LLaVA-Zip: Adaptive Visual Token Compression with Intrinsic Image Information
作者: Ke Wang, Hong Xuan
分类: cs.CV, cs.AI, cs.LG
发布日期: 2024-12-11
💡 一句话要点
LLaVA-Zip:利用内在图像信息的自适应视觉Token压缩,提升多图/视频处理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大模型 视觉Token压缩 动态特征图缩减 LLaVA 多图处理 视频理解 资源受限环境
📋 核心要点
- 现有MLLM模型在处理多图或视频时,视觉Token占用过多,限制了模型性能和应用范围。
- 论文提出动态特征图缩减(DFMR)方法,自适应压缩视觉Token,释放Token容量,提升模型效率。
- 实验表明,DFMR显著提升了LLaVA-1.5在不同视觉Token长度下的性能,尤其是在多图/视频场景下。
📝 摘要(中文)
利用指令跟随数据的多模态大型语言模型(MLLM),如LLaVA,在工业界取得了显著进展。这些模型的一个主要限制是视觉token消耗了LLM中最大token限制的很大一部分,导致计算需求增加,并且当提示包含多个图像或视频时性能下降。工业界通常通过增加计算能力来缓解这个问题,但在资源有限的学术环境中,这种方法不太可行。在本研究中,我们提出了基于LLaVA-1.5的动态特征图缩减(DFMR)来解决视觉token过载的挑战。DFMR动态地压缩视觉token,释放token容量。实验结果表明,将DFMR集成到LLaVA-1.5中显著提高了LLaVA在不同视觉token长度下的性能,为扩展LLaVA以处理资源受限的学术环境中的多图像和视频场景提供了一个有希望的解决方案,并且它也可以应用于工业环境中进行数据增强,以帮助缓解持续预训练阶段开放域图像-文本对数据集的稀缺性。
🔬 方法详解
问题定义:现有的大型多模态模型(MLLM),如LLaVA,在处理包含大量视觉信息的输入(例如多张图片或视频)时,会面临视觉Token数量过多,超出模型Token限制的问题。这导致模型无法充分利用视觉信息,影响性能,并且增加了计算成本。工业界通常通过增加计算资源来解决,但对于资源有限的学术界来说,这种方法不适用。
核心思路:论文的核心思路是动态地压缩视觉特征图,减少视觉Token的数量,从而在不显著损失视觉信息的前提下,降低计算负担,并释放Token容量。这种动态压缩是自适应的,能够根据输入图像的内在信息调整压缩程度。
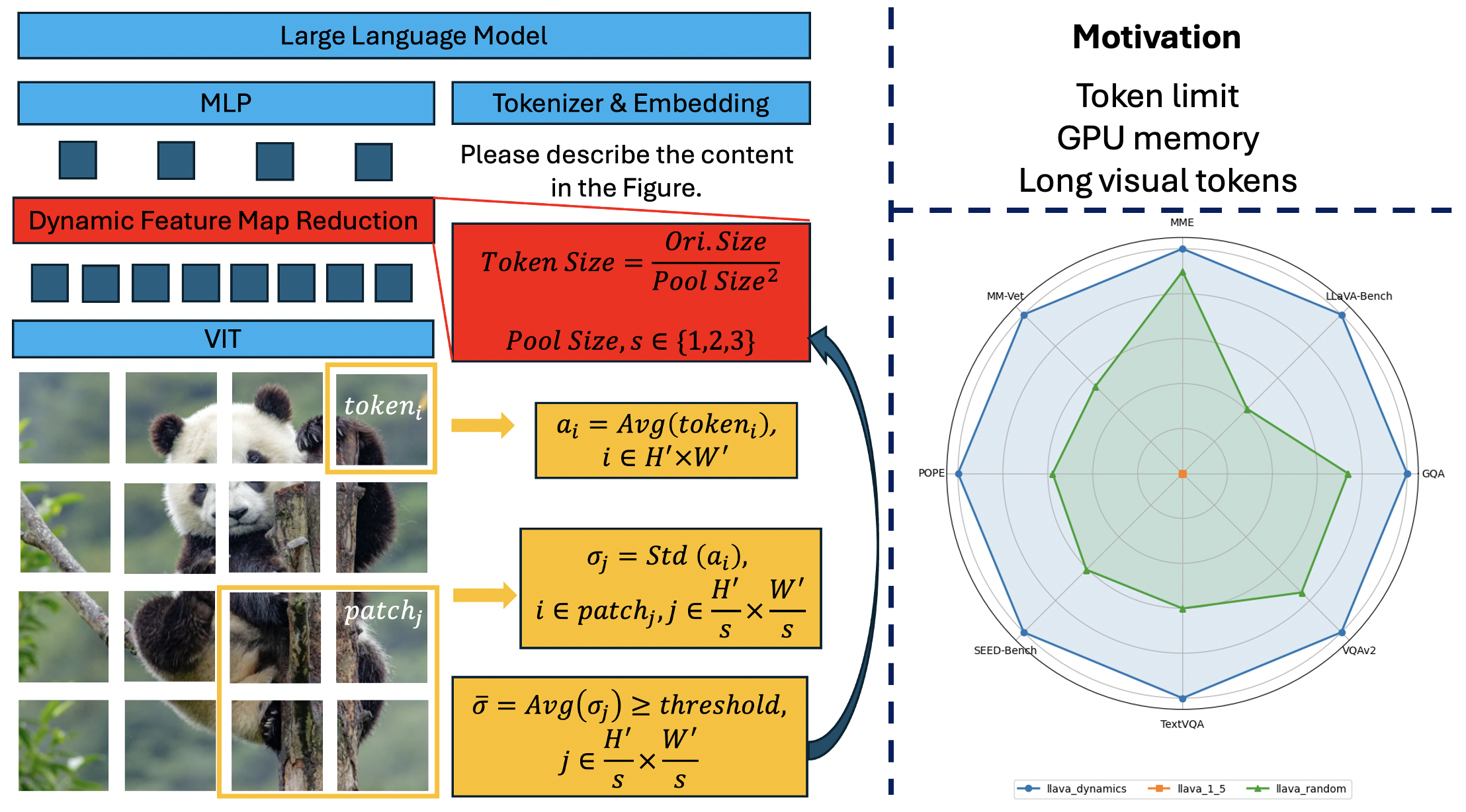
技术框架:该方法基于LLaVA-1.5模型,并在其基础上引入了动态特征图缩减(DFMR)模块。DFMR模块位于视觉编码器之后,在视觉特征被转换为Token之前。整体流程为:首先,图像通过视觉编码器提取特征;然后,DFMR模块对特征图进行动态压缩;最后,压缩后的特征图被转换为视觉Token,输入到LLM中进行处理。
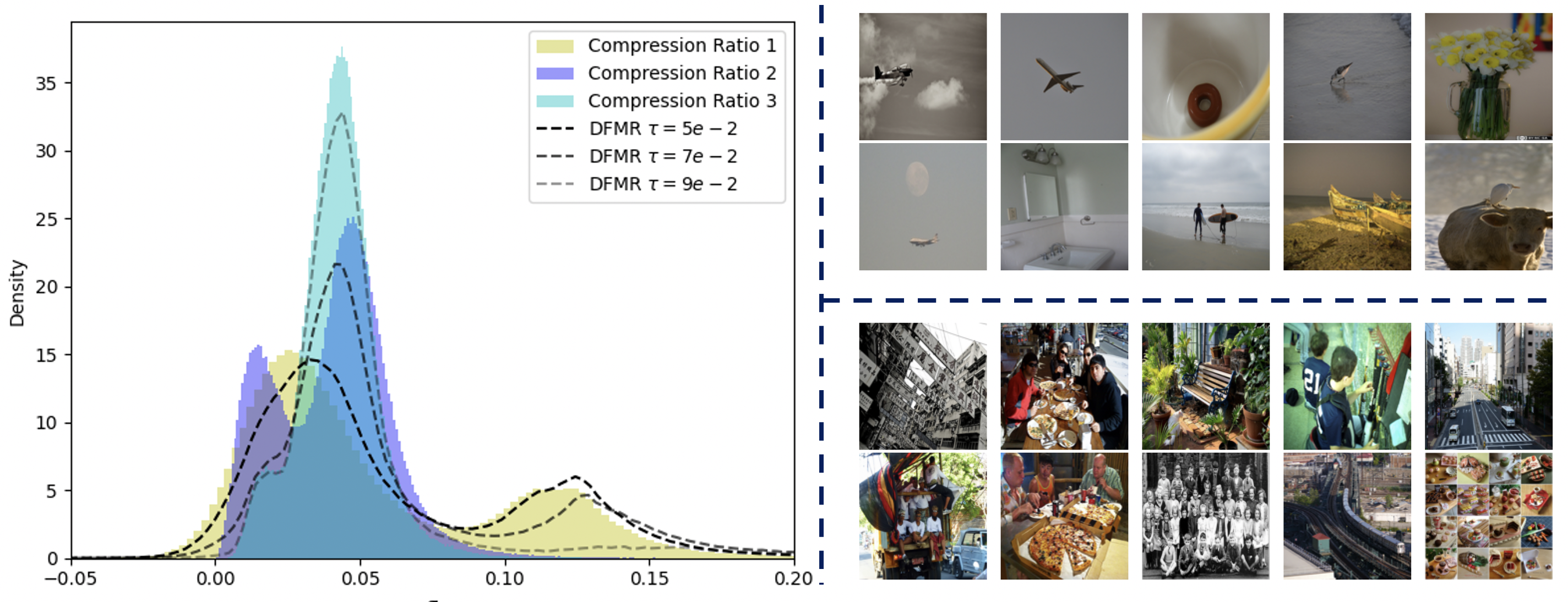
关键创新:该方法最关键的创新在于动态和自适应的视觉Token压缩。传统的视觉Token压缩方法通常采用固定的压缩比例,无法根据图像内容进行调整。而DFMR能够根据图像的内在信息(具体实现未知)来动态地调整压缩比例,从而在保证重要视觉信息不丢失的前提下,尽可能地减少Token数量。
关键设计:具体的技术细节,例如DFMR模块的网络结构、损失函数、以及如何根据图像内在信息调整压缩比例,论文摘要中没有明确说明,属于未知信息。但可以推测,可能涉及到注意力机制或者其他自适应的特征选择方法。
🖼️ 关键图片
📊 实验亮点
实验结果表明,将DFMR集成到LLaVA-1.5中,能够显著提高模型在不同视觉Token长度下的性能。尤其是在处理多图和视频等复杂视觉输入时,该方法能够有效降低计算负担,并提升模型精度。具体的性能提升幅度和对比基线在摘要中未给出,属于未知信息。
🎯 应用场景
该研究成果可应用于多种场景,例如:在资源受限的设备上部署多模态大模型;提升多图/视频问答、视频摘要等任务的性能;通过数据增强缓解开放域图像-文本对数据集的稀缺性。该方法有望推动多模态大模型在学术界和工业界的更广泛应用。
📄 摘要(原文)
Multi-modal large language models (MLLMs) utilizing instruction-following data, such as LLaVA, have achieved great progress in the industry. A major limitation in these models is that visual tokens consume a substantial portion of the maximum token limit in large language models (LLMs), leading to increased computational demands and decreased performance when prompts include multiple images or videos. Industry solutions often mitigate this issue by increasing computational power, but this approach is less feasible in academic environments with limited resources. In this study, we propose Dynamic Feature Map Reduction (DFMR) based on LLaVA-1.5 to address the challenge of visual token overload. DFMR dynamically compresses the visual tokens, freeing up token capacity. Our experimental results demonstrate that integrating DFMR into LLaVA-1.5 significantly improves the performance of LLaVA in varied visual token lengths, offering a promising solution for extending LLaVA to handle multi-image and video scenarios in resource-constrained academic environments and it can also be applied in industry settings for data augmentation to help mitigate the scarcity of open-domain image-text pair datasets in the continued pretraining stage.