Olympus: A Universal Task Router for Computer Vision Tasks
作者: Yuanze Lin, Yunsheng Li, Dongdong Chen, Weijian Xu, Ronald Clark, Philip H. S. Torr
分类: cs.CV, cs.AI, cs.CL
发布日期: 2024-12-12 (更新: 2025-04-01)
备注: Accepted to CVPR 2025, Project webpage: http://yuanze-lin.me/Olympus_page/
💡 一句话要点
Olympus:一种用于计算机视觉任务的通用任务路由框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大模型 计算机视觉 任务路由 指令学习 链式动作
📋 核心要点
- 现有方法难以统一处理多种计算机视觉任务,且训练成本高昂,限制了多模态大模型的应用。
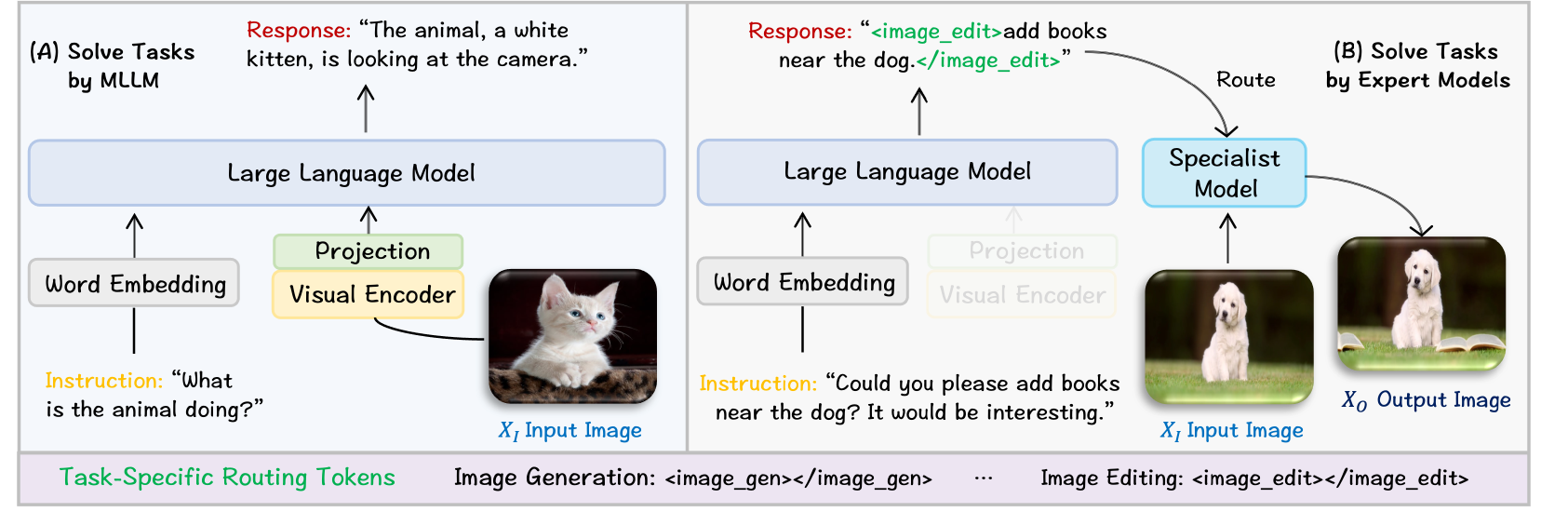
- Olympus的核心思想是利用控制器MLLM,通过指令路由将不同任务分配给专门的模块,实现任务解耦。
- 实验结果表明,Olympus在多个视觉任务上取得了优秀的路由准确率和链式动作精度,验证了其有效性。
📝 摘要(中文)
本文介绍了一种名为Olympus的新方法,它将多模态大型语言模型(MLLM)转换为一个统一的框架,能够处理各种计算机视觉任务。Olympus利用一个控制器MLLM,将图像、视频和3D对象上的20多个专门任务委派给专用模块。这种基于指令的路由通过链式动作实现复杂的工作流程,而无需训练繁重的生成模型。Olympus可以轻松地与现有的MLLM集成,扩展其功能并获得可比的性能。实验结果表明,Olympus在20个任务上的平均路由准确率达到94.75%,在链式动作场景中的精度达到91.82%,展示了其作为通用任务路由器的有效性,可以解决各种计算机视觉任务。
🔬 方法详解
问题定义:现有计算机视觉系统通常针对特定任务设计,缺乏通用性和灵活性。多模态大模型虽然潜力巨大,但直接训练处理所有任务成本高昂,且难以保证每个任务的性能。因此,如何利用现有MLLM,高效地处理各种计算机视觉任务是一个关键问题。
核心思路:Olympus的核心思路是将MLLM作为一个任务路由器,根据指令将输入数据路由到相应的专业模块进行处理。这种解耦的方式避免了直接训练一个庞大的模型来处理所有任务,降低了训练成本,并允许针对每个任务使用最优的模块。
技术框架:Olympus的整体架构包含一个控制器MLLM和多个专业模块。控制器MLLM接收用户指令和输入数据,根据指令判断需要执行的任务,并将数据路由到相应的专业模块。专业模块执行具体的视觉任务,并将结果返回给控制器MLLM,控制器MLLM可以将结果返回给用户,或者将其作为下一步任务的输入,实现链式动作。
关键创新:Olympus的关键创新在于其通用任务路由机制。它将MLLM从一个直接执行任务的模型,转变为一个任务调度器,通过指令路由实现任务解耦和模块化。这种方法允许灵活地添加和替换专业模块,扩展系统的能力,而无需重新训练整个模型。
关键设计:Olympus的关键设计包括:1) 控制器MLLM的选择,需要具备良好的指令理解和推理能力;2) 专业模块的选取,需要覆盖各种常见的计算机视觉任务;3) 路由策略的设计,需要保证路由的准确性和效率;4) 链式动作的实现,需要保证任务之间的顺利衔接。
🖼️ 关键图片


📊 实验亮点
Olympus在20个不同的计算机视觉任务上实现了94.75%的平均路由准确率,证明了其作为通用任务路由器的有效性。在链式动作场景中,Olympus的精度达到了91.82%,表明其能够有效地处理复杂的视觉任务流程。这些结果表明,Olympus能够显著提升MLLM在计算机视觉领域的应用能力。
🎯 应用场景
Olympus具有广泛的应用前景,例如智能安防、自动驾驶、机器人导航、医疗影像分析等领域。它可以作为一个通用的视觉任务处理平台,根据用户需求灵活地组合不同的视觉模块,实现复杂的视觉任务。未来,Olympus可以进一步扩展到更多的模态和任务,成为一个更加强大的通用人工智能系统。
📄 摘要(原文)
We introduce Olympus, a new approach that transforms Multimodal Large Language Models (MLLMs) into a unified framework capable of handling a wide array of computer vision tasks. Utilizing a controller MLLM, Olympus delegates over 20 specialized tasks across images, videos, and 3D objects to dedicated modules. This instruction-based routing enables complex workflows through chained actions without the need for training heavy generative models. Olympus easily integrates with existing MLLMs, expanding their capabilities with comparable performance. Experimental results demonstrate that Olympus achieves an average routing accuracy of 94.75% across 20 tasks and precision of 91.82% in chained action scenarios, showcasing its effectiveness as a universal task router that can solve a diverse range of computer vision tasks. Project page: http://yuanze-lin.me/Olympus_page/