Elevating Visual Perception in Multimodal LLMs with Visual Embedding Distillation
作者: Jitesh Jain, Zhengyuan Yang, Humphrey Shi, Jianfeng Gao, Jianwei Yang
分类: cs.CV
发布日期: 2024-12-12 (更新: 2025-10-17)
备注: Project Page: https://praeclarumjj3.github.io/visper_lm/
💡 一句话要点
VisPer-LM:通过视觉嵌入蒸馏提升多模态LLM的视觉感知能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 视觉嵌入 知识蒸馏 视觉感知 语言模型
📋 核心要点
- 现有MLLM倾向于语言理解,忽略了视觉数据中丰富的感知信号,这对于具身AI和机器人领域的空间推理至关重要。
- VisPer-LM通过视觉嵌入蒸馏,将专家视觉编码器的知识注入到LLM的隐藏层表示中,优化视觉感知能力。
- 实验证明,VisPer-LM在多个视觉任务上取得了显著的性能提升,尤其是在深度估计任务上。
📝 摘要(中文)
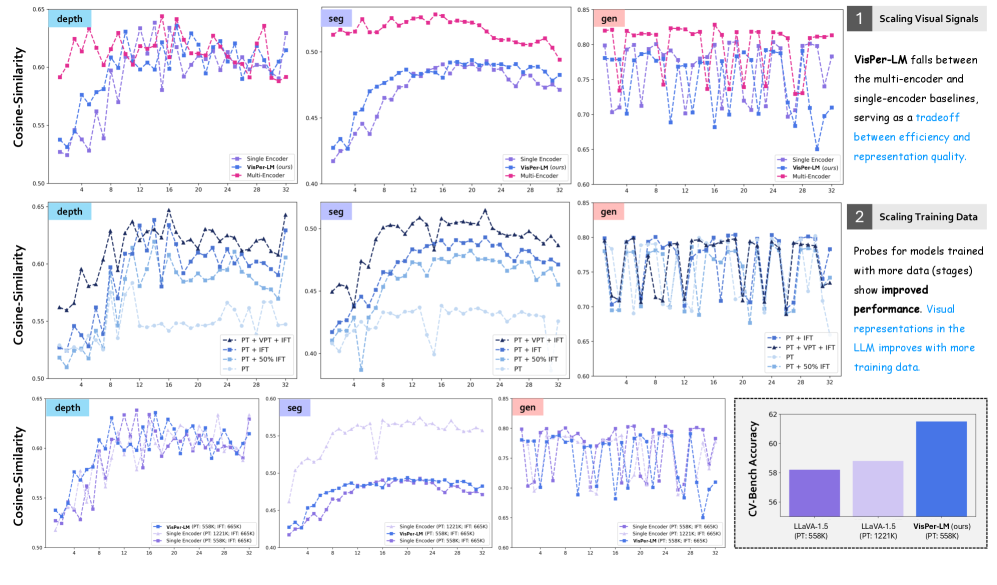
本文提出VisPer-LM,一种将专家视觉编码器的视觉感知知识注入到多模态LLM(MLLM)的LLM隐藏层表示中的方法。研究发现,仅通过自然语言监督训练的MLLM中,视觉表示的质量与下游性能呈正相关。因此,在MLLM的预训练阶段,VisPer-LM将目标设定为预测视觉嵌入和下一个文本token的双重优化。实验结果表明,嵌入优化显著提升了视觉表示的质量。VisPer-LM优于单编码器和多编码器基线,在多个基准测试中平均提升高达2.5%,在CV-Bench的Depth任务中提升高达8.7%。
🔬 方法详解
问题定义:现有的多模态LLM在训练时,通常直接将视觉编码器的特征输入到LLM中,并使用自然语言进行监督训练。这种方法容易导致模型过度关注语言理解,而忽略了视觉信息中重要的空间信息和感知细节,尤其是在需要进行空间推理的具身智能和机器人任务中表现不佳。
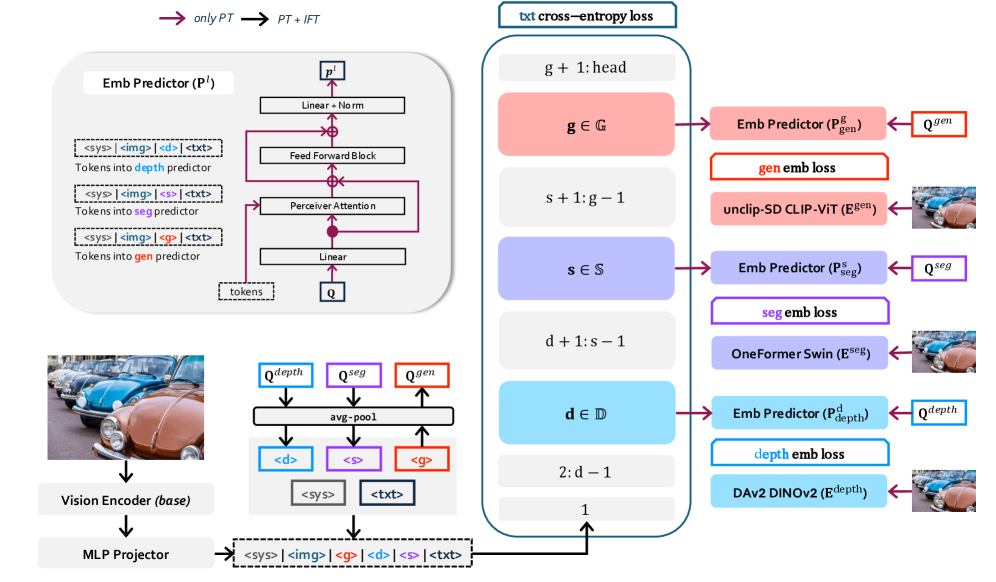
核心思路:VisPer-LM的核心思路是通过视觉嵌入蒸馏,将预训练好的、具有强大视觉感知能力的专家视觉编码器的知识迁移到LLM中。具体来说,就是让LLM学习预测专家视觉编码器提取的视觉嵌入,从而提升LLM自身的视觉表示能力。这样做的目的是让LLM能够更好地理解和利用视觉信息,从而提升其在各种视觉任务上的性能。
技术框架:VisPer-LM的整体框架包括以下几个主要步骤:1) 使用预训练的专家视觉编码器提取视觉特征;2) 将视觉特征输入到LLM中;3) LLM在进行下一个token预测的同时,也预测专家视觉编码器提取的视觉嵌入;4) 使用预测的视觉嵌入和真实的视觉嵌入之间的差异作为损失函数,对LLM进行优化。
关键创新:VisPer-LM的关键创新在于它提出了一种新的训练目标,即同时优化下一个token预测和视觉嵌入预测。这种双重优化策略能够有效地提升LLM的视觉感知能力,使其能够更好地理解和利用视觉信息。此外,该方法不需要显式地将视觉特征输入到LLM中,而是通过蒸馏的方式将视觉知识注入到LLM的隐藏层表示中,从而避免了信息冗余和噪声干扰。
关键设计:VisPer-LM的关键设计包括:1) 选择合适的专家视觉编码器,例如CLIP等;2) 设计合适的损失函数,例如MSE损失或对比损失,用于衡量预测的视觉嵌入和真实的视觉嵌入之间的差异;3) 调整视觉嵌入预测的权重,以平衡语言理解和视觉感知之间的关系。具体参数设置和网络结构的选择可能需要根据具体的任务和数据集进行调整。
🖼️ 关键图片

📊 实验亮点
VisPer-LM在多个基准测试中取得了显著的性能提升。例如,在CV-Bench的Depth任务中,VisPer-LM的性能提升了8.7%。在其他视觉任务中,VisPer-LM的平均性能提升也达到了2.5%。这些结果表明,VisPer-LM能够有效地提升MLLM的视觉感知能力,使其在各种视觉任务上表现更出色。实验结果证明了VisPer-LM相对于单编码器和多编码器基线的优越性。
🎯 应用场景
VisPer-LM具有广泛的应用前景,尤其是在需要进行视觉理解和空间推理的领域,例如具身智能、机器人导航、自动驾驶、图像编辑和视频分析等。通过提升MLLM的视觉感知能力,可以使其更好地理解周围环境,从而实现更智能、更高效的任务执行。未来,该方法有望应用于各种实际场景,例如智能家居、工业自动化和医疗辅助等。
📄 摘要(原文)
In recent times, the standard practice for developing MLLMs is to feed features from vision encoder(s) into the LLM and train with natural language supervision. This approach often causes models to lean towards language comprehension and undermine the rich visual perception signals present in the data, which are critical for tasks involving spatial reasoning in the domain of embodied AI and robotics. Is it possible to optimize both at the same time? In this work, we propose VisPer-LM, the first approach that infuses visual perception knowledge from expert vision encoders into the LLM's (of an MLLM) hidden representations. We start by investigating MLLMs trained solely with natural language supervision and identify a positive correlation between the quality of visual representations within these models and their downstream performance. Given this insight, we formulate the objective during the pretraining stage in MLLMs as a coupled optimization of predictive visual embedding and next (text) token prediction. Moreover, through extensive probing, we observe improved visual representation quality due to embedding optimization, underscoring the effectiveness of our probing setup. We demonstrate that our VisPer-LM outperforms the single and multi-encoder baselines, proving our approach's superiority over explicitly feeding the corresponding features to the LLM. In particular, VisPer-LM boosts performance by an average margin of up to 2.5% on various benchmarks, with a notable improvement of 8.7% on the Depth task in CV-Bench.