YingSound: Video-Guided Sound Effects Generation with Multi-modal Chain-of-Thought Controls
作者: Zihao Chen, Haomin Zhang, Xinhan Di, Haoyu Wang, Sizhe Shan, Junjie Zheng, Yunming Liang, Yihan Fan, Xinfa Zhu, Wenjie Tian, Yihua Wang, Chaofan Ding, Lei Xie
分类: cs.SD, cs.CV, cs.MM, eess.AS
发布日期: 2024-12-12
备注: 16 pages, 4 figures
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
YingSound:提出基于多模态CoT控制的视频引导音效生成方法,解决少样本场景下的高质量音效生成问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频音效生成 多模态学习 链式思考 少样本学习 音视频融合 条件流匹配 Transformer
📋 核心要点
- 现有方法在产品级视频音效生成中,面临真实场景下标注数据稀缺的挑战,难以生成高质量音效。
- YingSound通过条件流匹配Transformer实现音视频模态语义对齐,并引入多模态CoT方法生成精细音效。
- 实验结果表明,YingSound在各种条件输入下,能够有效生成高质量的同步声音,并在V2A数据集上表现出色。
📝 摘要(中文)
本文提出YingSound,一个用于视频引导音效生成的基础模型,旨在支持少样本场景下的高质量音频生成,解决产品级视频音效生成中标记数据稀缺的问题。YingSound主要包含两个模块。第一个模块使用条件流匹配Transformer,在音频和视觉模态之间实现有效的语义对齐,构建一个可学习的音视频聚合器(AVA),在多个阶段整合高分辨率视觉特征和相应的音频特征。第二个模块采用多模态视觉-音频链式思考(CoT)方法,在少样本设置中生成更精细的音效。此外,本文还提出了一个包含各种真实世界场景的行业标准视频到音频(V2A)数据集。通过自动评估和人工研究表明,YingSound能够跨各种条件输入有效地生成高质量的同步声音。
🔬 方法详解
问题定义:论文旨在解决产品级视频音效生成中,由于真实场景下标注数据稀缺,导致难以生成高质量音效的问题。现有方法在少样本学习场景下表现不佳,无法有效利用视觉信息指导音频生成。
核心思路:论文的核心思路是构建一个能够有效融合视觉和音频信息,并具备链式思考能力的模型。通过学习音视频之间的语义关联,并利用视觉信息引导音频生成,从而在少样本场景下也能生成高质量的音效。多模态CoT的引入,使得模型能够逐步推理并生成更精细的音效。
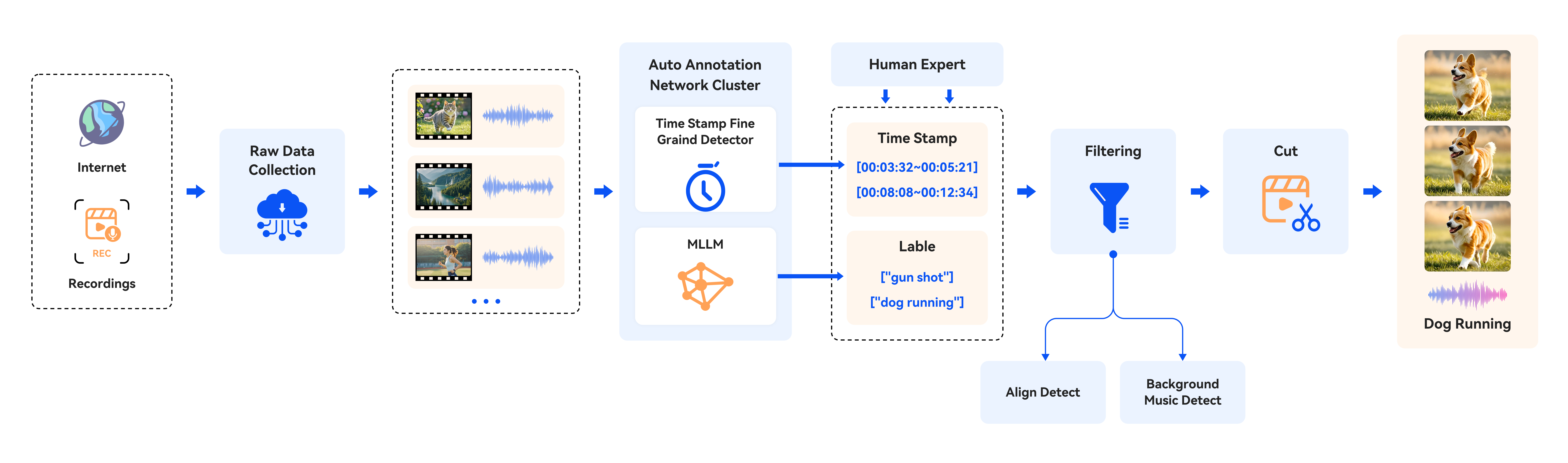
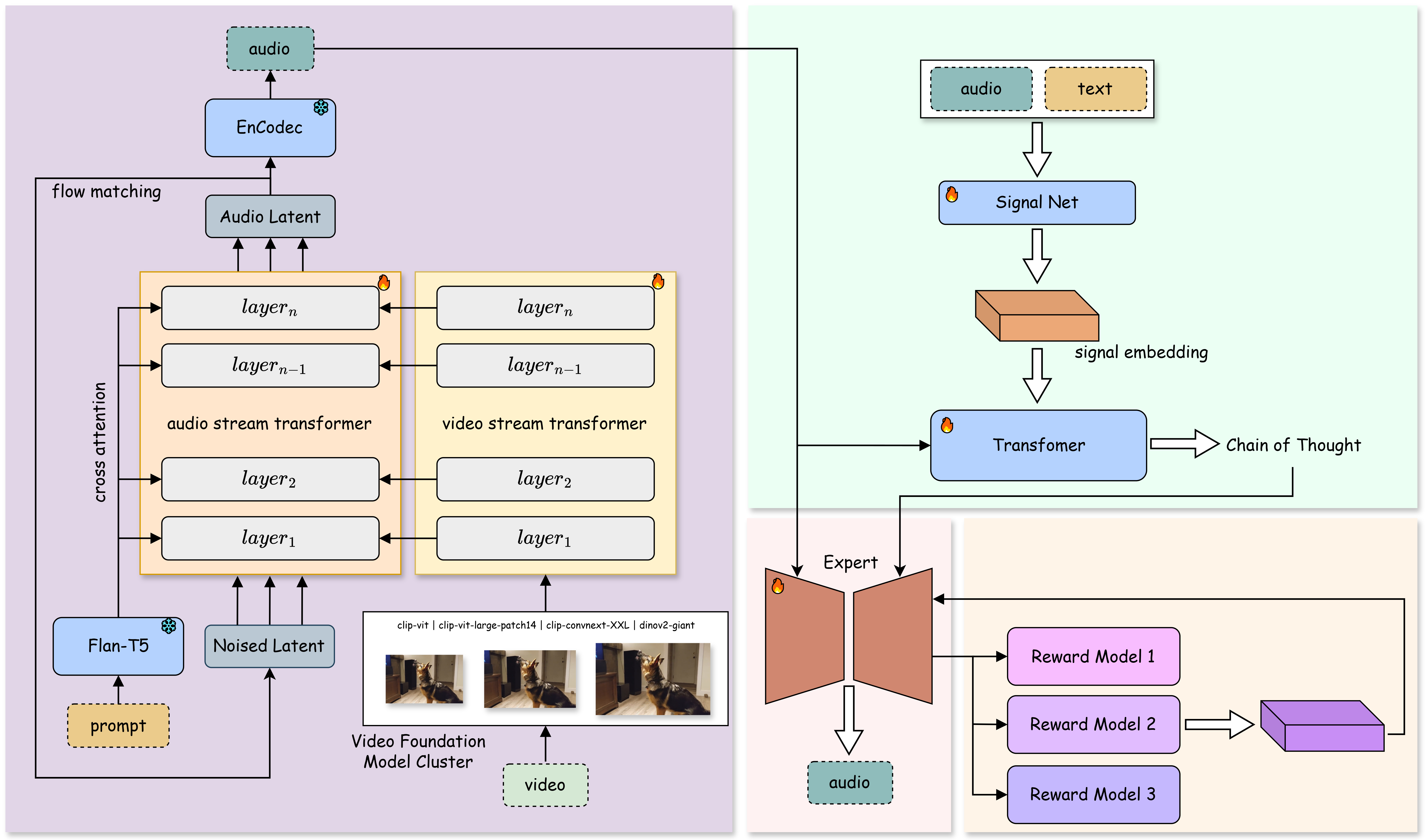
技术框架:YingSound由两个主要模块组成:1) 音视频聚合器(AVA):使用条件流匹配Transformer,将高分辨率视觉特征与对应的音频特征在多个阶段进行整合,实现音视频模态的语义对齐。2) 多模态视觉-音频链式思考(CoT)模块:利用视觉信息作为提示,引导模型逐步推理并生成更精细的音效。整体流程是从视频中提取视觉特征,然后通过AVA模块与音频特征融合,最后通过CoT模块生成最终的音效。
关键创新:论文的关键创新在于:1) 提出了一种可学习的音视频聚合器(AVA),能够有效融合视觉和音频信息。2) 引入了多模态视觉-音频链式思考(CoT)方法,使得模型能够逐步推理并生成更精细的音效。3) 构建了一个包含各种真实世界场景的行业标准视频到音频(V2A)数据集。
关键设计:条件流匹配Transformer的具体结构未知,但其目标是学习一个从视觉特征到音频特征的映射。多模态CoT模块的具体实现方式未知,但其核心思想是利用视觉信息作为提示,引导模型逐步推理并生成更精细的音效。损失函数的设计可能包括音频重建损失、音视频同步损失等。数据集V2A的详细信息未知,但它包含了各种真实世界场景。
🖼️ 关键图片
📊 实验亮点
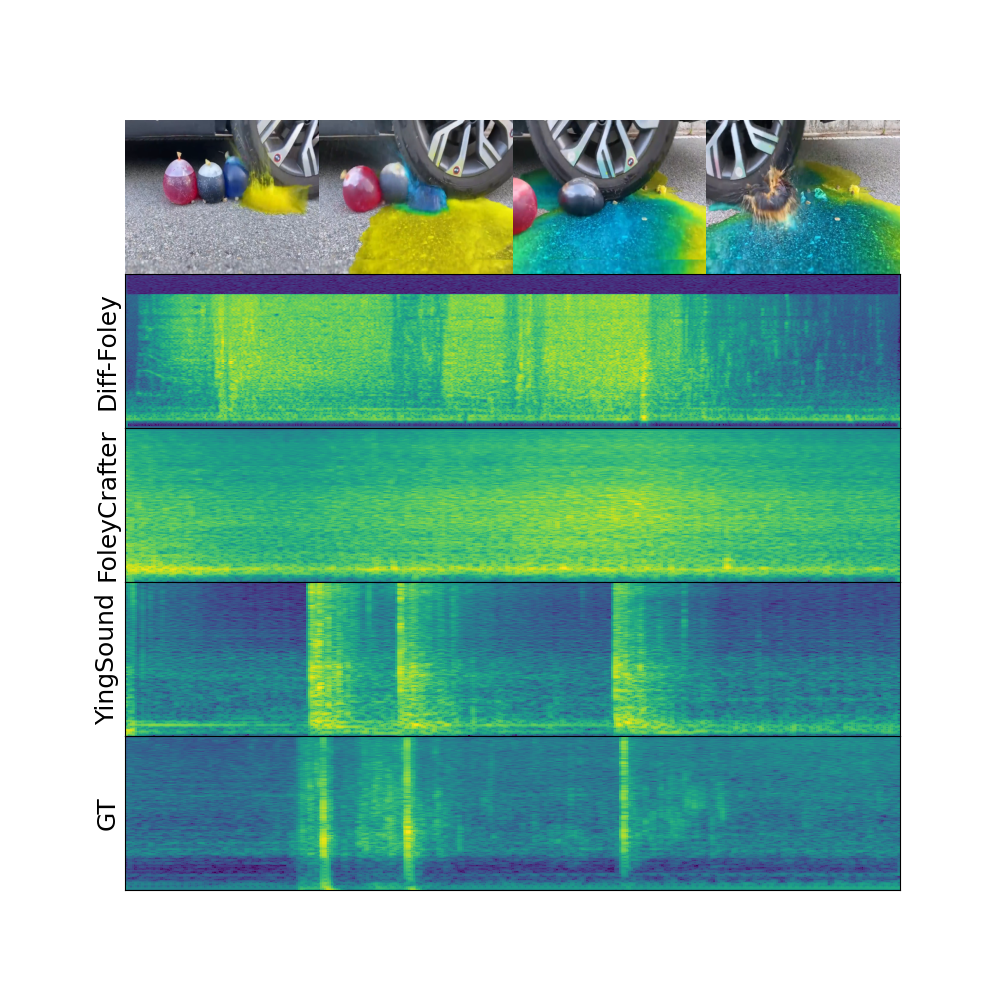
论文通过自动评估和人工研究表明,YingSound能够跨各种条件输入有效地生成高质量的同步声音。具体性能数据未知,但结果表明YingSound在音效质量和同步性方面均优于现有方法。此外,论文还构建了一个新的行业标准视频到音频(V2A)数据集,为相关研究提供了benchmark。
🎯 应用场景
YingSound可应用于电影制作、游戏开发、广告制作等领域,为视频内容自动生成高质量的音效,降低人工成本,提高制作效率。该研究的未来影响在于推动视频内容创作的自动化和智能化,提升用户体验。
📄 摘要(原文)
Generating sound effects for product-level videos, where only a small amount of labeled data is available for diverse scenes, requires the production of high-quality sounds in few-shot settings. To tackle the challenge of limited labeled data in real-world scenes, we introduce YingSound, a foundation model designed for video-guided sound generation that supports high-quality audio generation in few-shot settings. Specifically, YingSound consists of two major modules. The first module uses a conditional flow matching transformer to achieve effective semantic alignment in sound generation across audio and visual modalities. This module aims to build a learnable audio-visual aggregator (AVA) that integrates high-resolution visual features with corresponding audio features at multiple stages. The second module is developed with a proposed multi-modal visual-audio chain-of-thought (CoT) approach to generate finer sound effects in few-shot settings. Finally, an industry-standard video-to-audio (V2A) dataset that encompasses various real-world scenarios is presented. We show that YingSound effectively generates high-quality synchronized sounds across diverse conditional inputs through automated evaluations and human studies. Project Page: \url{https://giantailab.github.io/yingsound/}