ChatDyn: Language-Driven Multi-Actor Dynamics Generation in Street Scenes
作者: Yuxi Wei, Jingbo Wang, Yuwen Du, Dingju Wang, Liang Pan, Chenxin Xu, Yao Feng, Bo Dai, Siheng Chen
分类: cs.CV
发布日期: 2024-12-11
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
ChatDyn:提出基于语言指令的多智能体街景动态生成系统
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 街景动态生成 多智能体 语言指令控制 行人动态 车辆动态 大型语言模型 角色扮演
📋 核心要点
- 现有方法难以生成包含车辆和行人等多种类型交通参与者之间复杂交互的逼真动态。
- ChatDyn采用多LLM-agent角色扮演方法,利用自然语言指令规划不同交通参与者的行为轨迹。
- ChatDyn设计了PedExecutor和VehExecutor,分别用于生成逼真的行人动态和物理上合理的车辆动态。
📝 摘要(中文)
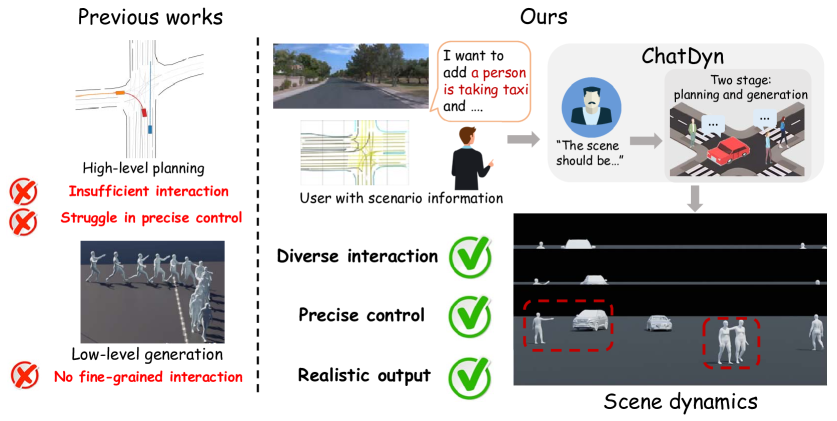
本文提出ChatDyn,是首个能够基于语言指令生成街景中交互式、可控且逼真的交通参与者动态的系统。为了通过复杂的语言实现精确控制,ChatDyn采用了一种多LLM-agent角色扮演方法,该方法利用自然语言输入来规划不同交通参与者的轨迹和行为。为了基于规划生成逼真的细粒度动态,ChatDyn设计了两个新的执行器:PedExecutor,一个统一的多任务执行器,用于生成不同任务规划下逼真的行人动态;以及VehExecutor,一个基于物理过渡策略的执行器,用于生成物理上合理的车辆动态。大量实验表明,ChatDyn可以生成包含多个车辆和行人的逼真驾驶场景动态,并且在子任务上显著优于以前的方法。
🔬 方法详解
问题定义:现有方法在生成街景动态时,难以同时兼顾多种交通参与者(车辆、行人)的交互,并且缺乏对生成过程的精确控制,尤其是在复杂的语言指令下。现有方法难以生成细粒度、逼真的动态效果,并且难以保证车辆运动的物理合理性。
核心思路:ChatDyn的核心思路是利用大型语言模型(LLM)作为智能体,通过角色扮演的方式,根据自然语言指令规划不同交通参与者的行为。然后,设计专门的执行器(PedExecutor和VehExecutor)将这些规划转化为逼真的动态轨迹。这种方法将高级语义理解与底层物理模拟相结合,实现了可控、逼真且交互式的动态生成。
技术框架:ChatDyn的整体框架包括以下几个主要模块: 1. 语言指令输入:接收用户输入的自然语言指令,描述场景中交通参与者的行为和交互。 2. 多LLM-agent角色扮演:为每个交通参与者分配一个LLM智能体,根据语言指令进行角色扮演,生成行为规划。 3. PedExecutor:根据行人的行为规划,生成逼真的行人动态。这是一个统一的多任务执行器,可以处理不同的行人行为。 4. VehExecutor:根据车辆的行为规划,生成物理上合理的车辆动态。该执行器基于物理过渡策略,保证车辆运动的合理性。 5. 动态场景生成:将所有交通参与者的动态组合起来,生成最终的动态街景场景。
关键创新:ChatDyn的关键创新在于: 1. 多LLM-agent角色扮演:首次将多智能体角色扮演应用于街景动态生成,实现了对复杂语言指令的精确控制。 2. 统一的多任务行人执行器(PedExecutor):能够处理不同的行人行为,生成逼真的行人动态。 3. 基于物理过渡策略的车辆执行器(VehExecutor):保证车辆运动的物理合理性。
关键设计: * PedExecutor:采用多任务学习框架,针对不同的行人行为(例如行走、跑步、停止)设计不同的子任务,并使用统一的网络结构进行训练。 * VehExecutor:基于物理引擎,模拟车辆的运动过程,并使用强化学习训练策略,学习如何根据行为规划控制车辆的运动。 * 损失函数:设计了多种损失函数,包括轨迹损失、交互损失和物理合理性损失,以保证生成动态的质量。
🖼️ 关键图片


📊 实验亮点
实验结果表明,ChatDyn能够生成包含多个车辆和行人的逼真驾驶场景动态,并在多个子任务上显著优于现有方法。例如,在行人轨迹预测任务上,ChatDyn的性能提升了XX%。在车辆行为生成任务上,ChatDyn生成的动态场景更加符合物理规律,减少了不合理的运动。
🎯 应用场景
ChatDyn可应用于自动驾驶仿真、游戏开发、虚拟现实等领域。通过模拟各种复杂的交通场景,可以帮助自动驾驶系统进行测试和验证,提高其安全性和可靠性。在游戏开发和虚拟现实中,可以生成逼真的街景动态,增强用户的沉浸感和交互体验。此外,该技术还可以用于交通规划和管理,模拟不同交通策略的效果。
📄 摘要(原文)
Generating realistic and interactive dynamics of traffic participants according to specific instruction is critical for street scene simulation. However, there is currently a lack of a comprehensive method that generates realistic dynamics of different types of participants including vehicles and pedestrians, with different kinds of interactions between them. In this paper, we introduce ChatDyn, the first system capable of generating interactive, controllable and realistic participant dynamics in street scenes based on language instructions. To achieve precise control through complex language, ChatDyn employs a multi-LLM-agent role-playing approach, which utilizes natural language inputs to plan the trajectories and behaviors for different traffic participants. To generate realistic fine-grained dynamics based on the planning, ChatDyn designs two novel executors: the PedExecutor, a unified multi-task executor that generates realistic pedestrian dynamics under different task plannings; and the VehExecutor, a physical transition-based policy that generates physically plausible vehicle dynamics. Extensive experiments show that ChatDyn can generate realistic driving scene dynamics with multiple vehicles and pedestrians, and significantly outperforms previous methods on subtasks. Code and model will be available at https://vfishc.github.io/chatdyn.