USDRL: Unified Skeleton-Based Dense Representation Learning with Multi-Grained Feature Decorrelation
作者: Wanjiang Weng, Hongsong Wang, Junbo Wang, Lei He, Guosen Xie
分类: cs.CV
发布日期: 2024-12-12 (更新: 2024-12-14)
备注: Accepted by AAAI 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出USDRL框架,通过多粒度特征解耦学习骨骼动作的稠密表征,提升动作识别、检索和检测性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 骨骼动作识别 对比学习 特征解耦 稠密表征学习 时空编码器 动作检索 动作检测
📋 核心要点
- 现有基于骨骼的对比学习方法依赖负样本,需要额外的动量编码器和记忆库,增加了模型训练的难度。
- USDRL框架通过多粒度特征解耦,减少时间、空间和实例域上的冗余信息,从而最大化特征信息的提取。
- 设计的稠密时空编码器(DSTE)能够有效捕获细粒度的动作表征,显著提升了动作识别、检索和检测等任务的性能。
📝 摘要(中文)
本文提出了一种统一的基于骨骼的稠密表征学习框架USDRL,该框架基于特征解耦,旨在解决现有对比学习方法中负样本依赖以及忽略局部表征的问题。USDRL采用跨时间、空间和实例域的多粒度特征解耦,以减少表征维度之间的冗余,从而最大限度地提取特征信息。此外,我们设计了一个稠密时空编码器(DSTE),以有效地捕获细粒度的动作表征,从而提高稠密预测任务的性能。在NTU-60、NTU-120、PKU-MMD I和PKU-MMD II等基准数据集上进行的大量实验表明,我们的方法显著优于当前最先进的方法,涵盖了动作识别、动作检索和动作检测等不同的下游任务。代码和模型已开源。
🔬 方法详解
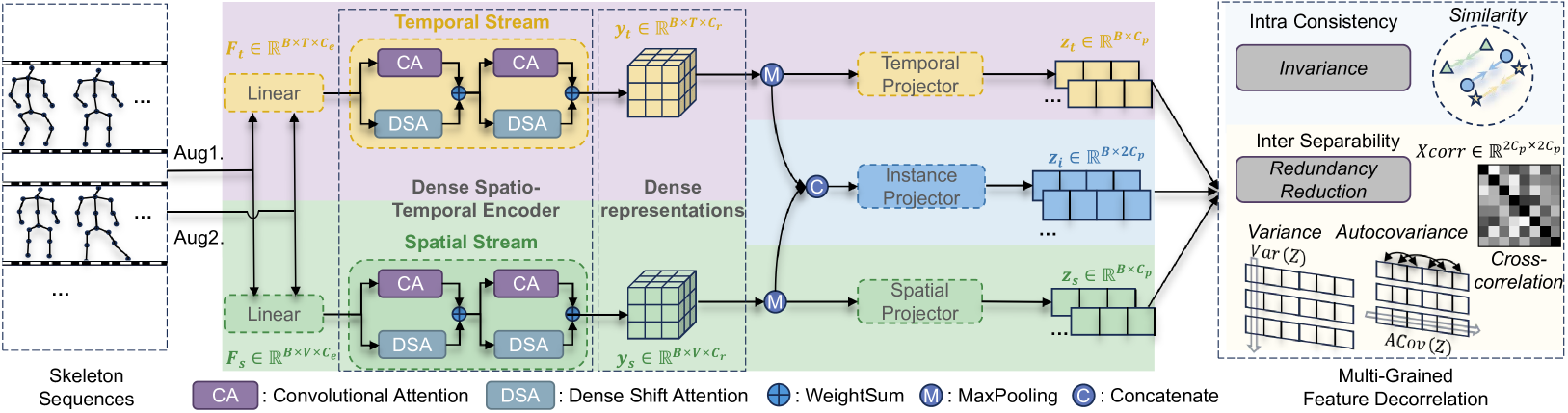
问题定义:现有基于骨骼的动作识别方法,特别是基于对比学习的方法,主要依赖负样本进行训练,这需要维护一个较大的负样本集合,增加了训练的复杂性。此外,这些方法侧重于学习全局表征,忽略了对稠密预测任务至关重要的局部和细粒度表征。
核心思路:USDRL的核心思路是通过特征解耦来减少表征中的冗余信息,从而提高特征的表达能力。通过在时间、空间和实例三个维度上进行解耦,使得模型能够学习到更加独立和具有区分性的特征,从而提升模型在各种下游任务上的性能。
技术框架:USDRL框架主要包含两个核心模块:稠密时空编码器(DSTE)和多粒度特征解耦模块。DSTE负责提取细粒度的时空特征,而特征解耦模块则负责减少特征之间的冗余。整个框架的训练过程通过对比学习的方式进行,但避免了对大量负样本的依赖。
关键创新:USDRL的关键创新在于提出了多粒度特征解耦的思想,并将其应用于基于骨骼的动作表征学习中。与传统的对比学习方法不同,USDRL通过解耦特征来提高表征的质量,而不是依赖大量的负样本。此外,DSTE的设计也使得模型能够更好地捕捉细粒度的时空信息。
关键设计:在时间维度上,采用时间上的对比损失来解耦不同时间步的特征;在空间维度上,采用空间上的对比损失来解耦不同关节的特征;在实例维度上,采用实例间的对比损失来解耦不同实例的特征。DSTE的具体结构未知,但其目标是提取细粒度的时空特征。
🖼️ 关键图片


📊 实验亮点
USDRL在NTU-60、NTU-120、PKU-MMD I和PKU-MMD II等多个数据集上取得了显著的性能提升,超越了当前最先进的方法。具体提升幅度未知,但摘要中明确指出是“显著优于”。实验结果表明,USDRL在动作识别、动作检索和动作检测等多个下游任务上均表现出色。
🎯 应用场景
USDRL框架在人机交互、智能监控、虚拟现实等领域具有广泛的应用前景。例如,在智能监控中,可以利用USDRL进行异常行为检测;在虚拟现实中,可以用于捕捉和识别用户的动作,从而实现更加自然和流畅的交互。该研究的成果有助于提升相关系统的智能化水平和用户体验。
📄 摘要(原文)
Contrastive learning has achieved great success in skeleton-based representation learning recently. However, the prevailing methods are predominantly negative-based, necessitating additional momentum encoder and memory bank to get negative samples, which increases the difficulty of model training. Furthermore, these methods primarily concentrate on learning a global representation for recognition and retrieval tasks, while overlooking the rich and detailed local representations that are crucial for dense prediction tasks. To alleviate these issues, we introduce a Unified Skeleton-based Dense Representation Learning framework based on feature decorrelation, called USDRL, which employs feature decorrelation across temporal, spatial, and instance domains in a multi-grained manner to reduce redundancy among dimensions of the representations to maximize information extraction from features. Additionally, we design a Dense Spatio-Temporal Encoder (DSTE) to capture fine-grained action representations effectively, thereby enhancing the performance of dense prediction tasks. Comprehensive experiments, conducted on the benchmarks NTU-60, NTU-120, PKU-MMD I, and PKU-MMD II, across diverse downstream tasks including action recognition, action retrieval, and action detection, conclusively demonstrate that our approach significantly outperforms the current state-of-the-art (SOTA) approaches. Our code and models are available at https://github.com/wengwanjiang/USDRL.