EOV-Seg: Efficient Open-Vocabulary Panoptic Segmentation
作者: Hongwei Niu, Jie Hu, Jianghang Lin, Guannan Jiang, Shengchuan Zhang
分类: cs.CV
发布日期: 2024-12-11 (更新: 2024-12-16)
备注: Accepted by AAAI 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出EOV-Seg,一种高效的开放词汇全景分割框架,显著提升推理速度。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 开放词汇全景分割 高效推理 单阶段框架 词汇感知选择 双向动态嵌入 CLIP backbone 空间感知
📋 核心要点
- 现有开放词汇全景分割方法计算开销大,推理效率低,难以满足实际应用需求。
- EOV-Seg通过词汇感知选择模块和双向动态嵌入专家,提升语义理解和空间感知能力,降低计算负担。
- 实验表明,EOV-Seg在速度和性能上均优于现有方法,推理速度提升显著。
📝 摘要(中文)
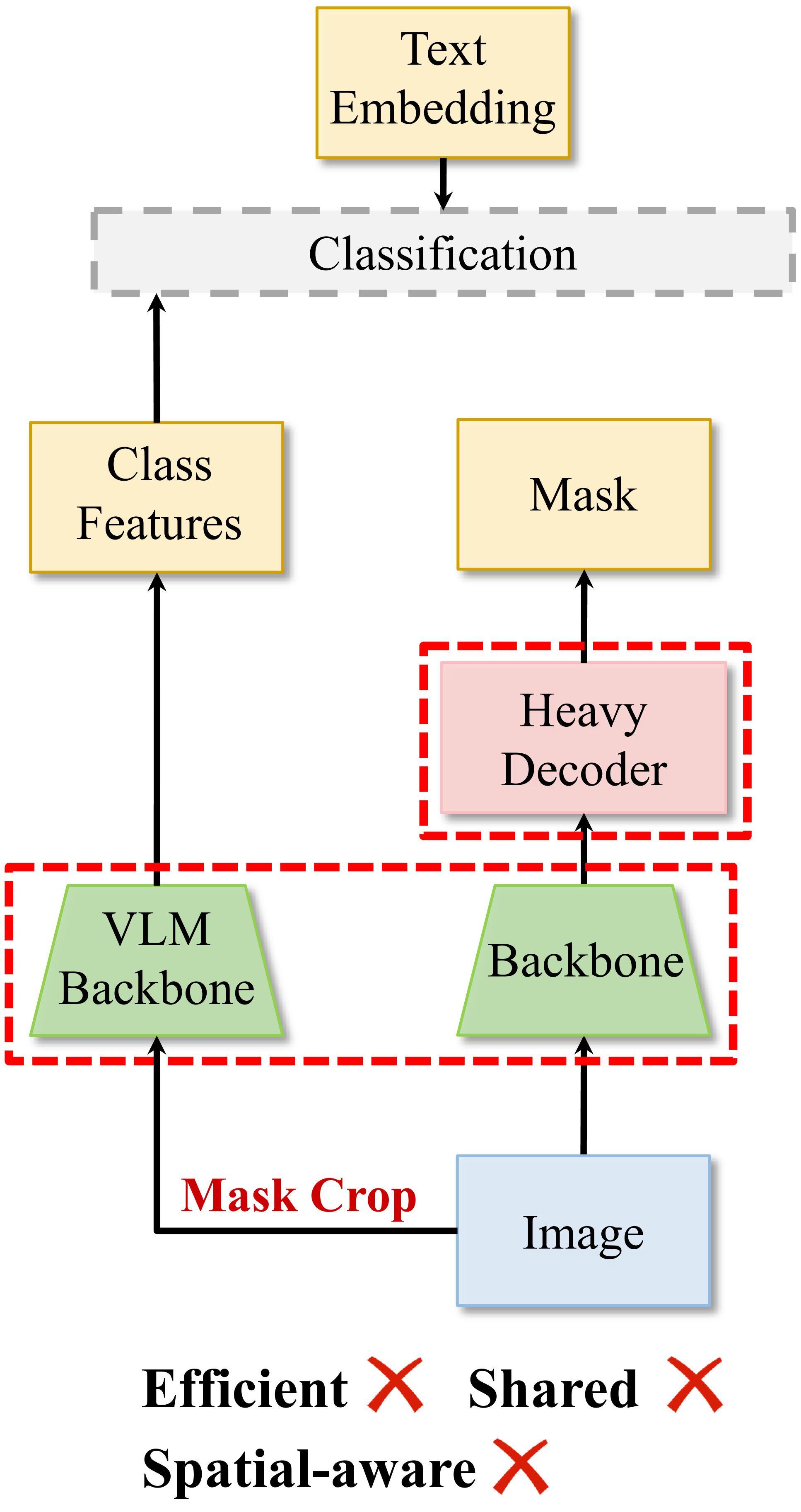
开放词汇全景分割旨在对不同场景中的所有事物进行分割和分类,涵盖无限的词汇。现有方法通常采用两阶段或单阶段框架。两阶段框架涉及使用掩码生成器多次裁剪图像,然后进行特征提取;而单阶段框架依赖于重量级的掩码解码器,通过多个堆叠的Transformer块中的自注意力和交叉注意力来弥补空间位置信息的不足。这两种方法都会产生大量的计算开销,从而阻碍了模型推理的效率。为了填补效率方面的空白,我们提出了EOV-Seg,一种新颖的单阶段、共享、高效且具有空间感知能力的开放词汇全景分割框架。具体来说,EOV-Seg在两个方面进行了创新。首先,提出了一个词汇感知选择(VAS)模块,以提高视觉聚合特征的语义理解,并减轻掩码解码器的特征交互负担。其次,我们引入了一个双向动态嵌入专家(TDEE),它有效地利用了基于ViT的CLIP主干网络的空间感知能力。据我们所知,EOV-Seg是第一个面向效率的开放词汇全景分割框架,与最先进的方法相比,它运行速度更快,并实现了具有竞争力的性能。具体来说,仅使用COCO进行训练,EOV-Seg在ADE20K数据集上实现了24.5 PQ、32.1 mIoU和11.6 FPS,并且EOV-Seg的推理时间比最先进的方法快4-19倍。特别是,配备ResNet50主干网络,EOV-Seg在单个RTX 3090 GPU上以仅71M的参数运行23.8 FPS。代码可在https://github.com/nhw649/EOV-Seg上找到。
🔬 方法详解
问题定义:开放词汇全景分割旨在对图像中的所有像素进行分类和分割,并将其分配到预定义的类别或开放词汇表中。现有方法,无论是两阶段还是单阶段,都存在计算效率低下的问题。两阶段方法需要多次裁剪图像,而单阶段方法则依赖于复杂的Transformer结构进行特征提取和融合,导致计算量巨大,难以实现快速推理。
核心思路:EOV-Seg的核心思路是设计一个高效的单阶段框架,该框架能够充分利用视觉特征的语义信息和空间信息,同时避免使用复杂的注意力机制。通过词汇感知选择模块(VAS)增强特征的语义表达,并通过双向动态嵌入专家(TDEE)有效利用ViT-based CLIP backbone的空间感知能力,从而在保证分割精度的前提下,显著提高推理速度。
技术框架:EOV-Seg采用单阶段架构,主要包含以下模块:1) ViT-based CLIP backbone:用于提取图像的视觉特征;2) 词汇感知选择模块(VAS):用于融合视觉特征和词汇信息,增强特征的语义表达;3) 双向动态嵌入专家(TDEE):用于利用CLIP backbone的空间感知能力,生成高质量的掩码预测;4) 掩码解码器:用于解码特征并生成最终的全景分割结果。
关键创新:EOV-Seg的关键创新在于:1) 提出了词汇感知选择模块(VAS),该模块能够有效地融合视觉特征和词汇信息,提高特征的语义表达能力,减轻了掩码解码器的负担;2) 提出了双向动态嵌入专家(TDEE),该模块能够充分利用ViT-based CLIP backbone的空间感知能力,生成高质量的掩码预测,避免了使用复杂的注意力机制。
关键设计:VAS模块的设计关键在于如何有效地融合视觉特征和词汇信息。TDEE模块的关键在于如何利用CLIP backbone的空间感知能力,并将其转化为高质量的掩码预测。具体的参数设置、损失函数和网络结构等技术细节在论文中有详细描述,例如,使用了交叉熵损失函数来优化分割结果,并对网络结构进行了精细调整以提高效率。
🖼️ 关键图片


📊 实验亮点
EOV-Seg在ADE20K数据集上取得了显著的性能提升,仅使用COCO数据集进行训练,就达到了24.5 PQ和32.1 mIoU。更重要的是,EOV-Seg的推理速度比现有最先进的方法快4-19倍,配备ResNet50主干网络时,在单个RTX 3090 GPU上可以达到23.8 FPS,参数量仅为71M。
🎯 应用场景
EOV-Seg可应用于自动驾驶、机器人导航、智能监控等领域,实现对复杂场景的全面理解和分析。其高效的推理速度使其能够部署在资源受限的设备上,例如移动机器人和嵌入式系统。未来,该技术有望推动智能设备在更广泛的应用场景中实现更高级的感知能力。
📄 摘要(原文)
Open-vocabulary panoptic segmentation aims to segment and classify everything in diverse scenes across an unbounded vocabulary. Existing methods typically employ two-stage or single-stage framework. The two-stage framework involves cropping the image multiple times using masks generated by a mask generator, followed by feature extraction, while the single-stage framework relies on a heavyweight mask decoder to make up for the lack of spatial position information through self-attention and cross-attention in multiple stacked Transformer blocks. Both methods incur substantial computational overhead, thereby hindering the efficiency of model inference. To fill the gap in efficiency, we propose EOV-Seg, a novel single-stage, shared, efficient, and spatialaware framework designed for open-vocabulary panoptic segmentation. Specifically, EOV-Seg innovates in two aspects. First, a Vocabulary-Aware Selection (VAS) module is proposed to improve the semantic comprehension of visual aggregated features and alleviate the feature interaction burden on the mask decoder. Second, we introduce a Two-way Dynamic Embedding Experts (TDEE), which efficiently utilizes the spatial awareness capabilities of ViT-based CLIP backbone. To the best of our knowledge, EOV-Seg is the first open-vocabulary panoptic segmentation framework towards efficiency, which runs faster and achieves competitive performance compared with state-of-the-art methods. Specifically, with COCO training only, EOV-Seg achieves 24.5 PQ, 32.1 mIoU, and 11.6 FPS on the ADE20K dataset and the inference time of EOV-Seg is 4-19 times faster than state-of-theart methods. Especially, equipped with ResNet50 backbone, EOV-Seg runs 23.8 FPS with only 71M parameters on a single RTX 3090 GPU. Code is available at https://github.com/nhw649/EOV-Seg.