Geo-LLaVA: A Large Multi-Modal Model for Solving Geometry Math Problems with Meta In-Context Learning
作者: Shihao Xu, Yiyang Luo, Wei Shi
分类: cs.CV, cs.AI, cs.CG
发布日期: 2024-12-12
💡 一句话要点
提出Geo-LLaVA,结合元上下文学习解决几何数学难题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 几何问题求解 多模态学习 大型语言模型 上下文学习 立体几何 GeoMath数据集 检索增强
📋 核心要点
- 现有方法在解决几何数学问题时依赖符号识别,缺乏对视觉和空间信息的有效利用。
- Geo-LLaVA通过元训练阶段的检索增强和监督微调,以及推理阶段的上下文学习,提升模型性能。
- 实验表明,Geo-LLaVA在GeoQA和GeoMath数据集上取得了SOTA结果,并初步具备解决立体几何问题的能力。
📝 摘要(中文)
几何数学问题因其涉及视觉元素和空间推理,对大型语言模型(LLMs)提出了重大挑战。现有方法主要依赖于符号字符识别来解决这些问题。考虑到几何问题求解是一个相对新兴的领域,缺乏合适的公开数据集,且几乎没有关于立体几何问题求解的研究,我们收集了一个几何问答数据集GeoMath,该数据集从中国高中教育网站获取几何数据,包含立体几何问题和带有准确推理步骤的答案,以弥补现有平面几何数据集的不足。此外,我们提出了一个名为Geo-LLaVA的大型多模态模型(LMM)框架,该框架在训练阶段结合了检索增强和监督微调(SFT),称为元训练,并在推理过程中采用上下文学习(ICL)来提高性能。我们经过微调并结合ICL的模型在GeoQA数据集和GeoMath数据集的选定问题上分别达到了65.25%和42.36%的state-of-the-art性能,并具有适当的推理步骤。值得注意的是,我们的模型初步具备了解决立体几何问题的能力,并支持生成合理的立体几何图片描述和问题解决步骤。我们的研究为进一步探索LLMs在多模态数学问题求解,特别是在几何数学问题中的应用奠定了基础。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在几何数学问题求解方面的不足,特别是缺乏对视觉信息和空间推理的有效利用。现有方法主要依赖于符号字符识别,难以处理复杂的几何关系。此外,缺乏高质量的几何数据集,尤其是立体几何数据集,限制了相关研究的进展。
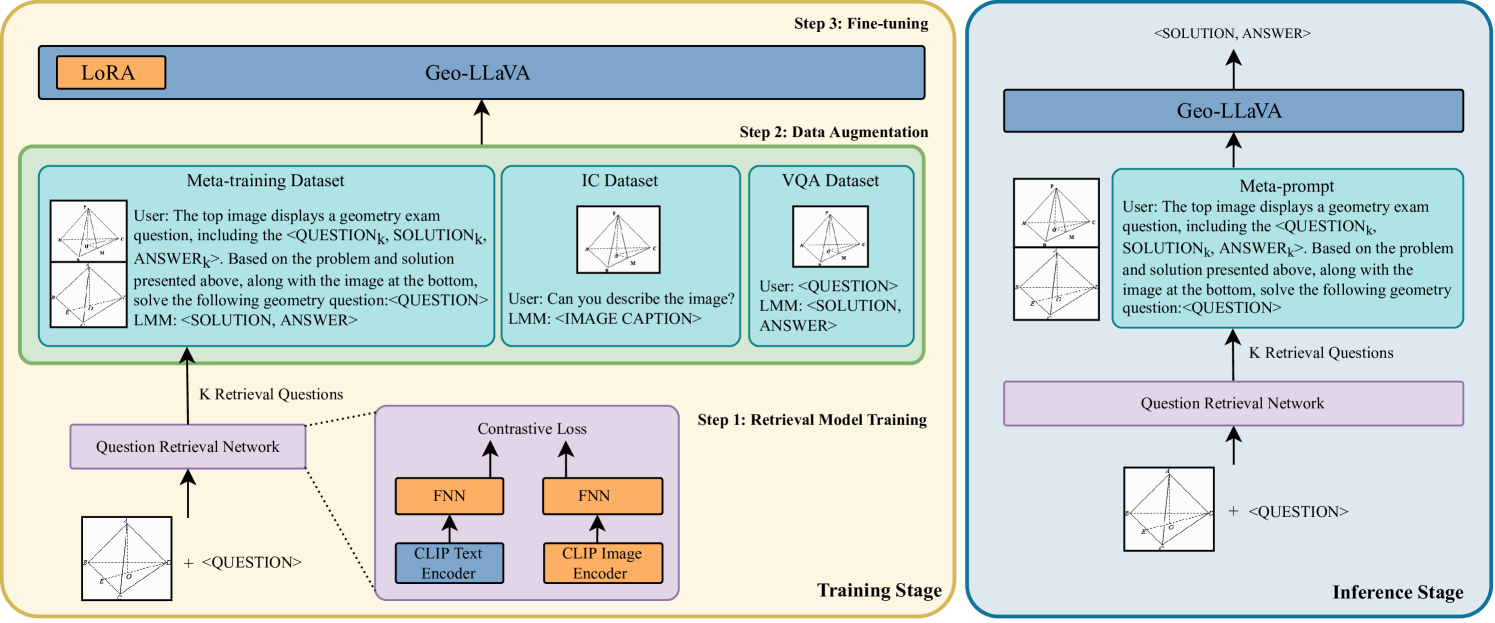
核心思路:论文的核心思路是构建一个大型多模态模型Geo-LLaVA,通过结合检索增强、监督微调和上下文学习,使模型能够更好地理解几何图形和问题描述,并进行有效的推理。通过元训练阶段的学习,模型能够掌握解决几何问题的通用策略,并通过上下文学习,根据具体问题的特点进行调整。
技术框架:Geo-LLaVA的整体框架包括以下几个主要阶段:1) 数据收集与构建:构建包含平面几何和立体几何问题的GeoMath数据集。2) 元训练:使用检索增强和监督微调(SFT)对模型进行训练,使其具备解决几何问题的初步能力。3) 推理:利用上下文学习(ICL),根据具体问题的特点,选择合适的示例进行推理。
关键创新:论文的关键创新点在于:1) 提出了Geo-LLaVA框架,将检索增强、监督微调和上下文学习相结合,有效提升了几何问题求解的性能。2) 构建了包含立体几何问题的GeoMath数据集,弥补了现有数据集的不足。3) 模型初步具备了解决立体几何问题的能力,并支持生成合理的立体几何图片描述和问题解决步骤。与现有方法相比,Geo-LLaVA更加注重对视觉信息和空间推理的利用。
关键设计:Geo-LLaVA的关键设计包括:1) 检索增强:在训练阶段,通过检索与当前问题相关的示例,增强模型的学习效果。2) 监督微调:使用高质量的几何问答数据对模型进行微调,使其具备解决几何问题的能力。3) 上下文学习:在推理阶段,根据具体问题的特点,选择合适的示例作为上下文,引导模型进行推理。具体的参数设置、损失函数和网络结构等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
Geo-LLaVA在GeoQA数据集和GeoMath数据集的选定问题上分别达到了65.25%和42.36%的state-of-the-art性能。相较于现有方法,Geo-LLaVA在几何问题求解方面取得了显著的提升。此外,该模型初步具备了解决立体几何问题的能力,并支持生成合理的立体几何图片描述和问题解决步骤,为未来的研究奠定了基础。
🎯 应用场景
Geo-LLaVA在教育领域具有广泛的应用前景,可以用于智能辅导系统、在线教育平台等,帮助学生更好地理解和解决几何问题。此外,该研究还可以应用于机器人视觉、三维场景理解等领域,提升机器对几何空间的感知和推理能力。未来,Geo-LLaVA有望成为通用数学问题求解模型的基础。
📄 摘要(原文)
Geometry mathematics problems pose significant challenges for large language models (LLMs) because they involve visual elements and spatial reasoning. Current methods primarily rely on symbolic character awareness to address these problems. Considering geometry problem solving is a relatively nascent field with limited suitable datasets and currently almost no work on solid geometry problem solving, we collect a geometry question-answer dataset by sourcing geometric data from Chinese high school education websites, referred to as GeoMath. It contains solid geometry questions and answers with accurate reasoning steps as compensation for existing plane geometry datasets. Additionally, we propose a Large Multi-modal Model (LMM) framework named Geo-LLaVA, which incorporates retrieval augmentation with supervised fine-tuning (SFT) in the training stage, called meta-training, and employs in-context learning (ICL) during inference to improve performance. Our fine-tuned model with ICL attains the state-of-the-art performance of 65.25% and 42.36% on selected questions of the GeoQA dataset and GeoMath dataset respectively with proper inference steps. Notably, our model initially endows the ability to solve solid geometry problems and supports the generation of reasonable solid geometry picture descriptions and problem-solving steps. Our research sets the stage for further exploration of LLMs in multi-modal math problem-solving, particularly in geometry math problems.