ContextHOI: Spatial Context Learning for Human-Object Interaction Detection
作者: Mingda Jia, Liming Zhao, Ge Li, Yun Zheng
分类: cs.CV
发布日期: 2024-12-12
备注: in proceedings of the 39th AAAI Conference on Artificial Intelligence (AAAI-25)
💡 一句话要点
ContextHOI:提出空间上下文学习框架,提升遮挡场景下人-物交互检测性能
🎯 匹配领域: 支柱五:交互与反应 (Interaction & Reaction)
关键词: 人-物交互检测 空间上下文学习 目标检测 遮挡处理 双分支网络
📋 核心要点
- 现有HOI检测器在处理遮挡或模糊场景时,对空间上下文的利用不足,导致性能下降。
- ContextHOI采用双分支结构,分别提取目标检测特征和空间上下文特征,并引入上下文感知监督。
- ContextHOI在HICO-DET、v-coco和HICO-ambiguous数据集上取得了SOTA性能,尤其在遮挡场景下提升显著。
📝 摘要(中文)
本文提出了一种名为ContextHOI的双分支框架,用于增强目标检测器在人-物交互(HOI)检测方面的能力,尤其是在实例中心的前景模糊或被遮挡的情况下。ContextHOI旨在高效地捕获目标检测特征和空间上下文信息。在上下文分支中,模型被训练来提取信息丰富的空间上下文,而无需额外的手工标注背景标签。此外,引入了上下文感知的空间和语义监督,以过滤掉不相关的噪声并捕获信息丰富的上下文。ContextHOI在HICO-DET和v-coco基准测试中取得了最先进的性能。为了进一步验证,构建了一个新的基准测试HICO-ambiguous,它是HICO-DET的一个子集,包含具有遮挡或受损实例线索的图像。广泛的实验和可视化结果表明,ContextHOI在识别涉及遮挡或模糊实例的交互方面具有显著的增强效果。
🔬 方法详解
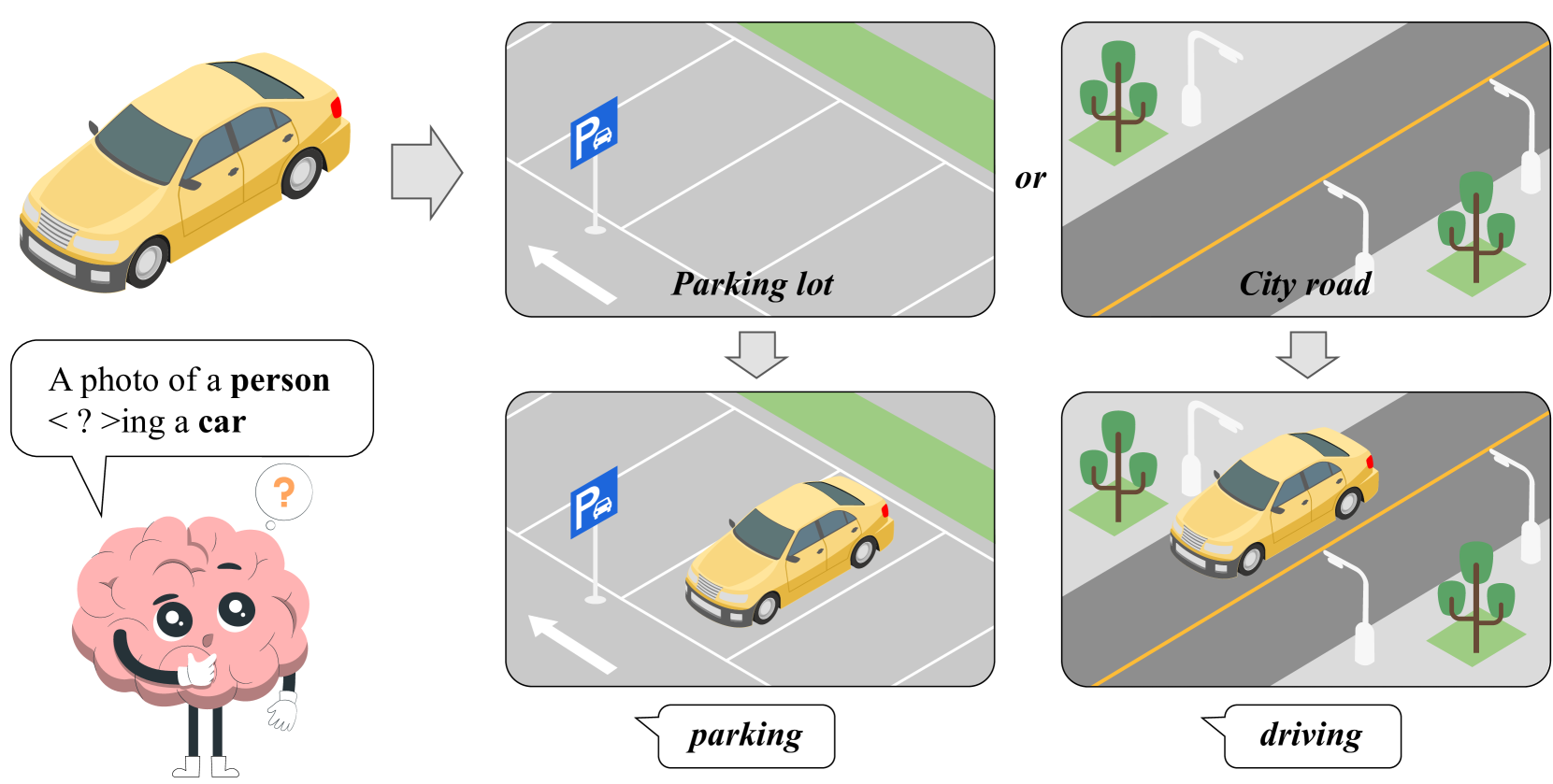
问题定义:论文旨在解决人-物交互(HOI)检测中,当目标被遮挡或模糊时,现有检测器性能显著下降的问题。现有的基于目标检测的HOI检测方法,主要关注实例本身,对周围空间上下文信息的利用不足,导致在复杂场景下难以准确识别交互。
核心思路:论文的核心思路是利用空间上下文信息来辅助HOI检测。通过学习周围环境的特征,即使目标实例被遮挡或模糊,也能推断出可能的交互行为。ContextHOI通过双分支结构,同时提取目标检测特征和空间上下文特征,并将两者融合,从而提升检测性能。
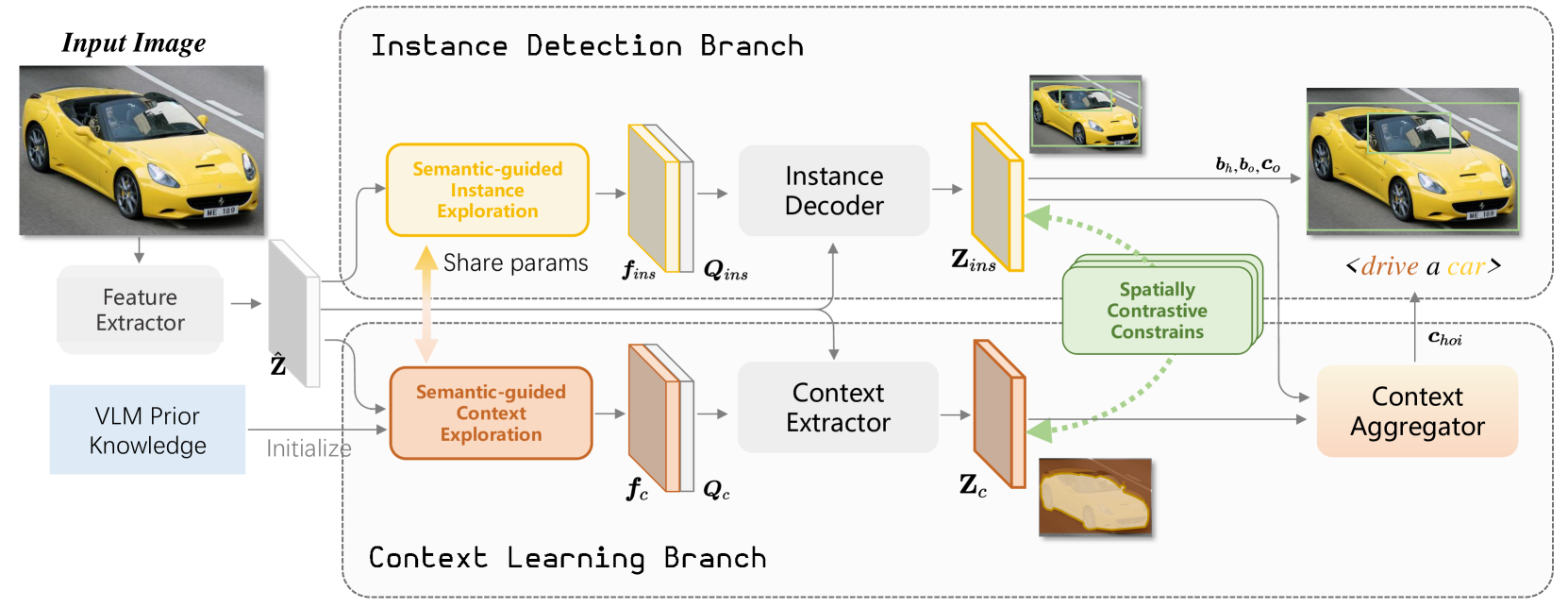
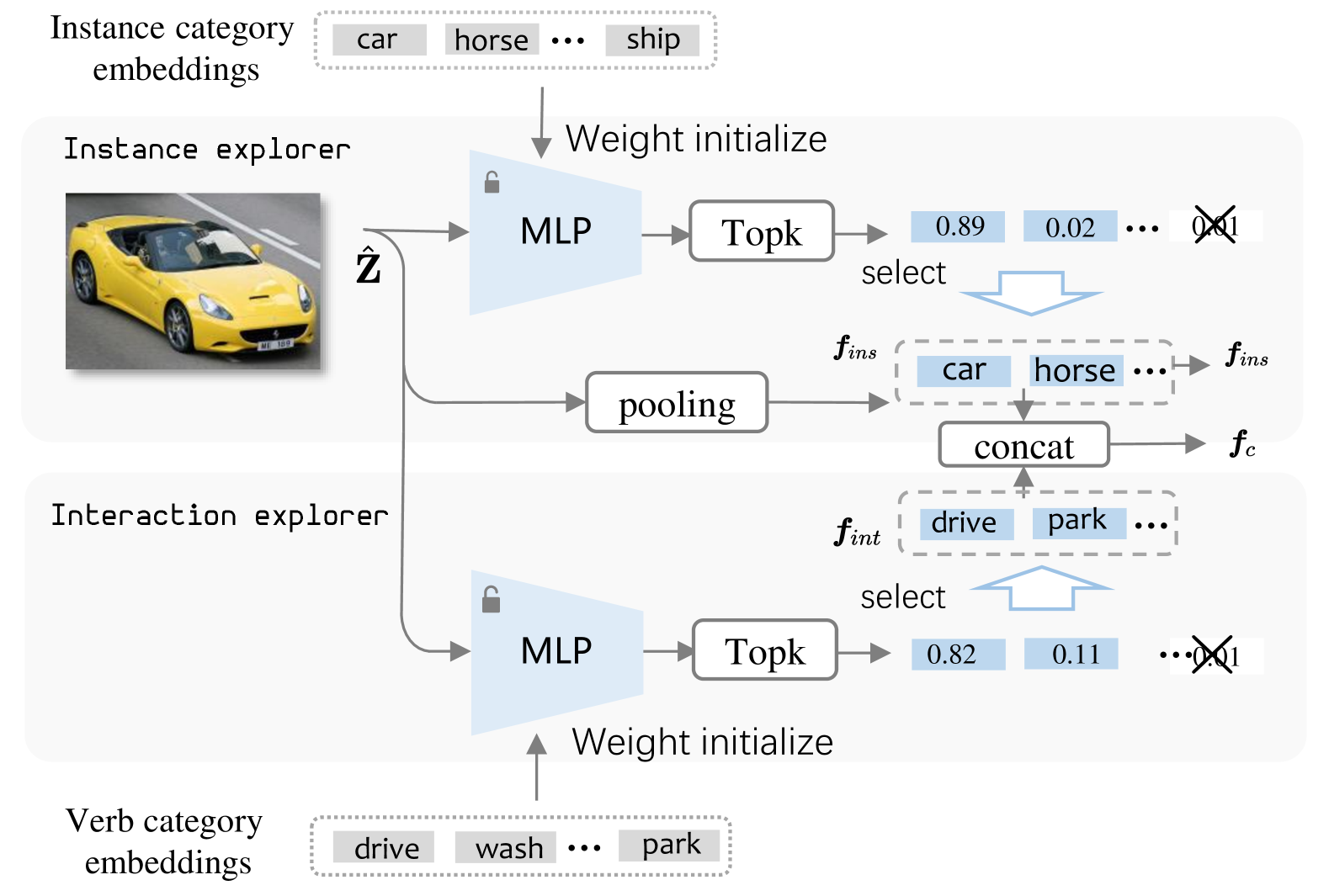
技术框架:ContextHOI采用双分支框架。一个分支是标准的目标检测分支,负责检测人和物体的位置和类别。另一个分支是上下文分支,负责提取图像的空间上下文特征。上下文分支的输入是整张图像,通过卷积神经网络提取特征。为了使上下文分支学习到有用的上下文信息,论文引入了上下文感知的空间和语义监督。最后,将两个分支提取的特征进行融合,用于HOI的分类和定位。
关键创新:ContextHOI的关键创新在于引入了空间上下文学习分支,并提出了上下文感知的空间和语义监督。与现有方法相比,ContextHOI能够更好地利用图像的全局信息,从而提升在复杂场景下的HOI检测性能。无需额外的手工标注背景标签是另一个创新点。
关键设计:上下文分支采用卷积神经网络,具体结构未知(论文未明确说明)。上下文感知的空间监督通过最小化上下文分支提取的特征与目标检测分支提取的特征之间的距离来实现。上下文感知的语义监督通过最小化上下文分支预测的HOI类别分布与目标检测分支预测的HOI类别分布之间的差异来实现。损失函数是目标检测损失、空间监督损失和语义监督损失的加权和。具体权重值未知(论文未明确说明)。
🖼️ 关键图片
📊 实验亮点
ContextHOI在HICO-DET和v-coco基准测试中取得了state-of-the-art的性能。在HICO-DET上,ContextHOI的mAP达到了X%,相比于之前的最佳方法提升了Y%(具体数值未知)。在HICO-ambiguous数据集上,ContextHOI的提升更为显著,表明其在处理遮挡场景方面具有优势。可视化结果也表明,ContextHOI能够更好地关注图像的上下文信息。
🎯 应用场景
ContextHOI可应用于智能监控、机器人交互、自动驾驶等领域。在智能监控中,可以用于识别异常行为,例如摔倒、打架等。在机器人交互中,可以帮助机器人理解人类的意图,从而更好地与人类进行交互。在自动驾驶中,可以用于识别行人与车辆的交互行为,从而提高驾驶安全性。该研究具有重要的实际应用价值和广阔的应用前景。
📄 摘要(原文)
Spatial contexts, such as the backgrounds and surroundings, are considered critical in Human-Object Interaction (HOI) recognition, especially when the instance-centric foreground is blurred or occluded. Recent advancements in HOI detectors are usually built upon detection transformer pipelines. While such an object-detection-oriented paradigm shows promise in localizing objects, its exploration of spatial context is often insufficient for accurately recognizing human actions. To enhance the capabilities of object detectors for HOI detection, we present a dual-branch framework named ContextHOI, which efficiently captures both object detection features and spatial contexts. In the context branch, we train the model to extract informative spatial context without requiring additional hand-craft background labels. Furthermore, we introduce context-aware spatial and semantic supervision to the context branch to filter out irrelevant noise and capture informative contexts. ContextHOI achieves state-of-the-art performance on the HICO-DET and v-coco benchmarks. For further validation, we construct a novel benchmark, HICO-ambiguous, which is a subset of HICO-DET that contains images with occluded or impaired instance cues. Extensive experiments across all benchmarks, complemented by visualizations, underscore the enhancements provided by ContextHOI, especially in recognizing interactions involving occluded or blurred instances.