Multimodal Music Generation with Explicit Bridges and Retrieval Augmentation
作者: Baisen Wang, Le Zhuo, Zhaokai Wang, Chenxi Bao, Wu Chengjing, Xuecheng Nie, Jiao Dai, Jizhong Han, Yue Liao, Si Liu
分类: cs.CV, cs.MM, cs.SD, eess.AS
发布日期: 2024-12-12
🔗 代码/项目: GITHUB
💡 一句话要点
提出VMB框架,利用显式桥接和检索增强实现高质量多模态音乐生成
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态音乐生成 跨模态对齐 显式桥接 检索增强 文本描述 音乐检索 可控音乐生成
📋 核心要点
- 现有方法在多模态音乐生成中面临数据稀缺、跨模态对齐弱和可控性有限等挑战。
- VMB利用文本和音乐的显式桥接,通过多模态描述和双轨检索实现跨模态对齐和用户控制。
- 实验表明,VMB在音乐质量、模态对齐和定制对齐方面显著优于现有方法,提升了生成效果。
📝 摘要(中文)
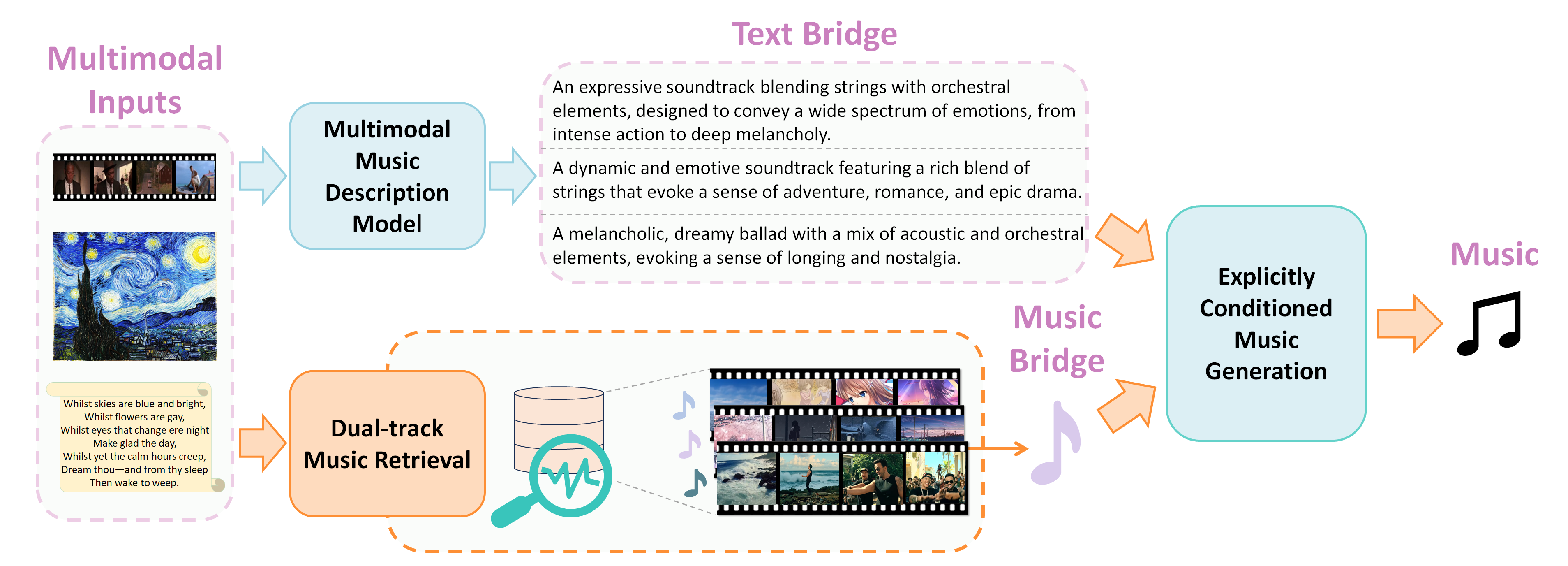
本文提出了一种名为Visuals Music Bridge (VMB) 的多模态音乐生成方法,旨在解决数据稀缺、跨模态对齐弱和可控性有限等问题。VMB利用文本和音乐的显式桥接进行多模态对齐。具体而言,多模态音乐描述模型将视觉输入转换为详细的文本描述,形成文本桥;双轨音乐检索模块结合了广泛和有针对性的检索策略,形成音乐桥,并实现用户控制。最后,设计了一个显式条件音乐生成框架,基于这两个桥生成音乐。在视频到音乐、图像到音乐、文本到音乐以及可控音乐生成任务上的实验结果表明,VMB显著提高了音乐质量、模态对齐和定制对齐,为可解释和富有表现力的多模态音乐生成树立了新标准,并在各种多媒体领域具有应用前景。
🔬 方法详解
问题定义:现有的多模态音乐生成方法依赖于通用的嵌入空间进行多模态融合,但在数据稀缺的情况下,跨模态对齐效果不佳,且难以实现用户对生成音乐的精细控制。因此,需要解决如何有效利用有限数据进行跨模态对齐,并提升生成音乐的可控性问题。
核心思路:VMB的核心思路是利用文本和音乐作为显式的桥梁,将视觉信息转化为文本描述,并结合音乐检索,从而实现更强的跨模态对齐和用户控制。通过文本桥连接视觉输入和音乐生成,利用音乐桥提供音乐风格和内容的参考。
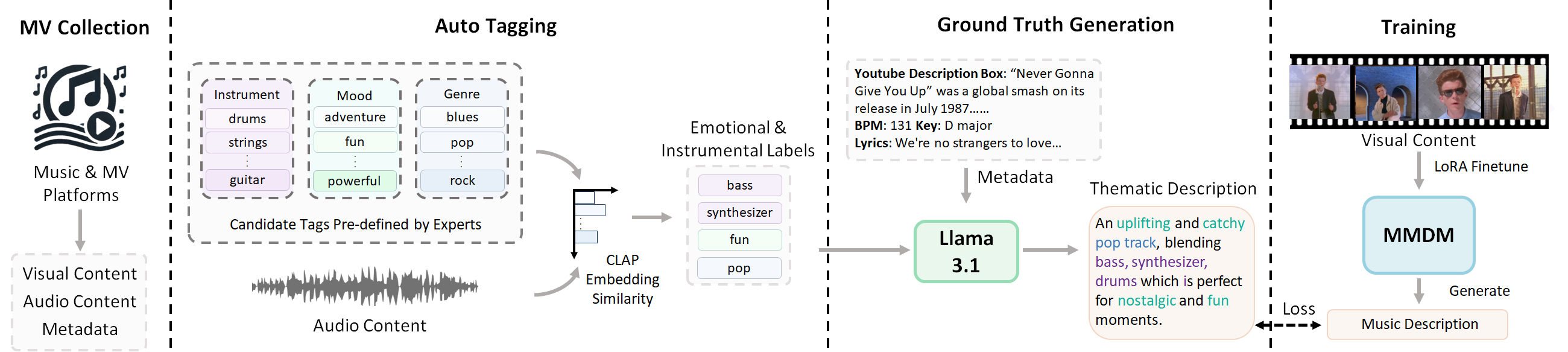
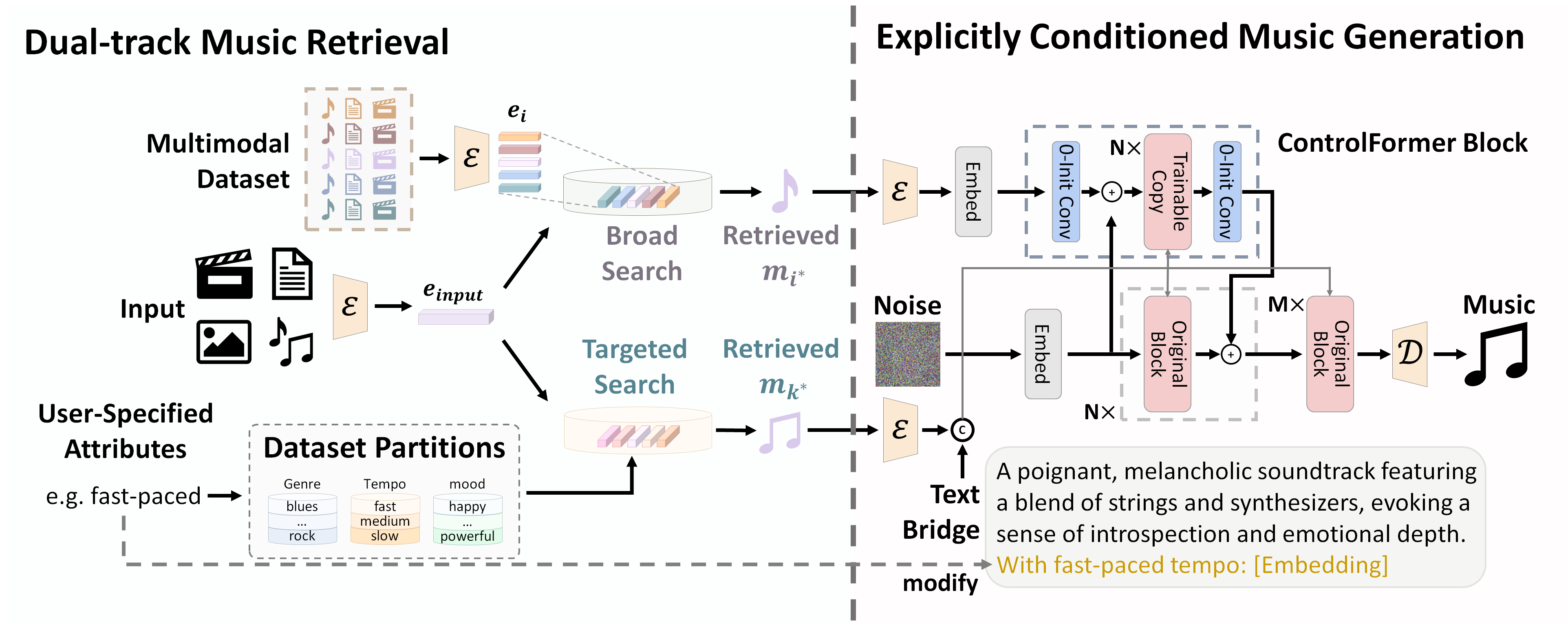
技术框架:VMB框架包含三个主要模块:1) 多模态音乐描述模型:将视觉输入(图像或视频)转换为详细的文本描述。2) 双轨音乐检索模块:结合广泛检索和目标检索策略,检索相关的音乐片段。3) 显式条件音乐生成框架:基于文本描述和检索到的音乐片段,生成最终的音乐。
关键创新:VMB的关键创新在于引入了显式的文本和音乐桥接,而不是依赖于隐式的嵌入空间。这种显式桥接的方式使得模型更容易学习跨模态之间的关系,并且能够更好地利用检索到的音乐信息。双轨检索策略也是一个创新点,它结合了全局和局部的信息,提高了检索的准确性。
关键设计:多模态音乐描述模型可以使用预训练的图像/视频描述模型,并进行微调。双轨音乐检索模块可以采用不同的相似度度量方法,例如余弦相似度或基于Transformer的相似度模型。显式条件音乐生成框架可以使用Transformer或RNN等序列生成模型,并结合注意力机制来融合文本描述和检索到的音乐信息。损失函数可以包括生成损失、跨模态对齐损失和检索损失等。
🖼️ 关键图片
📊 实验亮点
实验结果表明,VMB在视频到音乐、图像到音乐、文本到音乐以及可控音乐生成任务上均取得了显著的性能提升。相较于现有方法,VMB在音乐质量、模态对齐和定制对齐方面均有明显优势。具体性能数据未知,但摘要强调了VMB显著增强了这些指标。
🎯 应用场景
VMB可应用于多种多媒体领域,例如视频配乐、图像配乐、文本到音乐生成等。该技术可以为视频创作者、游戏开发者和音乐爱好者提供更便捷、更智能的音乐生成工具,提升内容创作的效率和质量。未来,VMB有望应用于个性化音乐推荐、音乐教育等领域。
📄 摘要(原文)
Multimodal music generation aims to produce music from diverse input modalities, including text, videos, and images. Existing methods use a common embedding space for multimodal fusion. Despite their effectiveness in other modalities, their application in multimodal music generation faces challenges of data scarcity, weak cross-modal alignment, and limited controllability. This paper addresses these issues by using explicit bridges of text and music for multimodal alignment. We introduce a novel method named Visuals Music Bridge (VMB). Specifically, a Multimodal Music Description Model converts visual inputs into detailed textual descriptions to provide the text bridge; a Dual-track Music Retrieval module that combines broad and targeted retrieval strategies to provide the music bridge and enable user control. Finally, we design an Explicitly Conditioned Music Generation framework to generate music based on the two bridges. We conduct experiments on video-to-music, image-to-music, text-to-music, and controllable music generation tasks, along with experiments on controllability. The results demonstrate that VMB significantly enhances music quality, modality, and customization alignment compared to previous methods. VMB sets a new standard for interpretable and expressive multimodal music generation with applications in various multimedia fields. Demos and code are available at https://github.com/wbs2788/VMB.