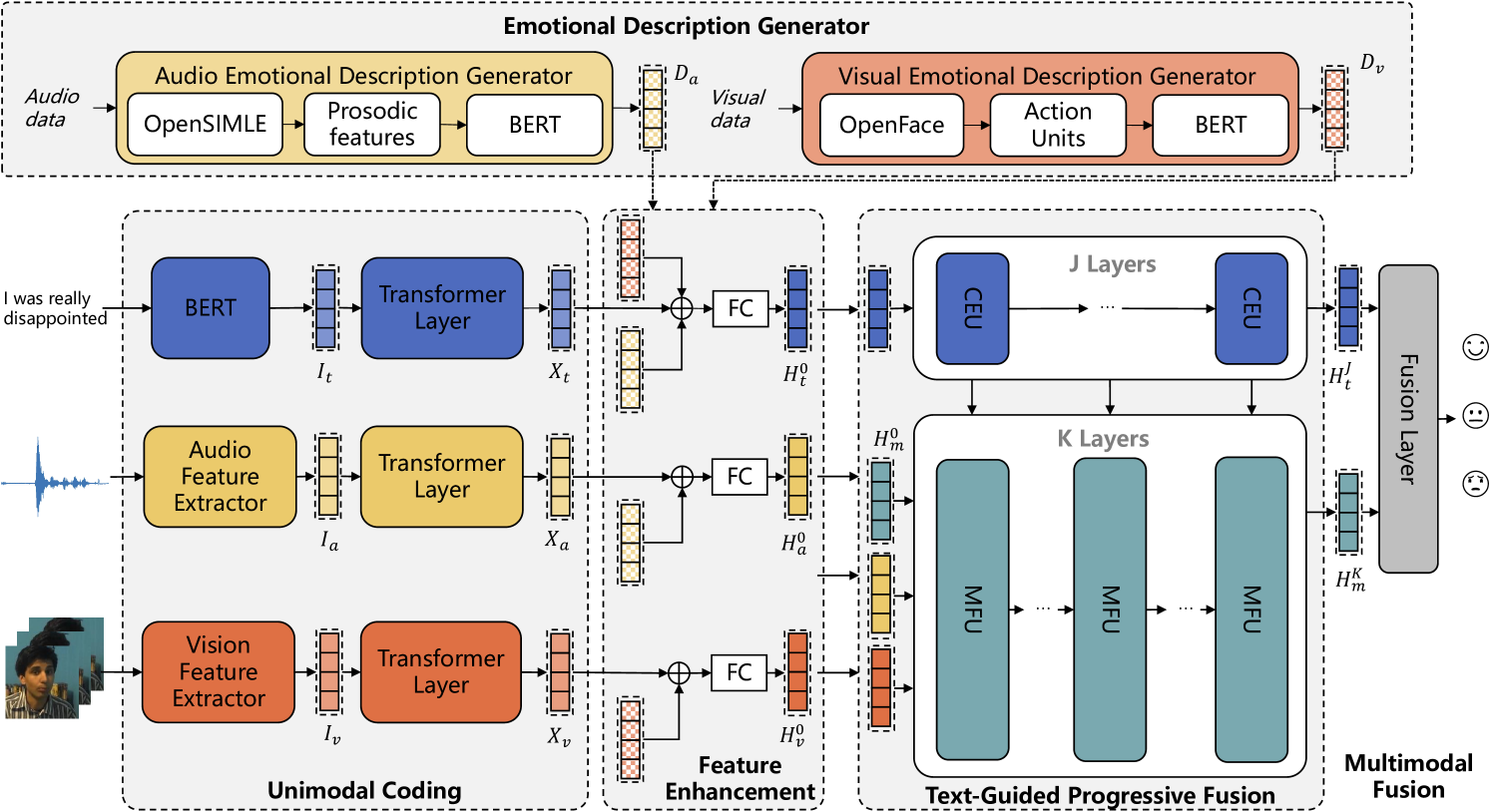
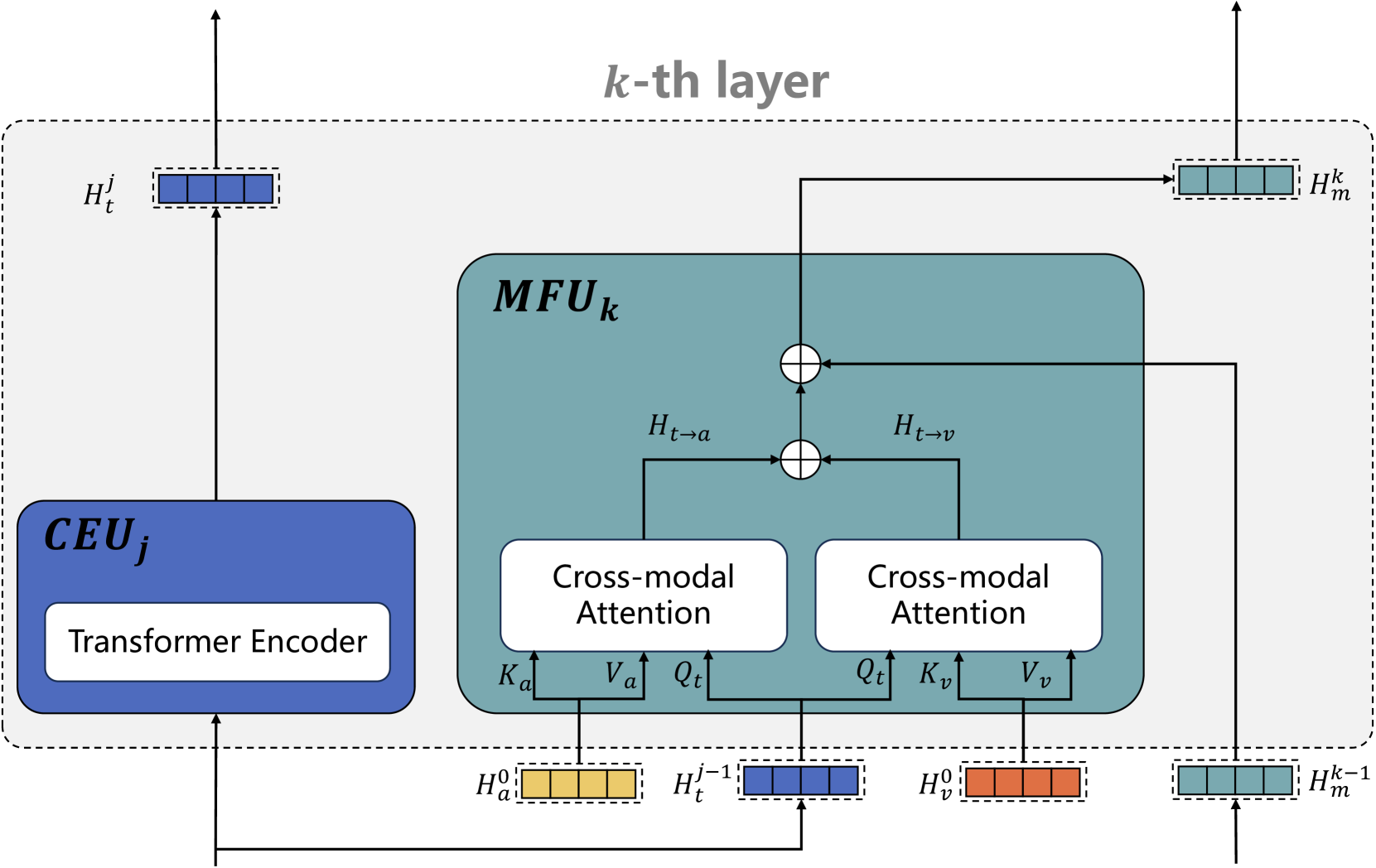
技术框架:DEVA框架主要包含两个模块:情感描述生成器(EDG)和文本引导的渐进式融合模块(TPF)。EDG负责将原始音频和视觉数据转化为文本情感描述。TPF则利用不同级别的文本信息作为指导,逐步融合视听模态,以减轻文本与视听模态之间的差异。整个流程是先通过EDG增强视听模态的情感特征,然后通过TPF进行多模态融合,最终得到情感分析结果。
关键创新:DEVA的关键创新在于引入了情感描述生成器(EDG),将视听数据转化为文本情感描述。这种方法能够有效地增强视听模态的情感特征,并将其与文本模态对齐,从而更好地利用文本模态作为指导,促进多模态融合。与现有方法直接融合原始视听数据不同,DEVA通过文本情感描述作为桥梁,实现了更有效的多模态信息交互。
关键设计:EDG的具体实现细节未知,可能使用了预训练的语言模型或专门设计的神经网络结构。TPF模块可能采用了注意力机制或门控机制,以控制不同模态信息的融合程度。损失函数的设计可能包括情感分类损失、情感回归损失以及模态对齐损失等。具体的参数设置和网络结构细节在论文中可能有所描述,但此处无法得知。
🖼️ 关键图片

📊 实验亮点
DEVA在MOSI、MOSEI和CH-SIMS等情感分析基准数据集上取得了显著的性能提升,超越了现有最先进的模型。细粒度的情感实验也表明,DEVA对细微的情感变化具有强大的敏感性,能够更准确地识别复杂的情感表达。具体的性能提升幅度未知,需要在论文中查找详细的实验数据。
🎯 应用场景
该研究成果可应用于情感识别、智能客服、心理健康评估、电影评论分析等领域。通过更准确地理解人类情感,可以提升人机交互的自然性和有效性,为个性化服务和情感支持提供更可靠的基础。未来,该技术有望在虚拟现实、游戏等领域发挥重要作用,创造更具沉浸感和情感共鸣的体验。
📄 摘要(原文)
Multimodal Sentiment Analysis (MSA) stands as a critical research frontier, seeking to comprehensively unravel human emotions by amalgamating text, audio, and visual data. Yet, discerning subtle emotional nuances within audio and video expressions poses a formidable challenge, particularly when emotional polarities across various segments appear similar. In this paper, our objective is to spotlight emotion-relevant attributes of audio and visual modalities to facilitate multimodal fusion in the context of nuanced emotional shifts in visual-audio scenarios. To this end, we introduce DEVA, a progressive fusion framework founded on textual sentiment descriptions aimed at accentuating emotional features of visual-audio content. DEVA employs an Emotional Description Generator (EDG) to transmute raw audio and visual data into textualized sentiment descriptions, thereby amplifying their emotional characteristics. These descriptions are then integrated with the source data to yield richer, enhanced features. Furthermore, DEVA incorporates the Text-guided Progressive Fusion Module (TPF), leveraging varying levels of text as a core modality guide. This module progressively fuses visual-audio minor modalities to alleviate disparities between text and visual-audio modalities. Experimental results on widely used sentiment analysis benchmark datasets, including MOSI, MOSEI, and CH-SIMS, underscore significant enhancements compared to state-of-the-art models. Moreover, fine-grained emotion experiments corroborate the robust sensitivity of DEVA to subtle emotional variations.