VLMs meet UDA: Boosting Transferability of Open Vocabulary Segmentation with Unsupervised Domain Adaptation
作者: Roberto Alcover-Couso, Marcos Escudero-Viñolo, Juan C. SanMiguel, Jesus Bescos
分类: cs.CV, cs.AI
发布日期: 2024-12-12
💡 一句话要点
提出UDA-FROVSS框架,结合VLM与UDA提升开放词汇语义分割的跨域迁移能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 开放词汇语义分割 无监督领域自适应 视觉-语言模型 跨域迁移学习 细粒度分割
📋 核心要点
- 现有分割模型受限于训练类别,VLM虽能扩展词汇,但缺乏细粒度区分能力,合成数据方法则受数据集限制。
- 论文提出UDA-FROVSS框架,结合VLM的开放词汇能力和UDA的跨域适应性,无需共享类别即可实现有效迁移。
- 通过多尺度上下文、提示增强和分层微调提升VLM的细粒度分割能力,并利用蒸馏和跨域混合采样增强UDA的稳定性与泛化性。
📝 摘要(中文)
分割模型通常受限于训练期间定义的类别。为了解决这个问题,研究人员探索了两种独立的方法:调整视觉-语言模型(VLM)和利用合成数据。然而,VLM通常难以处理细粒度,无法区分细微的概念,而基于合成数据的方法仍然受到可用数据集范围的限制。本文提出通过将视觉-语言推理与无监督领域自适应(UDA)的关键策略相结合,来提高跨不同领域的分割精度。首先,我们通过多尺度上下文数据、具有提示增强的鲁棒文本嵌入以及我们提出的基础保留开放词汇语义分割(FROVSS)框架中的分层微调,来提高VLM的细粒度分割能力。接下来,我们将这些增强功能整合到UDA框架中,通过使用蒸馏来稳定训练,并通过跨域混合采样来提高适应性而不损害泛化能力。由此产生的UDA-FROVSS框架是第一个无需共享类别即可有效跨域自适应的UDA方法。
🔬 方法详解
问题定义:现有的语义分割模型通常在训练数据集的类别上表现良好,但在新的、未见过的领域或类别上泛化能力较差。开放词汇语义分割旨在解决这个问题,但现有的基于视觉-语言模型(VLM)的方法在细粒度分割方面存在困难,难以区分相似的概念。此外,无监督领域自适应(UDA)方法通常需要源域和目标域之间存在共享类别,限制了其应用范围。
核心思路:论文的核心思路是将VLM的开放词汇能力与UDA的跨域适应能力相结合,提出一个无需共享类别的UDA框架。通过改进VLM的细粒度分割能力,并利用蒸馏和跨域混合采样等技术,实现模型在目标域上的有效泛化。这样既能利用VLM的灵活性,又能克服其在细粒度分割方面的不足,同时避免了UDA对共享类别的依赖。
技术框架:UDA-FROVSS框架包含两个主要阶段:首先是FROVSS(Foundational-Retaining Open Vocabulary Semantic Segmentation)框架,用于提升VLM的细粒度分割能力。FROVSS框架通过多尺度上下文数据、提示增强和分层微调来增强VLM的特征表达能力。然后,将FROVSS框架集成到UDA框架中,利用蒸馏来稳定训练,并使用跨域混合采样来提高模型的适应性。整个流程包括:1) 使用多尺度上下文信息增强图像特征;2) 使用提示增强技术生成更鲁棒的文本嵌入;3) 使用分层微调策略优化VLM;4) 使用蒸馏损失函数稳定训练过程;5) 使用跨域混合采样策略提高模型的泛化能力。
关键创新:该论文的关键创新在于提出了一个无需共享类别的UDA框架,能够有效地将VLM的开放词汇能力迁移到新的领域。此外,FROVSS框架通过多尺度上下文、提示增强和分层微调等技术,显著提升了VLM在细粒度分割方面的性能。跨域混合采样策略也是一个重要的创新点,它能够有效地提高模型的泛化能力,避免过拟合。
关键设计:在FROVSS框架中,多尺度上下文信息通过不同尺度的卷积操作提取,并进行融合。提示增强技术通过生成多个不同的提示文本,来增强文本嵌入的鲁棒性。分层微调策略根据VLM的不同层级,采用不同的学习率进行微调。在UDA框架中,蒸馏损失函数用于约束学生模型的输出与教师模型的输出一致。跨域混合采样策略通过将源域和目标域的样本混合在一起进行训练,来提高模型的泛化能力。具体的损失函数包括分割损失、蒸馏损失和对抗损失(如果使用对抗训练)。
🖼️ 关键图片
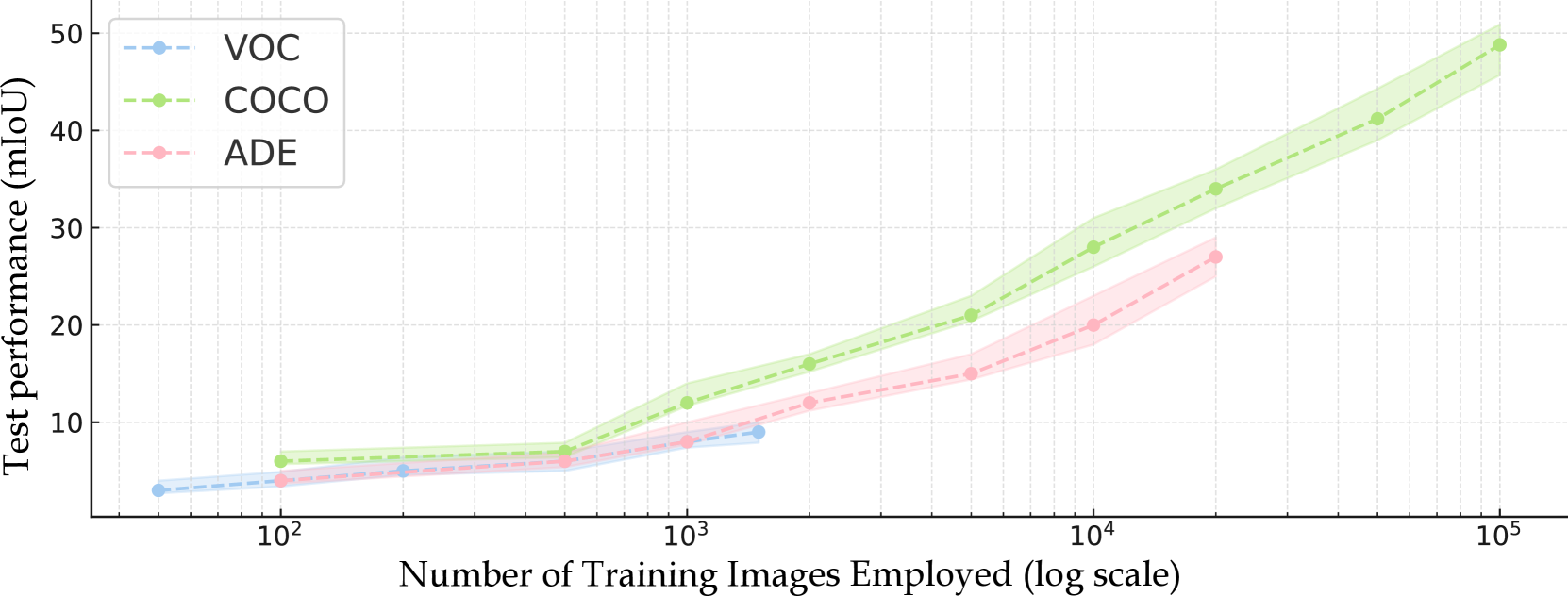
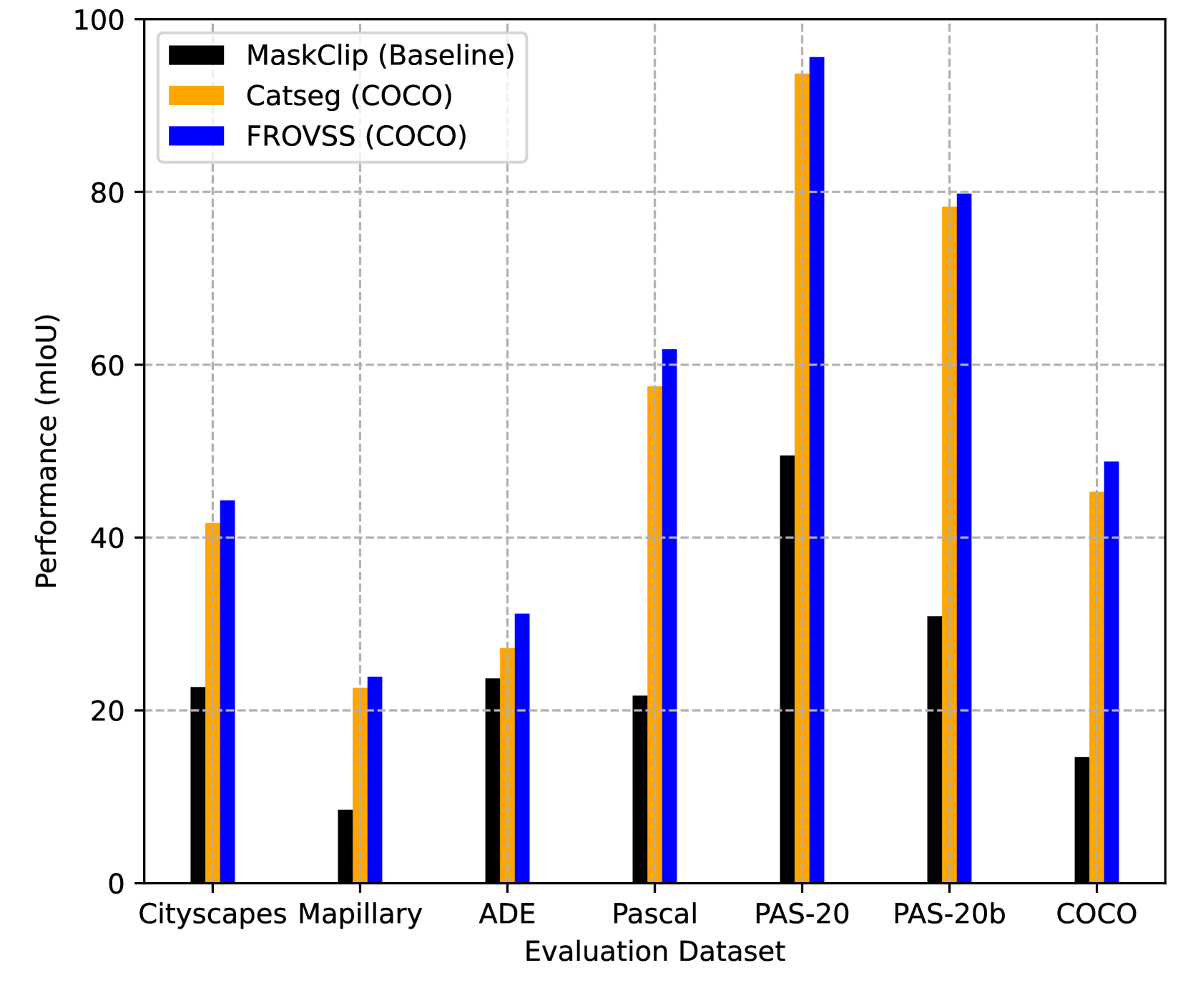
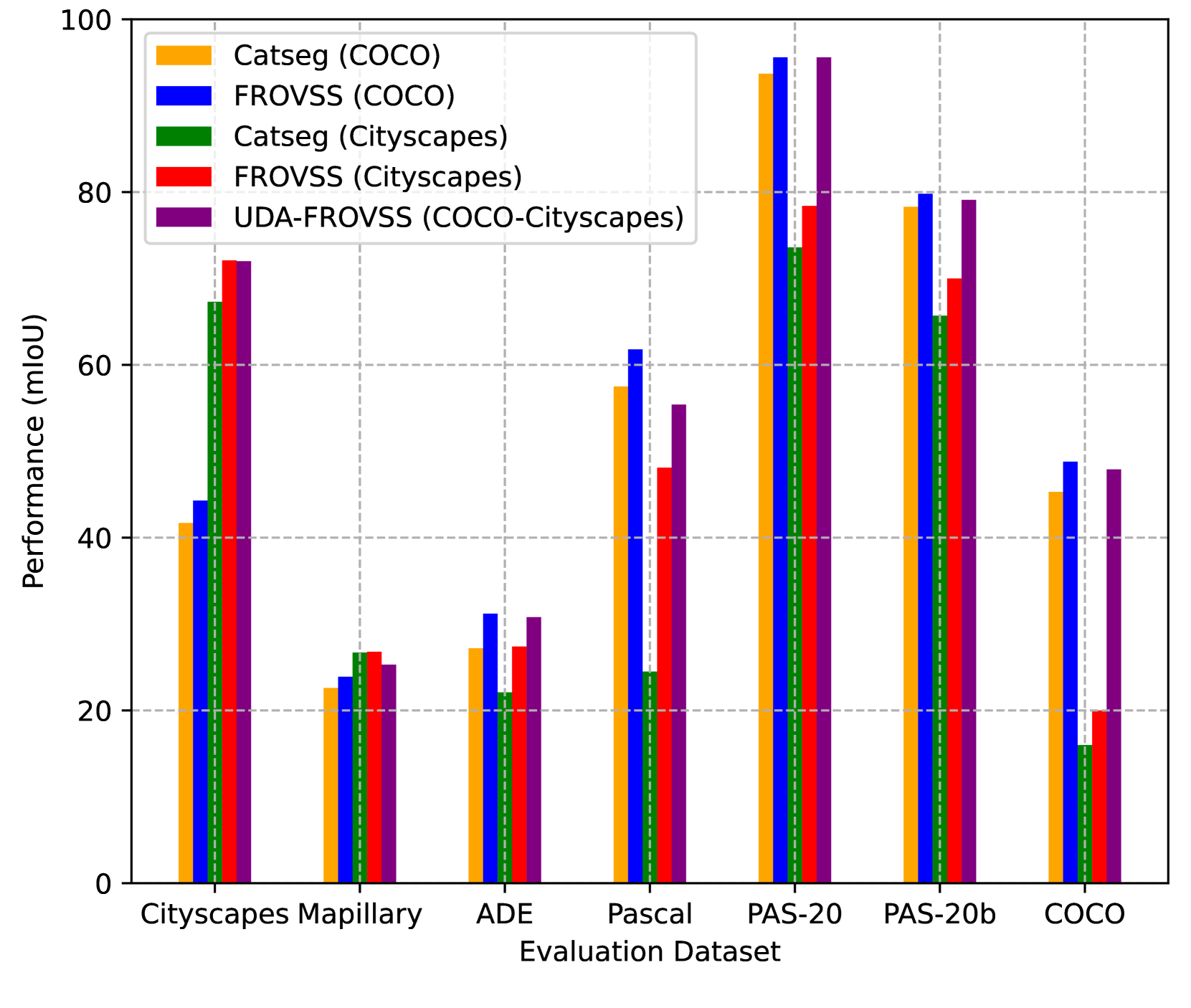
📊 实验亮点
论文提出的UDA-FROVSS框架在多个跨域分割任务上取得了显著的性能提升。实验结果表明,该框架能够有效地将VLM的开放词汇能力迁移到新的领域,并且在细粒度分割方面表现出色。与现有的UDA方法相比,UDA-FROVSS框架无需共享类别,具有更强的通用性和适用性。具体的性能提升数据需要在论文中查找。
🎯 应用场景
该研究成果可广泛应用于自动驾驶、遥感图像分析、医疗图像诊断等领域。例如,在自动驾驶中,可以识别未在训练数据中出现的新的交通标志或道路障碍物。在遥感图像分析中,可以对不同地区的土地覆盖类型进行精细的分类。在医疗图像诊断中,可以辅助医生识别罕见疾病的病灶。该研究具有重要的实际应用价值和广阔的未来发展前景。
📄 摘要(原文)
Segmentation models are typically constrained by the categories defined during training. To address this, researchers have explored two independent approaches: adapting Vision-Language Models (VLMs) and leveraging synthetic data. However, VLMs often struggle with granularity, failing to disentangle fine-grained concepts, while synthetic data-based methods remain limited by the scope of available datasets. This paper proposes enhancing segmentation accuracy across diverse domains by integrating Vision-Language reasoning with key strategies for Unsupervised Domain Adaptation (UDA). First, we improve the fine-grained segmentation capabilities of VLMs through multi-scale contextual data, robust text embeddings with prompt augmentation, and layer-wise fine-tuning in our proposed Foundational-Retaining Open Vocabulary Semantic Segmentation (FROVSS) framework. Next, we incorporate these enhancements into a UDA framework by employing distillation to stabilize training and cross-domain mixed sampling to boost adaptability without compromising generalization. The resulting UDA-FROVSS framework is the first UDA approach to effectively adapt across domains without requiring shared categories.