Owl-1: Omni World Model for Consistent Long Video Generation
作者: Yuanhui Huang, Wenzhao Zheng, Yuan Gao, Xin Tao, Pengfei Wan, Di Zhang, Jie Zhou, Jiwen Lu
分类: cs.CV, cs.AI, cs.LG
发布日期: 2024-12-12
备注: Code is available at: https://github.com/huang-yh/Owl
🔗 代码/项目: GITHUB
💡 一句话要点
提出Owl-1:用于生成一致长视频的Omni World Model
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 长视频生成 世界模型 视频一致性 潜在空间建模 视频预测
📋 核心要点
- 现有长视频生成方法依赖迭代调用短视频生成模型,仅使用最后一帧作为条件,导致长期一致性不足。
- Owl-1通过在潜在空间中建模世界的长期演化动态,为视频生成提供连贯和全面的条件,提升一致性。
- 实验表明,Owl-1在VBench-I2V和VBench-Long上取得了与SOTA方法相当的性能,验证了其有效性。
📝 摘要(中文)
视频生成模型(VGMs)最近受到了广泛关注,并有望成为通用大型视觉模型的候选者。虽然它们每次只能生成短视频,但现有方法通过迭代调用VGMs来实现长视频生成,使用最后一帧的输出作为下一轮生成的条件。然而,最后一帧只包含关于场景的短期精细信息,导致长时域上的不一致。为了解决这个问题,我们提出了一个Omni World Model (Owl-1),为一致的长视频生成产生长期连贯和全面的条件。由于视频是对底层演化世界的观察,我们建议在潜在空间中对长期发展进行建模,并使用VGMs将其拍摄成视频。具体来说,我们用一个潜在状态变量来表示世界,该变量可以被解码成显式的视频观察。这些观察结果为预测时间动态提供了基础,而时间动态反过来又更新了状态变量。演化动态和持久状态之间的相互作用增强了长视频的多样性和一致性。大量的实验表明,Owl-1在VBench-I2V和VBench-Long上取得了与SOTA方法相当的性能,验证了其生成高质量视频观察的能力。
🔬 方法详解
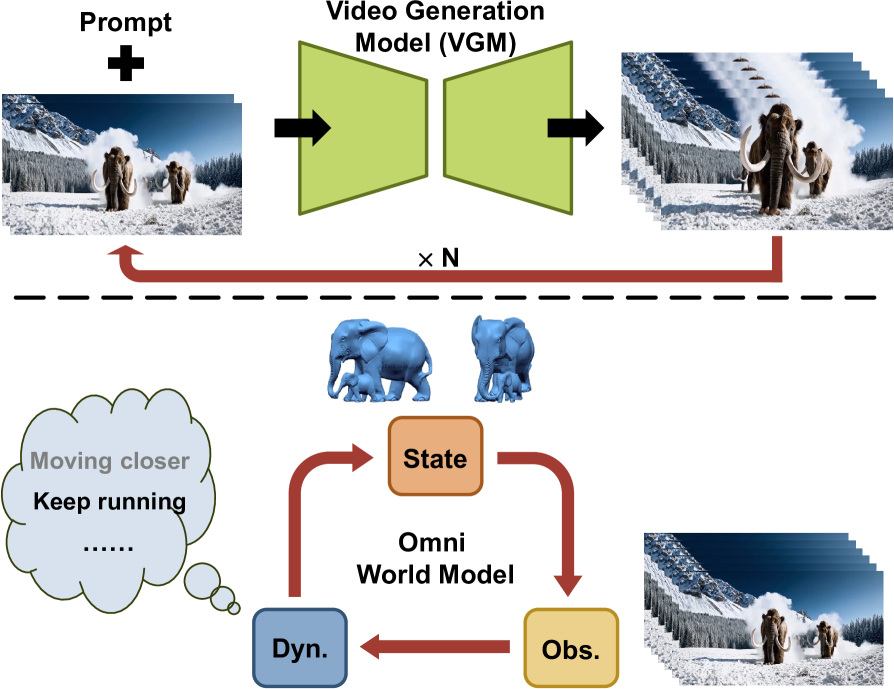
问题定义:现有长视频生成方法主要通过迭代调用短视频生成模型实现,每次生成依赖于前一帧的信息。这种方式的痛点在于,仅依赖最后一帧作为条件,无法捕捉到视频中的长期依赖关系和全局信息,导致生成的长视频在内容、风格和场景上出现不一致性,影响观看体验。
核心思路:Owl-1的核心思路是将视频生成视为对底层世界演化的观察。它不是直接生成视频帧,而是在一个潜在空间中建模世界的长期动态变化。通过维护一个潜在状态变量来表示世界的状态,并利用视频生成模型将这个潜在状态“拍摄”成视频。这种方式能够更好地捕捉视频中的长期依赖关系,从而生成更一致的长视频。
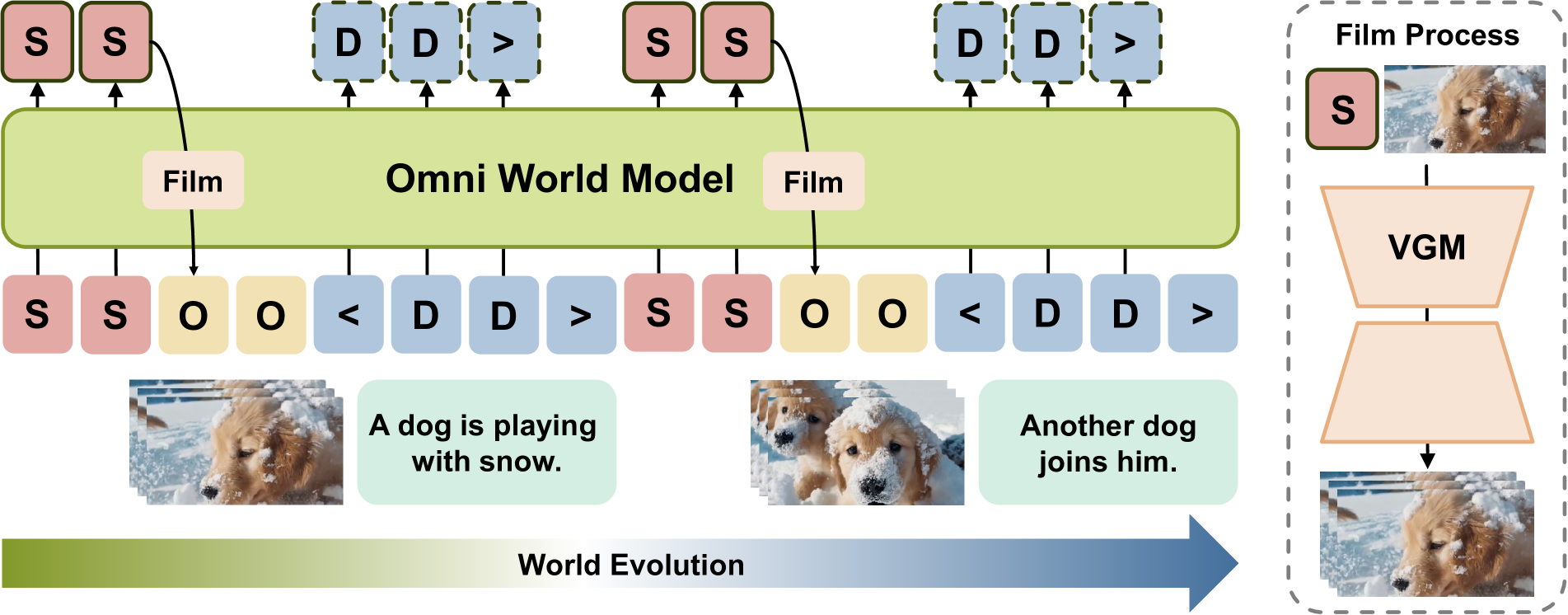
技术框架:Owl-1的整体框架包含以下几个主要模块:1) 潜在状态编码器:将初始帧编码为潜在状态向量。2) 世界动态模型:基于当前潜在状态预测未来的状态变化。3) 视频解码器:将潜在状态解码为视频帧。4) 状态更新机制:根据生成的视频帧和预测的状态变化,更新潜在状态。整个流程迭代进行,不断更新潜在状态并生成新的视频帧,从而实现长视频的生成。
关键创新:Owl-1最重要的创新在于引入了“世界模型”的概念,将视频生成问题转化为对底层世界动态的建模。与现有方法直接生成视频帧不同,Owl-1首先在潜在空间中学习世界的演化规律,然后将这些规律转化为视频。这种方式能够更好地捕捉视频中的长期依赖关系,从而生成更一致的长视频。
关键设计:Owl-1的关键设计包括:1) 使用Transformer网络作为世界动态模型,学习潜在状态之间的转移关系。2) 设计了一种状态更新机制,将生成的视频帧信息反馈到潜在状态中,从而实现闭环控制。3) 损失函数包括视频重建损失和状态预测损失,用于约束潜在状态的学习和视频生成过程。具体参数设置和网络结构细节未在摘要中详细说明,需要参考论文全文。
🖼️ 关键图片
📊 实验亮点
Owl-1在VBench-I2V和VBench-Long两个长视频生成benchmark上进行了评估,取得了与SOTA方法相当的性能。这表明Owl-1在生成高质量、一致性长视频方面具有竞争力。具体的性能数据和对比基线需要在论文中查找。
🎯 应用场景
Owl-1具有广泛的应用前景,例如电影制作、游戏开发、虚拟现实等领域。它可以用于生成高质量的长视频内容,例如电影片段、游戏场景、虚拟现实体验等。此外,Owl-1还可以用于视频编辑和增强,例如修复老旧视频、生成缺失帧等。未来,Owl-1有望成为一种通用的视频生成工具,为各行各业带来便利。
📄 摘要(原文)
Video generation models (VGMs) have received extensive attention recently and serve as promising candidates for general-purpose large vision models. While they can only generate short videos each time, existing methods achieve long video generation by iteratively calling the VGMs, using the last-frame output as the condition for the next-round generation. However, the last frame only contains short-term fine-grained information about the scene, resulting in inconsistency in the long horizon. To address this, we propose an Omni World modeL (Owl-1) to produce long-term coherent and comprehensive conditions for consistent long video generation. As videos are observations of the underlying evolving world, we propose to model the long-term developments in a latent space and use VGMs to film them into videos. Specifically, we represent the world with a latent state variable which can be decoded into explicit video observations. These observations serve as a basis for anticipating temporal dynamics which in turn update the state variable. The interaction between evolving dynamics and persistent state enhances the diversity and consistency of the long videos. Extensive experiments show that Owl-1 achieves comparable performance with SOTA methods on VBench-I2V and VBench-Long, validating its ability to generate high-quality video observations. Code: https://github.com/huang-yh/Owl.