Selective Visual Prompting in Vision Mamba
作者: Yifeng Yao, Zichen Liu, Zhenyu Cui, Yuxin Peng, Jiahuan Zhou
分类: cs.CV, cs.AI
发布日期: 2024-12-12
备注: in Proceedings of the 39th AAAI Conference on Artificial Intelligence (AAAI-25)
🔗 代码/项目: GITHUB
💡 一句话要点
针对Vision Mamba,提出选择性视觉提示(SVP)方法,提升下游任务微调性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: Vision Mamba 视觉提示 高效微调 选择性提示 状态空间模型
📋 核心要点
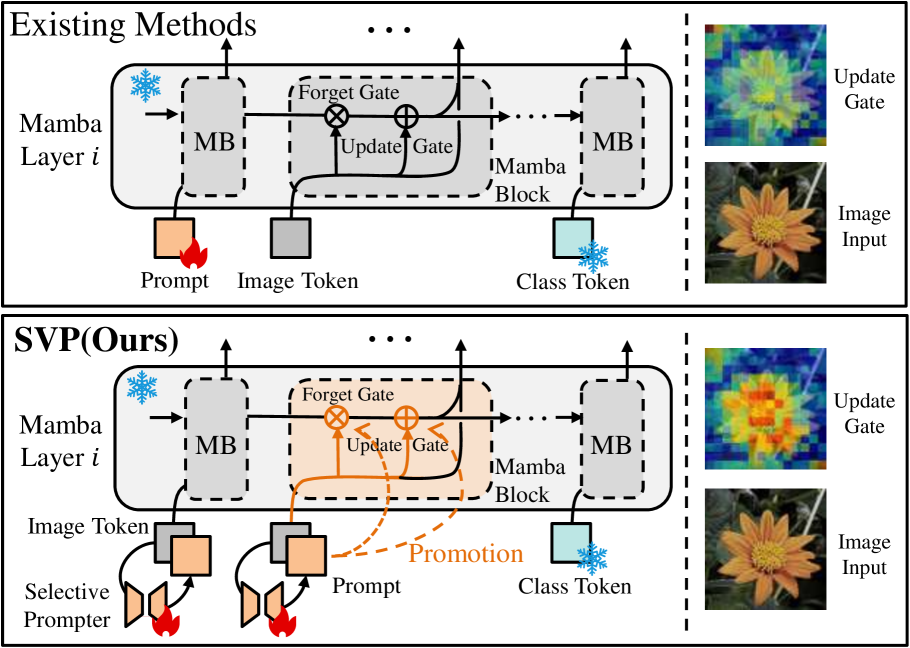
- 现有视觉提示方法忽略了Vision Mamba (Vim)独特的序列token压缩和传播特性,导致判别信息提取和传播受阻。
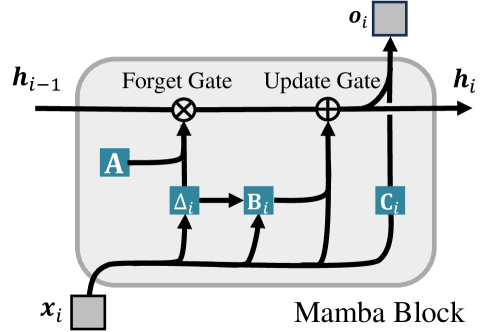
- 提出选择性视觉提示(SVP)方法,通过token级别的提示生成,自适应激活Mamba块内的更新门和遗忘门,促进判别信息传播。
- 实验结果表明,SVP在多个大规模基准测试中显著优于现有方法,验证了其有效性。
📝 摘要(中文)
预训练的Vision Mamba (Vim) 模型在各种计算机视觉任务中表现出卓越的性能,这归功于其独特的选择性状态空间模型设计。为了进一步扩展其在各种下游视觉任务中的适用性,Vim 模型可以使用高效的微调技术(即视觉提示)进行适配。然而,现有的视觉提示方法主要针对利用全局注意力的 Vision Transformer (ViT) 模型,忽略了 Vim 独特的序列token压缩和传播特性。具体来说,现有方法中前缀于序列的提示token不足以有效地激活整个序列中的输入门和遗忘门,从而阻碍了判别信息的提取和传播。为了解决这个限制,我们提出了一种新的选择性视觉提示 (SVP) 方法,专门用于 Vim 的高效微调。为了防止状态空间传播过程中判别信息的丢失,SVP 采用轻量级的选择性提示器进行 token 级别的提示生成,确保自适应地激活 Mamba 块内的更新门和遗忘门,从而促进判别信息的传播。此外,考虑到 Vim 传播共享的跨层信息和特定的内层信息,我们进一步使用双路径结构(跨提示和内提示)来改进 SVP。跨提示利用跨层共享参数,而内提示采用不同的参数,分别促进共享信息和特定信息的传播。在各种大规模基准上的大量实验结果表明,我们提出的 SVP 显著优于最先进的方法。
🔬 方法详解
问题定义:现有视觉提示方法主要针对Vision Transformer (ViT)模型设计,依赖全局注意力机制。然而,Vision Mamba (Vim)具有独特的序列token压缩和传播特性,现有方法无法有效激活Vim中的输入门和遗忘门,导致判别信息在状态空间传播过程中丢失,限制了Vim在下游任务中的微调性能。
核心思路:论文的核心思路是设计一种专门针对Vision Mamba的选择性视觉提示(SVP)方法,该方法能够自适应地激活Mamba块内的更新门和遗忘门,从而促进判别信息的传播。通过token级别的提示生成,SVP能够更精细地控制信息的流动,避免重要信息的丢失。
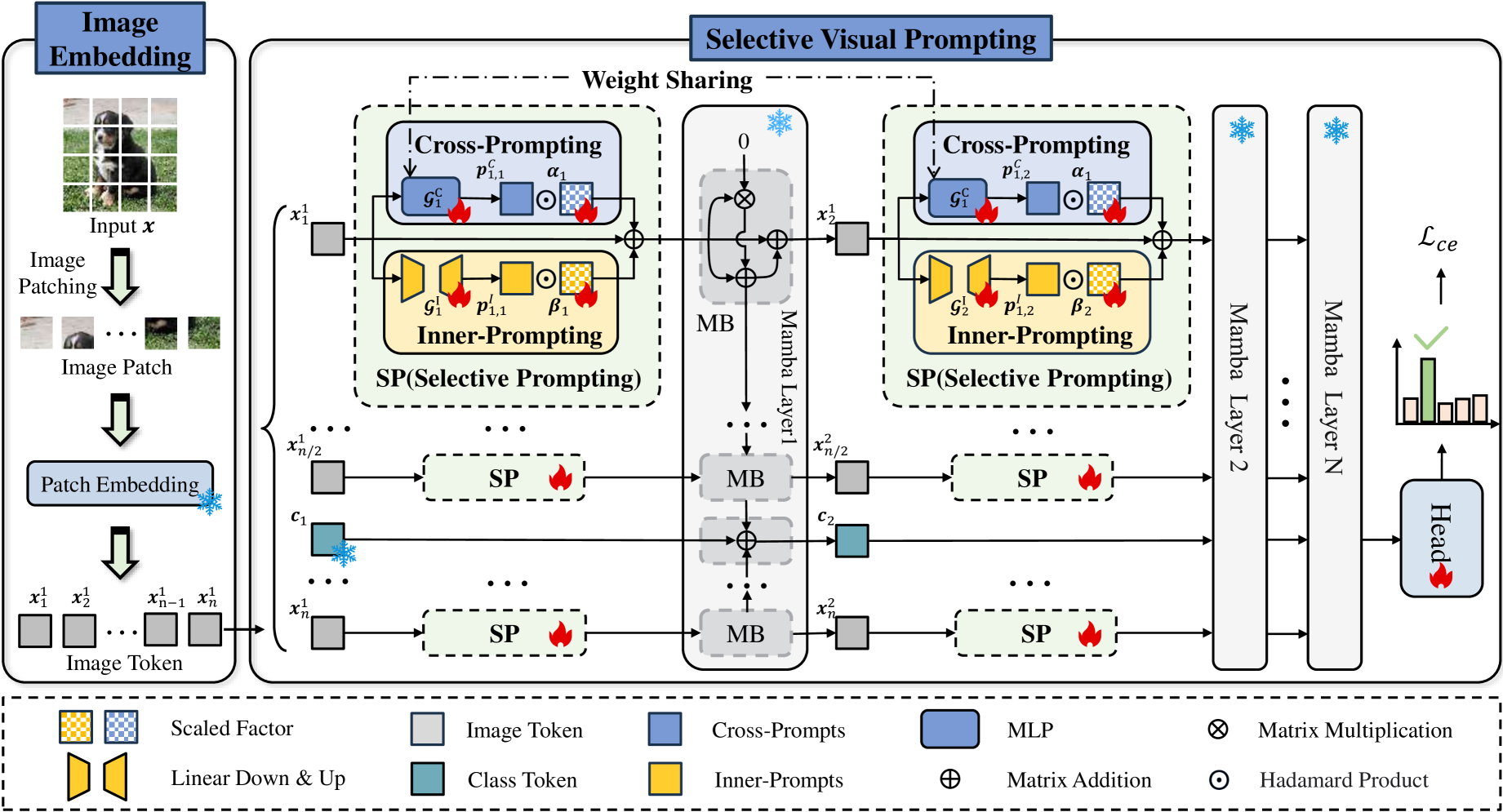
技术框架:SVP包含两个主要组成部分:跨提示(Cross-Prompting)和内提示(Inner-Prompting)。跨提示利用跨层共享参数,用于传播共享的跨层信息。内提示则采用不同的参数,用于传播特定的内层信息。整体流程是,输入图像首先经过Vim的主干网络,然后在每个Mamba块中,SVP生成token级别的提示,这些提示用于调整更新门和遗忘门的激活状态,从而控制信息的传播。
关键创新:SVP的关键创新在于其选择性提示机制,它能够根据token的特性自适应地生成提示,并利用这些提示来控制Mamba块中信息的流动。与现有方法中简单地将提示token添加到序列前端不同,SVP能够更精细地控制信息的传播,从而避免重要信息的丢失。此外,双路径结构(跨提示和内提示)的设计也考虑了Vim中共享信息和特定信息的传播需求。
关键设计:SVP使用轻量级的选择性提示器进行token级别的提示生成。这些提示器可以是简单的MLP或者更复杂的网络结构。跨提示和内提示的参数设置需要根据具体的任务进行调整。损失函数通常采用交叉熵损失或者其他适用于下游任务的损失函数。网络结构方面,SVP可以灵活地集成到现有的Vim模型中,无需对Vim的主干网络进行修改。
🖼️ 关键图片
📊 实验亮点
实验结果表明,SVP在多个大规模基准测试中显著优于现有方法。例如,在ImageNet数据集上,SVP相比于基线方法取得了X%的性能提升(具体数据需要在论文中查找)。此外,SVP在计算效率方面也具有优势,能够在保证性能的同时降低计算成本。
🎯 应用场景
该研究成果可广泛应用于各种计算机视觉任务,例如图像分类、目标检测、语义分割等。通过高效地微调Vision Mamba模型,可以降低计算成本,提高模型在实际应用中的性能。该方法在资源受限的场景下具有重要意义,例如移动设备上的图像识别、边缘计算等。
📄 摘要(原文)
Pre-trained Vision Mamba (Vim) models have demonstrated exceptional performance across various computer vision tasks in a computationally efficient manner, attributed to their unique design of selective state space models. To further extend their applicability to diverse downstream vision tasks, Vim models can be adapted using the efficient fine-tuning technique known as visual prompting. However, existing visual prompting methods are predominantly tailored for Vision Transformer (ViT)-based models that leverage global attention, neglecting the distinctive sequential token-wise compression and propagation characteristics of Vim. Specifically, existing prompt tokens prefixed to the sequence are insufficient to effectively activate the input and forget gates across the entire sequence, hindering the extraction and propagation of discriminative information. To address this limitation, we introduce a novel Selective Visual Prompting (SVP) method specifically for the efficient fine-tuning of Vim. To prevent the loss of discriminative information during state space propagation, SVP employs lightweight selective prompters for token-wise prompt generation, ensuring adaptive activation of the update and forget gates within Mamba blocks to promote discriminative information propagation. Moreover, considering that Vim propagates both shared cross-layer information and specific inner-layer information, we further refine SVP with a dual-path structure: Cross-Prompting and Inner-Prompting. Cross-Prompting utilizes shared parameters across layers, while Inner-Prompting employs distinct parameters, promoting the propagation of both shared and specific information, respectively. Extensive experimental results on various large-scale benchmarks demonstrate that our proposed SVP significantly outperforms state-of-the-art methods. Our code is available at https://github.com/zhoujiahuan1991/AAAI2025-SVP.