Mojito: Motion Trajectory and Intensity Control for Video Generation
作者: Xuehai He, Shuohang Wang, Jianwei Yang, Xiaoxia Wu, Yiping Wang, Kuan Wang, Zheng Zhan, Olatunji Ruwase, Yelong Shen, Xin Eric Wang
分类: cs.CV, cs.CL
发布日期: 2024-12-12 (更新: 2025-02-05)
💡 一句话要点
Mojito:提出运动轨迹和强度可控的视频生成扩散模型
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 视频生成 扩散模型 运动控制 轨迹控制 强度控制
📋 核心要点
- 现有视频扩散模型难以有效整合方向性引导和控制运动强度,限制了视频生成的可控性。
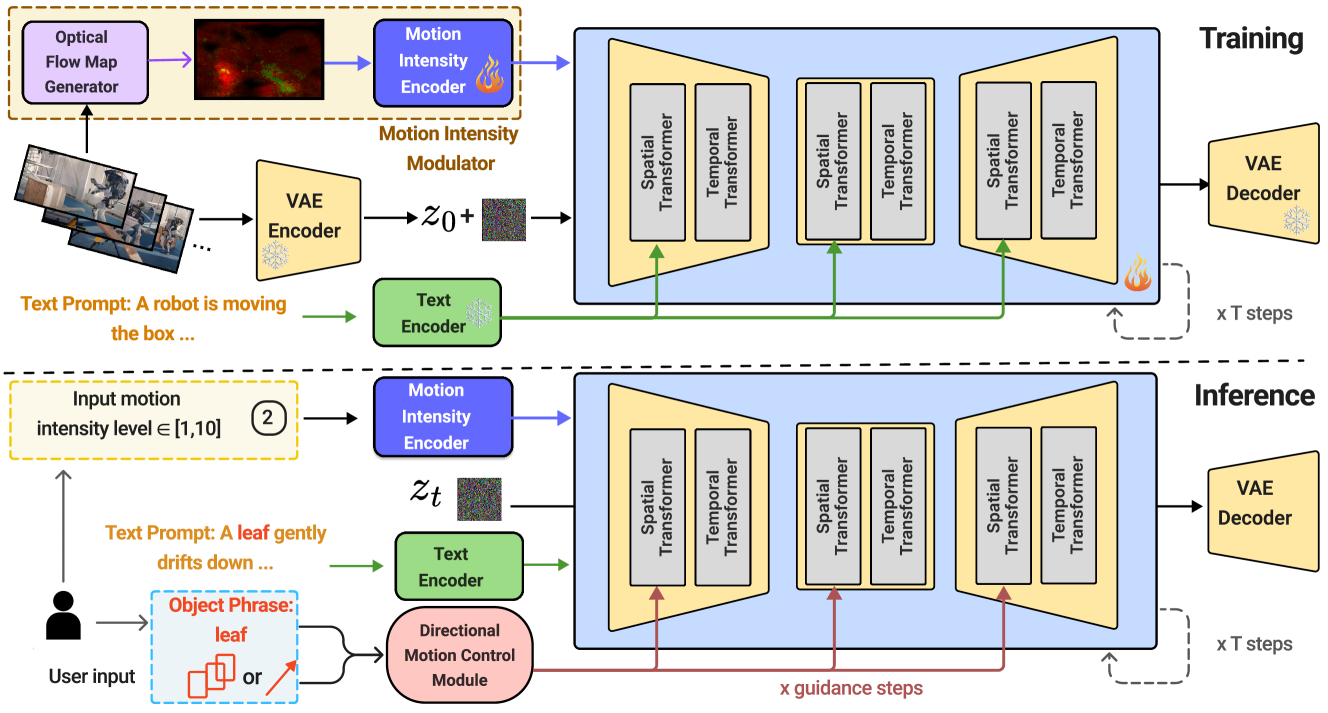
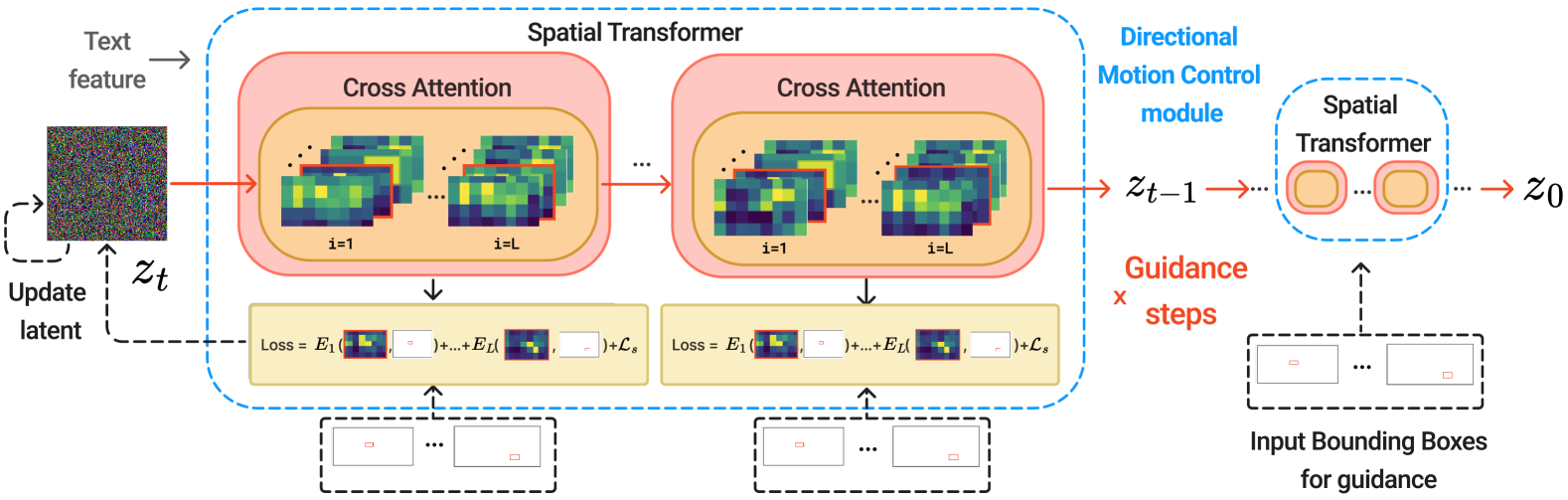
- Mojito通过引入方向运动控制(DMC)和运动强度调节器(MIM)模块,实现了对生成视频运动轨迹和强度的精确控制。
- 实验证明,Mojito能够高效地生成符合指定方向和强度的运动模式,并具备与真实世界运动一致的逼真动态效果。
📝 摘要(中文)
扩散模型在生成高质量视频内容方面展现出巨大潜力。然而,高效训练能够整合方向性引导和可控运动强度的视频扩散模型仍然是一个具有挑战性且未被充分探索的领域。为了应对这些挑战,本文提出了Mojito,一种用于文本到视频生成的扩散模型,它结合了运动轨迹和强度控制。具体来说,Mojito包含一个方向运动控制(DMC)模块,该模块利用交叉注意力来有效地引导生成对象的运动,而无需训练;以及一个运动强度调节器(MIM),它使用从视频生成的密集光流图来引导不同级别的运动强度。大量实验表明,Mojito在实现精确的轨迹和强度控制方面具有高效的计算能力,能够生成与指定方向和强度紧密匹配的运动模式,并提供与真实场景中的自然运动良好对齐的逼真动态。
🔬 方法详解
问题定义:现有的视频生成扩散模型在运动控制方面存在不足,难以同时实现对运动轨迹和运动强度的精确控制。训练能够有效整合方向性引导和可控运动强度的视频扩散模型是一个具有挑战性的问题。
核心思路:Mojito的核心思路是将运动轨迹控制和运动强度控制解耦,分别通过方向运动控制(DMC)模块和运动强度调节器(MIM)模块来实现。DMC模块利用交叉注意力机制引导运动方向,MIM模块则利用光流图引导运动强度。
技术框架:Mojito的整体框架是一个扩散模型,包含以下主要模块:文本编码器(将文本提示转换为特征向量)、DMC模块(利用交叉注意力控制运动轨迹)、MIM模块(利用光流图控制运动强度)和扩散模型解码器(生成最终视频)。训练过程中,模型学习如何根据文本提示、运动方向和运动强度生成逼真的视频。
关键创新:Mojito的关键创新在于DMC模块和MIM模块的设计。DMC模块无需额外训练即可实现运动轨迹控制,提高了训练效率。MIM模块利用光流图作为运动强度的先验信息,使得模型能够生成具有不同运动强度的视频。
关键设计:DMC模块使用交叉注意力机制,将文本特征和运动方向信息融合,从而引导生成对象的运动轨迹。MIM模块使用预训练的光流估计模型生成光流图,然后将光流图作为条件输入到扩散模型中,从而控制运动强度。损失函数包括扩散模型的标准损失函数,以及可选的运动方向和运动强度正则化项。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Mojito能够生成与指定方向和强度紧密匹配的运动模式,并且具有较高的计算效率。与现有方法相比,Mojito在运动控制的精确性和生成视频的真实感方面均有显著提升。通过定量和定性评估,证明了Mojito在运动轨迹和强度控制方面的有效性。
🎯 应用场景
Mojito在视频内容创作、游戏开发、电影特效等领域具有广泛的应用前景。它可以用于生成具有特定运动轨迹和强度的视频,例如模拟体育运动、创建动画角色运动或生成逼真的自然场景。该研究的成果有助于提高视频生成的可控性和真实感,为视频内容创作提供更多可能性。
📄 摘要(原文)
Recent advancements in diffusion models have shown great promise in producing high-quality video content. However, efficiently training video diffusion models capable of integrating directional guidance and controllable motion intensity remains a challenging and under-explored area. To tackle these challenges, this paper introduces Mojito, a diffusion model that incorporates both motion trajectory and intensity control for text-to-video generation. Specifically, Mojito features a Directional Motion Control (DMC) module that leverages cross-attention to efficiently direct the generated object's motion without training, alongside a Motion Intensity Modulator (MIM) that uses optical flow maps generated from videos to guide varying levels of motion intensity. Extensive experiments demonstrate Mojito's effectiveness in achieving precise trajectory and intensity control with high computational efficiency, generating motion patterns that closely match specified directions and intensities, providing realistic dynamics that align well with natural motion in real-world scenarios.