FreeSplatter: Pose-free Gaussian Splatting for Sparse-view 3D Reconstruction
作者: Jiale Xu, Shenghua Gao, Ying Shan
分类: cs.CV
发布日期: 2024-12-12 (更新: 2025-09-01)
备注: Project page: https://bluestyle97.github.io/projects/freesplatter/
💡 一句话要点
FreeSplatter:无需相机位姿的稀疏视图高斯溅射三维重建
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 三维重建 高斯溅射 稀疏视图 无位姿 Transformer 相机位姿估计 计算机视觉 深度学习
📋 核心要点
- 现有稀疏视图重建模型依赖精确的相机位姿,而从稀疏图像中获取这些参数极具挑战。
- FreeSplatter通过Transformer架构学习多视图图像特征,直接解码为3D高斯基元,同时估计相机参数。
- 实验表明,FreeSplatter在重建质量和位姿估计精度上优于现有方法,简化了3D内容创作流程。
📝 摘要(中文)
本文提出了一种名为FreeSplatter的可扩展前馈框架,用于从未经校准的稀疏视图图像中生成高质量的3D高斯模型,并在数秒内估计相机参数。该方法采用精简的Transformer架构,其中自注意力模块促进多视图图像tokens之间的信息交换,并将它们解码为统一参考系中像素对齐的3D高斯基元。这种表示能够实现高保真度的3D建模,并使用现成的求解器高效地估计相机参数。我们开发了两种专门的变体——用于以对象为中心和场景级别的重建——并在全面的数据集上进行训练。值得注意的是,FreeSplatter在具有挑战性的基准测试中,超越了几种依赖位姿的大型重建模型(LRM),并在位姿估计精度方面与最先进的无位姿重建方法MASt3R相当甚至更好。除了技术基准之外,FreeSplatter还简化了文本/图像到3D内容创建流程,消除了相机位姿管理的复杂性,同时提供了卓越的视觉保真度。
🔬 方法详解
问题定义:现有稀疏视图三维重建方法通常需要精确的相机位姿作为输入,而从稀疏视图图像中准确估计相机位姿本身就是一个难题。这限制了这些方法在实际应用中的可用性,尤其是在相机位姿信息缺失或不准确的情况下。现有无位姿方法重建质量有待提高。
核心思路:FreeSplatter的核心思路是直接从稀疏视图图像中学习3D高斯模型的参数,同时估计相机位姿。通过Transformer架构,实现多视图图像特征的有效融合,并将这些特征解码为像素对齐的3D高斯基元。这种端到端的学习方式避免了对精确相机位姿的依赖,并允许模型在训练过程中自动学习相机参数。
技术框架:FreeSplatter的整体框架包括一个Transformer编码器和一个3D高斯解码器。Transformer编码器接收多视图图像作为输入,并使用自注意力机制提取图像特征。然后,3D高斯解码器将这些特征解码为3D高斯模型的参数,包括位置、协方差和颜色等。同时,模型还输出相机参数的估计值。整个框架采用端到端的方式进行训练。
关键创新:FreeSplatter的关键创新在于其无位姿的重建方法。与传统的依赖相机位姿的方法不同,FreeSplatter可以直接从稀疏视图图像中学习3D高斯模型的参数,并同时估计相机位姿。这使得该方法在相机位姿信息缺失或不准确的情况下仍然能够进行三维重建。此外,使用高斯溅射进行显示,可以实现高质量的渲染。
关键设计:FreeSplatter使用了Transformer架构进行特征提取,并设计了一个专门的3D高斯解码器。在训练过程中,使用了多种损失函数,包括重建损失、位姿损失和正则化损失。重建损失用于衡量重建的3D高斯模型与输入图像之间的差异,位姿损失用于约束估计的相机位姿的准确性,正则化损失用于防止过拟合。针对不同场景,模型分为object-centric和scene-level两种变体,并使用不同的数据集进行训练。
🖼️ 关键图片

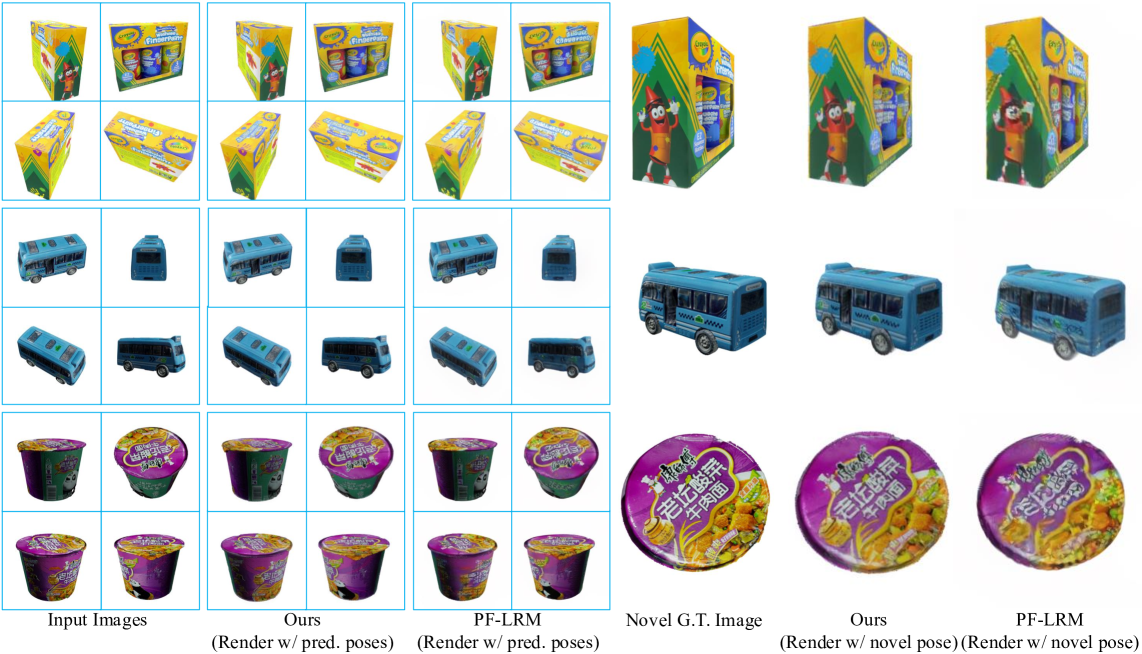

📊 实验亮点
FreeSplatter在多个基准测试中取得了显著的成果。在重建质量方面,FreeSplatter超越了几种依赖位姿的大型重建模型(LRM)。在位姿估计精度方面,FreeSplatter与最先进的无位姿重建方法MASt3R相当甚至更好。这些结果表明,FreeSplatter是一种有效且高效的稀疏视图三维重建方法。
🎯 应用场景
FreeSplatter在三维内容创作、虚拟现实、增强现实、机器人导航等领域具有广泛的应用前景。它可以用于快速生成高质量的三维模型,无需复杂的相机标定过程。此外,FreeSplatter还可以用于从图像中估计相机位姿,为机器人导航和场景理解提供支持。该研究简化了3D内容生成流程,降低了技术门槛,有望推动相关产业的发展。
📄 摘要(原文)
Sparse-view reconstruction models typically require precise camera poses, yet obtaining these parameters from sparse-view images remains challenging. We introduce FreeSplatter, a scalable feed-forward framework that generates high-quality 3D Gaussians from uncalibrated sparse-view images while estimating camera parameters within seconds. Our approach employs a streamlined transformer architecture where self-attention blocks facilitate information exchange among multi-view image tokens, decoding them into pixel-aligned 3D Gaussian primitives within a unified reference frame. This representation enables both high-fidelity 3D modeling and efficient camera parameter estimation using off-the-shelf solvers. We develop two specialized variants--for object-centric and scene-level reconstruction--trained on comprehensive datasets. Remarkably, FreeSplatter outperforms several pose-dependent Large Reconstruction Models (LRMs) by a notable margin while achieving comparable or even better pose estimation accuracy compared to state-of-the-art pose-free reconstruction approach MASt3R in challenging benchmarks. Beyond technical benchmarks, FreeSplatter streamlines text/image-to-3D content creation pipelines, eliminating the complexity of camera pose management while delivering exceptional visual fidelity.