Towards a Multimodal Large Language Model with Pixel-Level Insight for Biomedicine
作者: Xiaoshuang Huang, Lingdong Shen, Jia Liu, Fangxin Shang, Hongxiang Li, Haifeng Huang, Yehui Yang
分类: cs.CV, cs.AI
发布日期: 2024-12-12 (更新: 2025-10-08)
备注: Accepted by AAAI2025
🔗 代码/项目: GITHUB
💡 一句话要点
MedPLIB:面向生物医学,具备像素级理解的多模态大语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 生物医学 像素级理解 混合专家模型 视觉问答 医学影像分析 零样本学习
📋 核心要点
- 现有生物医学多模态大语言模型主要关注图像级理解,交互方式局限于文本命令,限制了其能力边界和使用灵活性。
- MedPLIB通过引入像素级理解能力,支持视觉问答、像素级提示和定位,并采用混合专家多阶段训练策略,提升模型性能。
- 实验结果表明,MedPLIB在多个医学视觉语言任务中达到SOTA,并在像素定位任务的零样本评估中显著优于其他模型。
📝 摘要(中文)
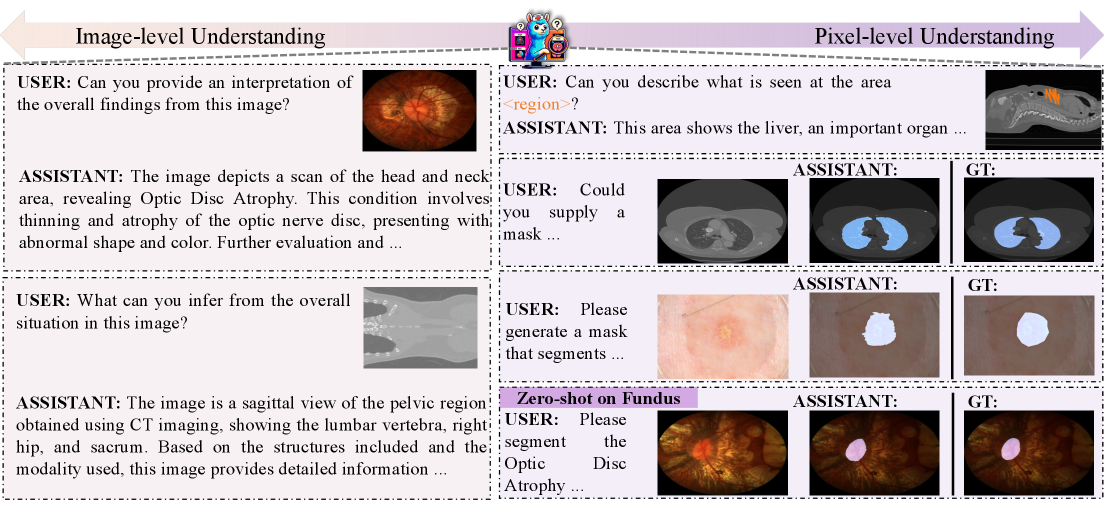
本文提出了一种名为MedPLIB的端到端多模态大语言模型,专为生物医学领域设计,具备像素级理解能力。该模型支持视觉问答(VQA)、任意像素级提示(点、边界框和自由形状)以及像素级定位。论文提出了一种新颖的混合专家(MoE)多阶段训练策略,将MoE分为视觉-语言专家模型和像素定位专家模型的独立训练阶段,然后使用MoE进行微调。这种策略有效地协调了多任务学习,同时保持了推理时的计算成本与单个专家模型相当。为了促进生物医学MLLM的研究,论文引入了医学复杂视觉问答数据集(MeCoVQA),该数据集包含8种模态,用于复杂的医学图像问答和图像区域理解。实验结果表明,MedPLIB在多个医学视觉语言任务中取得了最先进的结果。更重要的是,在像素定位任务的零样本评估中,MedPLIB在mDice指标上分别领先最佳小型和大型模型19.7和15.6。
🔬 方法详解
问题定义:现有生物医学多模态大语言模型主要侧重于图像级别的理解,缺乏对图像细节的像素级理解能力,限制了其在复杂医学图像分析任务中的应用。此外,现有的模型交互方式单一,主要依赖文本指令,无法充分利用视觉信息进行交互。
核心思路:MedPLIB的核心思路是构建一个具备像素级理解能力的生物医学多模态大语言模型,通过支持像素级提示和定位,增强模型对医学图像细节的感知能力。同时,采用混合专家(MoE)多阶段训练策略,有效协调多任务学习,提升模型性能。
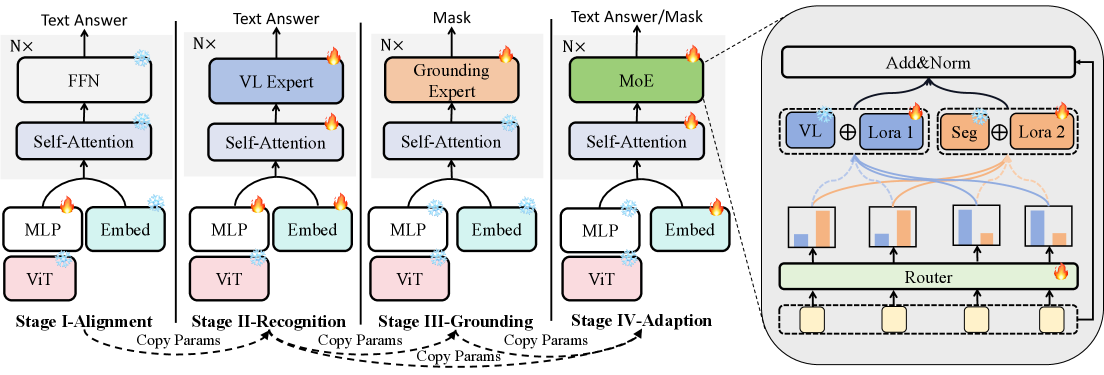
技术框架:MedPLIB的整体框架包含视觉编码器、语言模型和像素级理解模块。视觉编码器负责提取医学图像的视觉特征,语言模型负责处理文本信息并生成答案,像素级理解模块则负责处理像素级提示和定位任务。模型采用MoE结构,包含视觉-语言专家模型和像素定位专家模型,通过多阶段训练策略进行优化。
关键创新:MedPLIB的关键创新在于其像素级理解能力和MoE多阶段训练策略。像素级理解能力使得模型能够处理更精细的医学图像分析任务,例如病灶分割和定位。MoE多阶段训练策略则有效地协调了多任务学习,避免了模型性能下降的问题,同时保持了推理效率。
关键设计:MoE多阶段训练策略分为三个阶段:首先,独立训练视觉-语言专家模型,使其具备基本的视觉问答能力;然后,独立训练像素定位专家模型,使其具备像素级理解能力;最后,使用MoE结构对两个专家模型进行微调,使其能够协同工作。论文还提出了Medical Complex Vision Question Answering Dataset (MeCoVQA),包含8种模态,用于训练和评估模型。
🖼️ 关键图片

📊 实验亮点
MedPLIB在多个医学视觉语言任务中取得了SOTA结果。在像素定位任务的零样本评估中,MedPLIB在mDice指标上分别领先最佳小型和大型模型19.7和15.6。这些结果表明,MedPLIB在像素级理解能力方面具有显著优势,能够有效处理复杂的医学图像分析任务。
🎯 应用场景
MedPLIB在生物医学领域具有广泛的应用前景,例如辅助医生进行疾病诊断、病灶定位和治疗方案制定。该模型可以应用于医学影像分析、病理切片分析、基因组学数据分析等多个领域,有望提高医疗效率和诊断准确性,并为个性化医疗提供支持。
📄 摘要(原文)
In recent years, Multimodal Large Language Models (MLLM) have achieved notable advancements, demonstrating the feasibility of developing an intelligent biomedical assistant. However, current biomedical MLLMs predominantly focus on image-level understanding and restrict interactions to textual commands, thus limiting their capability boundaries and the flexibility of usage. In this paper, we introduce a novel end-to-end multimodal large language model for the biomedical domain, named MedPLIB, which possesses pixel-level understanding. Excitingly, it supports visual question answering (VQA), arbitrary pixel-level prompts (points, bounding boxes, and free-form shapes), and pixel-level grounding. We propose a novel Mixture-of-Experts (MoE) multi-stage training strategy, which divides MoE into separate training phases for a visual-language expert model and a pixel-grounding expert model, followed by fine-tuning using MoE. This strategy effectively coordinates multitask learning while maintaining the computational cost at inference equivalent to that of a single expert model. To advance the research of biomedical MLLMs, we introduce the Medical Complex Vision Question Answering Dataset (MeCoVQA), which comprises an array of 8 modalities for complex medical imaging question answering and image region understanding. Experimental results indicate that MedPLIB has achieved state-of-the-art outcomes across multiple medical visual language tasks. More importantly, in zero-shot evaluations for the pixel grounding task, MedPLIB leads the best small and large models by margins of 19.7 and 15.6 respectively on the mDice metric. The codes, data, and model checkpoints will be made publicly available at https://github.com/ShawnHuang497/MedPLIB.