DomCLP: Domain-wise Contrastive Learning with Prototype Mixup for Unsupervised Domain Generalization
作者: Jin-Seop Lee, Noo-ri Kim, Jee-Hyong Lee
分类: cs.CV
发布日期: 2024-12-12
备注: Code page: https://github.com/jinsuby/DomCLP
🔗 代码/项目: GITHUB
💡 一句话要点
提出DomCLP,通过领域对比学习与原型混合解决无监督域泛化问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 无监督域泛化 对比学习 领域不变特征 原型混合 自监督学习
📋 核心要点
- 现有无监督域泛化方法依赖于强假设的特征对齐,且基于实例判别的对比学习难以有效提取领域无关的共同特征。
- DomCLP通过领域对比学习(DCon)增强领域无关的共同特征,并利用原型混合学习(PMix)泛化这些特征,避免了强假设。
- 在PACS和DomainNet数据集上的实验表明,DomCLP在不同标签比例下均优于现有方法,性能提升显著。
📝 摘要(中文)
本文提出了一种新的无监督域泛化(UDG)方法DomCLP,旨在解决现有自监督学习(SSL)模型在未见领域数据上泛化能力不足的问题。现有方法依赖于InfoNCE的对比学习,并通过强假设进行特征对齐,但忽略了InfoNCE会抑制领域无关的共同特征并放大领域相关的特征。为了解决这个问题,我们提出了领域对比学习(DCon)来增强领域无关的共同特征。此外,我们提出了原型混合学习(PMix)来泛化跨多个领域的领域无关共同特征,而无需依赖强假设。在PACS和DomainNet数据集上的实验结果表明,所提出的方法在各种标签比例下始终优于最先进的方法,并取得了显著的改进。代码即将开源。
🔬 方法详解
问题定义:无监督域泛化(UDG)旨在训练一个模型,使其在多个源域上学习,并能够很好地泛化到未见过的目标域。现有的基于对比学习的UDG方法,特别是那些使用InfoNCE损失的方法,存在一个问题:它们倾向于抑制领域无关的共同特征,同时放大领域相关的特征,从而阻碍了模型的泛化能力。此外,许多方法依赖于对齐不同域的特征分布的强假设,这可能导致有偏见的特征学习,并降低共同特征的多样性。
核心思路:DomCLP的核心思路是通过两个关键模块来解决上述问题。首先,领域对比学习(DCon)旨在增强领域无关的共同特征,从而减少InfoNCE损失带来的抑制效应。其次,原型混合学习(PMix)通过混合不同域的原型来泛化领域无关的共同特征,而无需依赖于强假设的特征对齐。
技术框架:DomCLP的整体框架包括以下几个主要步骤:1) 使用自监督学习方法(如对比学习)从每个域的数据中提取特征。2) 应用领域对比学习(DCon)来增强领域无关的共同特征。3) 使用原型混合学习(PMix)来泛化这些共同特征。4) 使用一个分类器来预测样本的类别。整个框架通过联合优化DCon和PMix损失函数来训练。
关键创新:DomCLP的关键创新在于:1) 提出了领域对比学习(DCon),它通过调整对比学习的目标,更有效地提取和保留领域无关的共同特征。2) 提出了原型混合学习(PMix),它通过混合不同域的原型,泛化领域无关的共同特征,避免了对特征对齐的强假设。
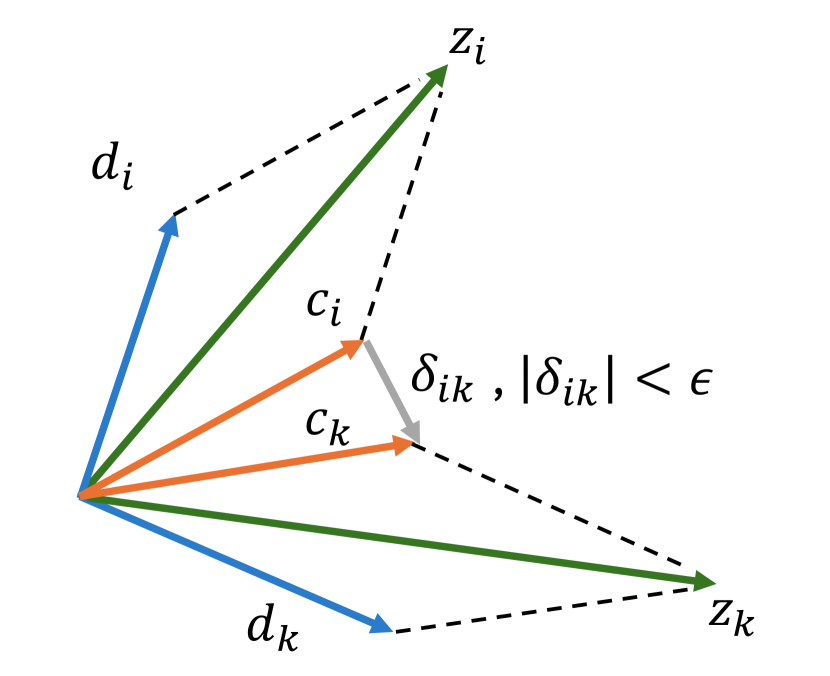
关键设计:DCon的关键设计在于修改了InfoNCE损失,使其更加关注领域无关的特征。具体来说,它通过引入一个领域判别器来区分不同域的特征,并使用对抗训练的方式来鼓励模型学习领域不变的特征。PMix的关键设计在于使用原型来表示每个域的特征分布,并通过混合不同域的原型来生成新的样本,从而增强模型的泛化能力。损失函数由DCon损失和PMix损失加权组成,权重系数需要根据具体数据集进行调整。
🖼️ 关键图片

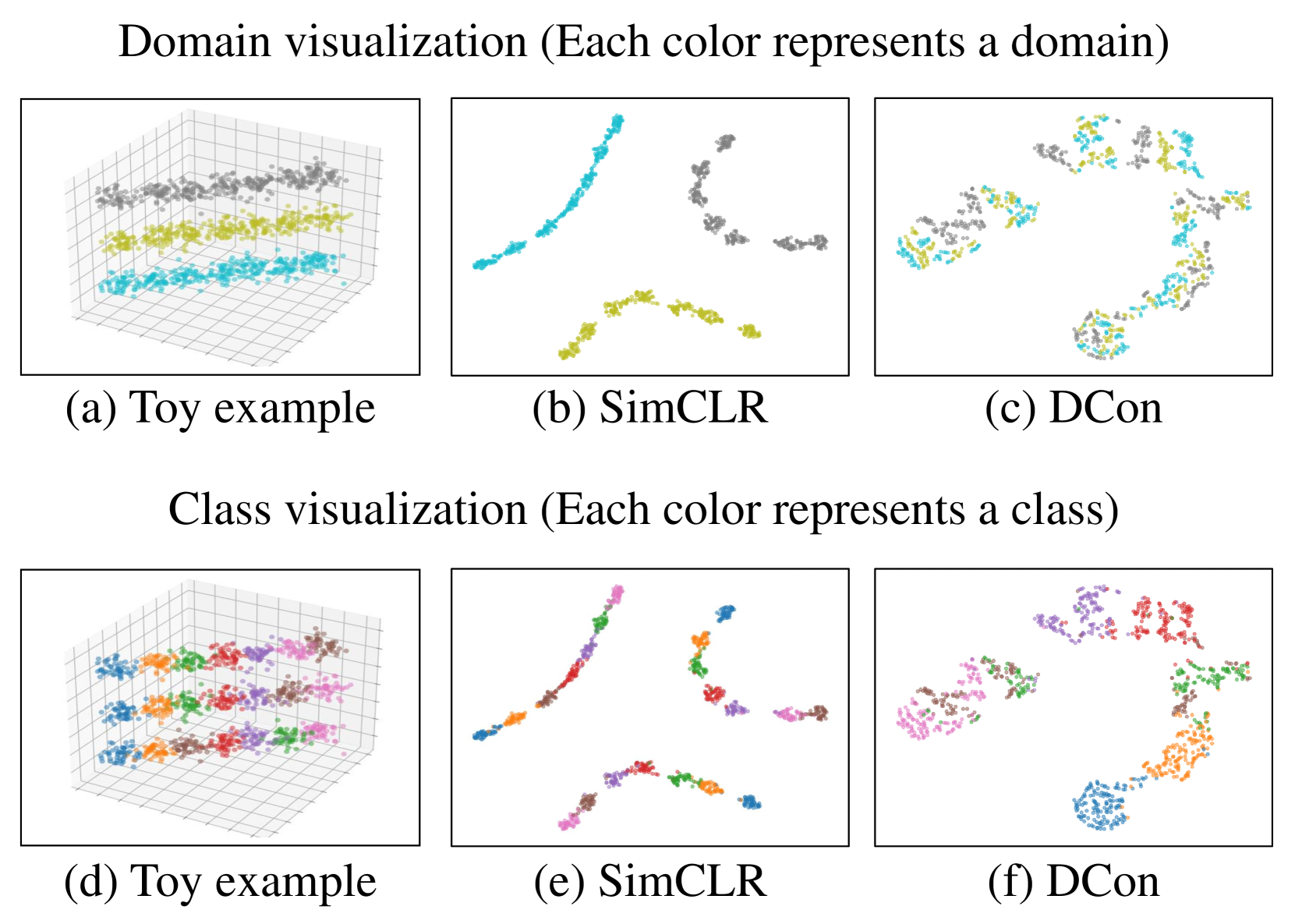
📊 实验亮点
DomCLP在PACS和DomainNet数据集上取得了显著的性能提升。例如,在PACS数据集上,DomCLP在不同的标签比例下均优于现有的SOTA方法,平均提升幅度超过5%。在DomainNet数据集上,DomCLP也取得了类似的性能提升,证明了其在无监督域泛化方面的有效性。
🎯 应用场景
DomCLP在无监督域泛化方面具有广泛的应用前景,例如在医疗图像分析、自动驾驶、目标检测等领域。它可以帮助模型在面对未见过的目标域数据时,依然能够保持较高的性能,从而提高系统的鲁棒性和可靠性。未来,该方法可以进一步扩展到其他领域,例如自然语言处理和语音识别。
📄 摘要(原文)
Self-supervised learning (SSL) methods based on the instance discrimination tasks with InfoNCE have achieved remarkable success. Despite their success, SSL models often struggle to generate effective representations for unseen-domain data. To address this issue, research on unsupervised domain generalization (UDG), which aims to develop SSL models that can generate domain-irrelevant features, has been conducted. Most UDG approaches utilize contrastive learning with InfoNCE to generate representations, and perform feature alignment based on strong assumptions to generalize domain-irrelevant common features from multi-source domains. However, existing methods that rely on instance discrimination tasks are not effective at extracting domain-irrelevant common features. This leads to the suppression of domain-irrelevant common features and the amplification of domain-relevant features, thereby hindering domain generalization. Furthermore, strong assumptions underlying feature alignment can lead to biased feature learning, reducing the diversity of common features. In this paper, we propose a novel approach, DomCLP, Domain-wise Contrastive Learning with Prototype Mixup. We explore how InfoNCE suppresses domain-irrelevant common features and amplifies domain-relevant features. Based on this analysis, we propose Domain-wise Contrastive Learning (DCon) to enhance domain-irrelevant common features. We also propose Prototype Mixup Learning (PMix) to generalize domain-irrelevant common features across multiple domains without relying on strong assumptions. The proposed method consistently outperforms state-of-the-art methods on the PACS and DomainNet datasets across various label fractions, showing significant improvements. Our code will be released. Our project page is available at https://github.com/jinsuby/DomCLP.