All You Need in Knowledge Distillation Is a Tailored Coordinate System
作者: Junjie Zhou, Ke Zhu, Jianxin Wu
分类: cs.CV, cs.AI
发布日期: 2024-12-12 (更新: 2025-02-12)
备注: Accepted by AAAI 2025
💡 一句话要点
提出定制坐标系蒸馏方法,解决知识蒸馏对特定任务教师模型的依赖问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 知识蒸馏 自监督学习 模型压缩 少样本学习 坐标系变换
📋 核心要点
- 现有知识蒸馏方法依赖于特定任务的大型教师模型,缺乏灵活性和效率。
- 该论文提出定制坐标系(TCS)方法,利用SSL预训练模型作为教师,通过坐标系捕获暗知识。
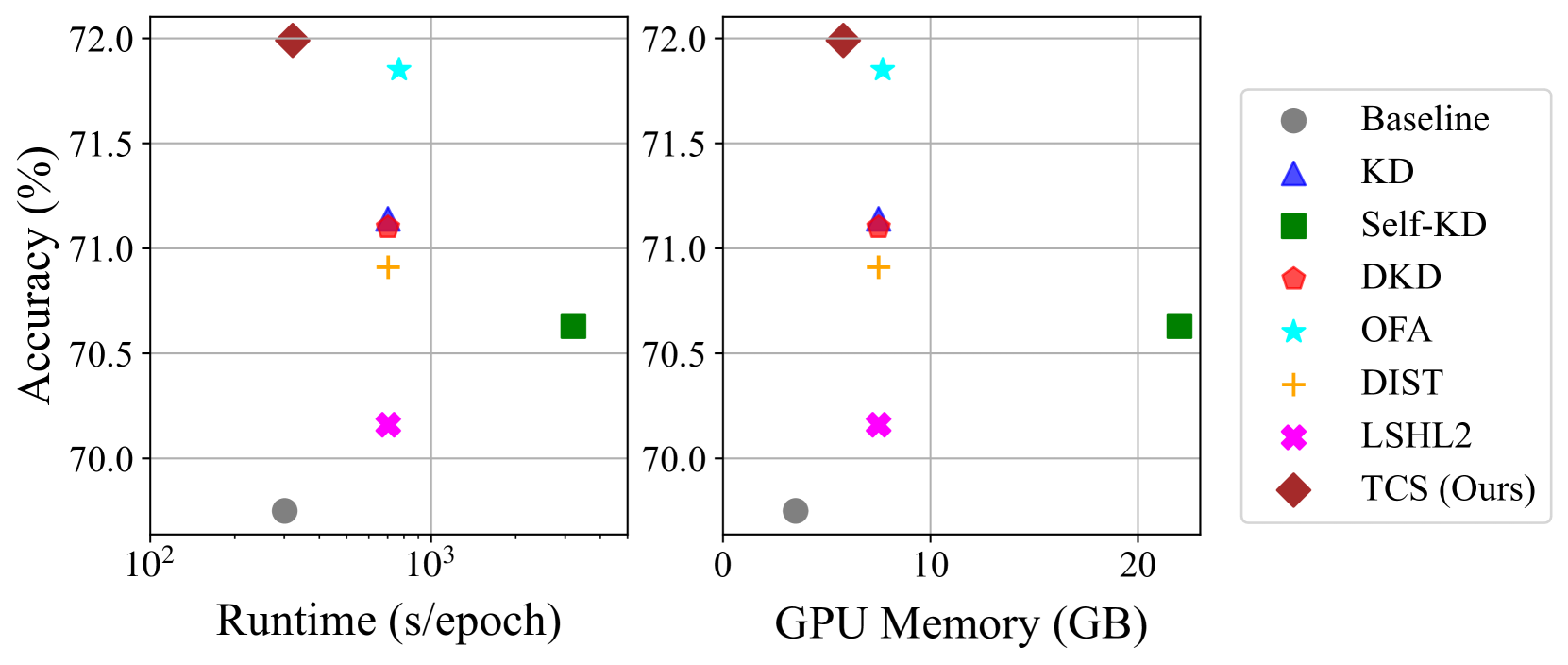
- 实验表明,TCS方法在精度上优于现有方法,并显著降低了训练时间和GPU内存成本。
📝 摘要(中文)
知识蒸馏(KD)对于将大型教师网络的暗知识迁移到小型学生网络至关重要,这样学生网络可以比教师网络更有效率,同时保持相当的准确率。然而,现有的KD方法依赖于专门为目标任务训练的大型教师模型,这既不灵活又效率低下。本文提出,一个经过SSL预训练的模型可以有效地充当教师,并且其暗知识可以被特征所在的坐标系或线性子空间捕获。我们只需要教师网络的一次前向传递,然后为学生网络定制坐标系(TCS)。我们的TCS方法是无教师的,适用于不同的架构,适用于KD和实用的少样本学习,并允许具有大容量差距的跨架构蒸馏。实验表明,TCS比最先进的KD方法实现了显著更高的准确率,同时只需要大约一半的训练时间和GPU内存成本。
🔬 方法详解
问题定义:现有的知识蒸馏方法通常需要一个专门为目标任务训练的大型教师模型。这种方法存在两个主要问题:一是训练大型教师模型的成本很高;二是教师模型必须与学生模型具有相似的架构,限制了知识蒸馏的灵活性。因此,如何利用预训练模型进行知识蒸馏,并克服架构差异,是一个重要的研究问题。
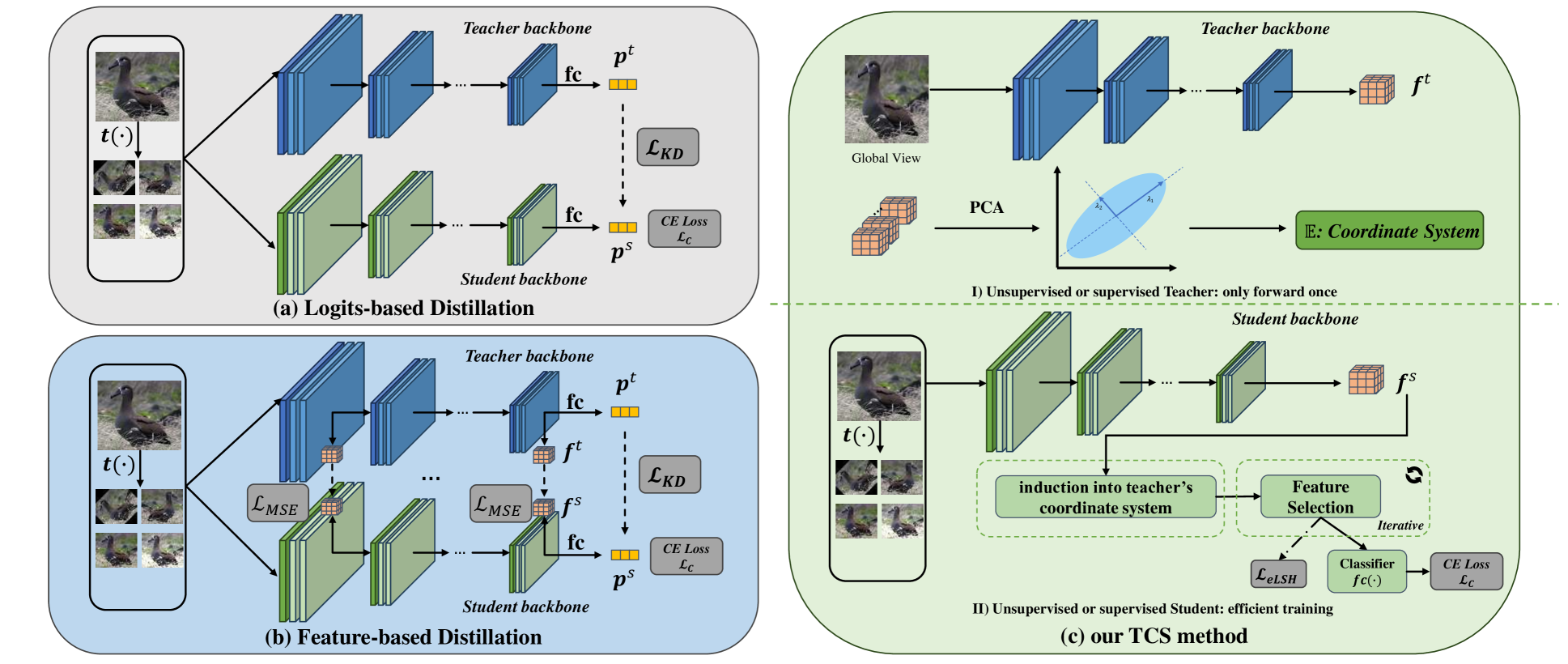
核心思路:该论文的核心思路是利用自监督学习(SSL)预训练模型作为教师,并认为预训练模型的暗知识蕴含在其特征所处的坐标系或线性子空间中。通过为学生网络定制坐标系,使其能够学习到教师网络的暗知识,从而实现知识蒸馏。这种方法避免了对特定任务教师模型的依赖,并允许跨架构的知识迁移。
技术框架:TCS方法的整体流程如下:1) 使用SSL预训练模型提取输入数据的特征;2) 基于教师模型的特征,为学生网络构建定制坐标系;3) 使用定制坐标系对学生网络的特征进行变换,使其与教师网络的特征对齐;4) 使用蒸馏损失函数训练学生网络,使其学习教师网络的暗知识。该框架主要包含特征提取、坐标系构建和知识蒸馏三个阶段。
关键创新:该论文的关键创新在于提出了定制坐标系(TCS)的概念,并将其应用于知识蒸馏。与传统的知识蒸馏方法相比,TCS方法不需要专门训练的教师模型,而是利用预训练模型作为知识源。此外,TCS方法允许跨架构的知识迁移,克服了传统方法的局限性。
关键设计:TCS方法的关键设计包括:1) 坐标系的构建方式:论文中使用了线性子空间作为坐标系,并通过主成分分析(PCA)等方法进行构建。2) 特征对齐方式:论文中使用了线性变换对学生网络的特征进行对齐,使其与教师网络的特征具有相似的分布。3) 蒸馏损失函数:论文中使用了多种蒸馏损失函数,例如KL散度、L2损失等,以促进学生网络学习教师网络的暗知识。
🖼️ 关键图片
📊 实验亮点
实验结果表明,TCS方法在多个数据集上取得了显著的性能提升。例如,在ImageNet数据集上,TCS方法比传统的知识蒸馏方法提高了多个百分点,并且只需要一半的训练时间和GPU内存成本。此外,TCS方法在跨架构蒸馏方面也表现出色,能够将大型模型的知识有效地迁移到小型模型。
🎯 应用场景
该研究成果可广泛应用于模型压缩、边缘计算、移动设备等资源受限的场景。通过知识蒸馏,可以将大型模型的知识迁移到小型模型,从而在保证性能的同时,降低计算成本和存储空间。此外,该方法还可以应用于少样本学习,提高模型在数据稀缺情况下的泛化能力。未来,该方法有望促进人工智能技术在各个领域的应用。
📄 摘要(原文)
Knowledge Distillation (KD) is essential in transferring dark knowledge from a large teacher to a small student network, such that the student can be much more efficient than the teacher but with comparable accuracy. Existing KD methods, however, rely on a large teacher trained specifically for the target task, which is both very inflexible and inefficient. In this paper, we argue that a SSL-pretrained model can effectively act as the teacher and its dark knowledge can be captured by the coordinate system or linear subspace where the features lie in. We then need only one forward pass of the teacher, and then tailor the coordinate system (TCS) for the student network. Our TCS method is teacher-free and applies to diverse architectures, works well for KD and practical few-shot learning, and allows cross-architecture distillation with large capacity gap. Experiments show that TCS achieves significantly higher accuracy than state-of-the-art KD methods, while only requiring roughly half of their training time and GPU memory costs.